AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文作者来自上海交通大学,清华大学,剑桥大学和上海人工智能实验室。一作陈哲为上海交通大学博一学生,师从上海交通大学人工智能学院王钰教授。通讯作者为王钰教授(主页:https://yuwangsjtu.github.io/)与清华大学电子工程系张超教授(主页:https://mi.eng.cam.ac.uk/~cz277)。
- 论文链接:https://arxiv.org/abs/2403.14168
- 项目主页:https://jack-zc8.github.io/M3AV-dataset-page/
- 论文标题:M3AV: A Multimodal, Multigenre, and Multipurpose Audio-Visual Academic Lecture Dataset
开源学术演讲录像是一种普遍流行的在线分享学术知识的方法。这些视频包含丰富的多模态信息,包括演讲者的语音、面部表情和身体动作,幻灯片中的文本和图片,和对应的论文文本信息。目前很少有数据集能够同时支持多模态内容识别和理解任务,部分原因是缺乏高质量的人工标注。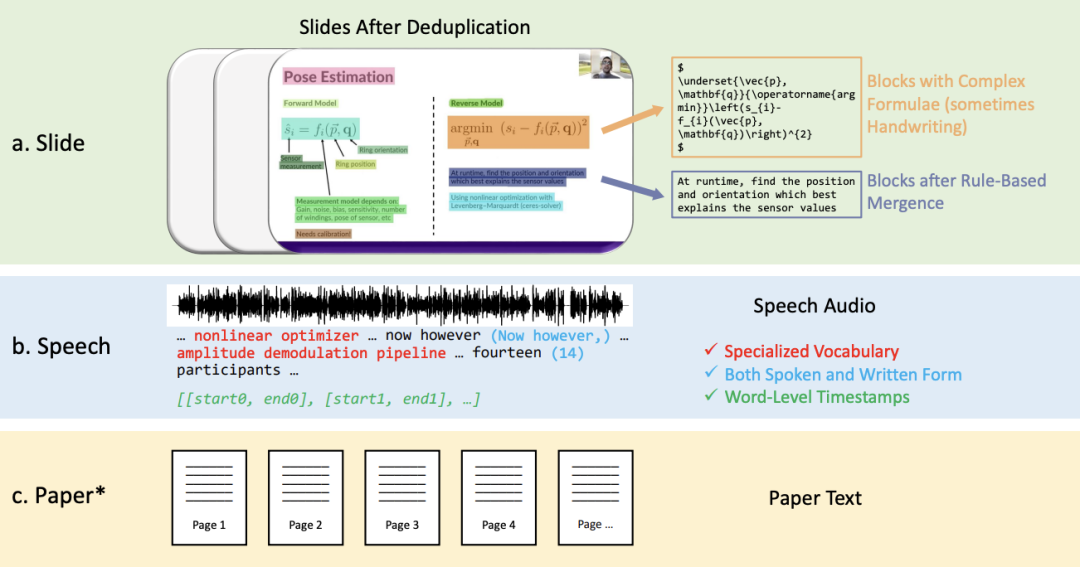
该工作提出了一个新的多模态、多类型、多用途的视听学术演讲数据集(M3AV),它包含来自五个来源的近 367 小时的视频,涵盖计算机科学、数学、医学和生物学主题。凭借高质量的人工标注,特别是高价值的命名实体,数据集可以用于多种视听识别和理解任务。在上下文语音识别、语音合成以及幻灯片和脚本生成任务上进行的评估表明,M3AV 的多样性使其成为一个具有挑战性的数据集。目前该工作已被 ACL 2024 主会接收。1. 带有复杂块的幻灯片,它们将会被按照空间位置关系进行合并。2. 口语和书面形式的,包含特殊词汇以及单词级时间戳的语音转写文本。从下表可以看出,M3AV 数据集包含最多人工标注的幻灯片、语音和论文资源,因此不仅支持多模态内容的识别任务,还支持高级学术知识的理解任务。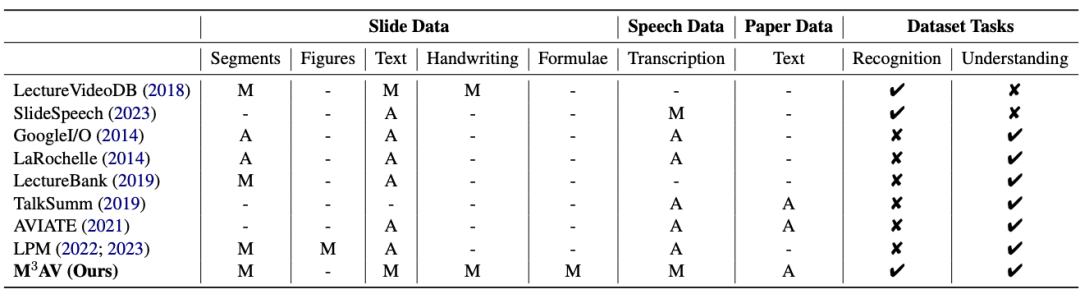
同时,M3AV 数据集在各方面与其他学术数据集相比,内容较为丰富,同时也是可访问的资源。
M3AV 数据集在多模态感知与理解方面设计了三个任务,分别是基于上下文的语音识别、自发风格的语音合成、幻灯片与脚本生成。一般的端到端模型在稀有词识别上存在问题。从下表的 AED 和 RNN-T 模型可以看出,稀有词词错率(BWER)与全部词错率(WER)相比,增加了两倍以上。通过使用 TCPGen 利用 OCR 信息来进行基于上下文的语音识别,RNN-T 模型在开发和测试集上的 BWER 分别有相对 37.8% 和 34.2% 的降低。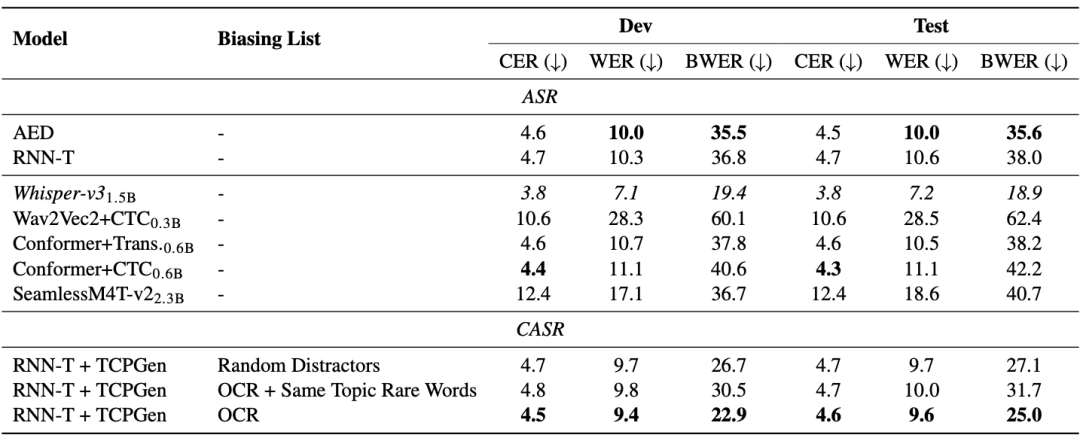
自发风格的语音合成系统迫切地需求真实场景下的语音数据,以产生更接近自然会话模式的语音。论文作者引入了 MQTTS 作为实验模型,可以发现与各个预训练模型相比,MQTTS 的各项评估指标最佳。这表明 M3AV 数据集中的真实语音可以驱动 AI 系统模拟出更自然的语音。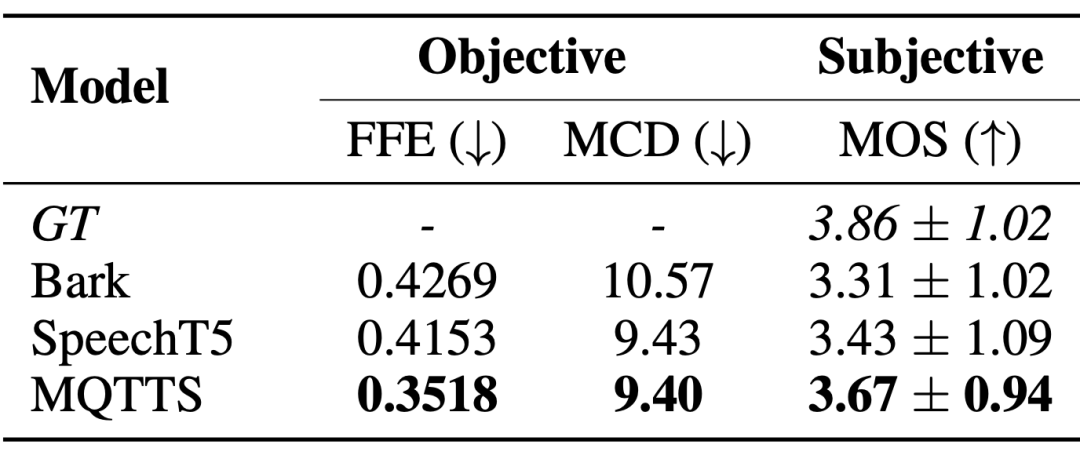
幻灯片和脚本生成(SSG)任务旨在促进 AI 模型理解和重建先进的学术知识,从而帮助研究人员处理快速更新迭代的学术资料,有效地开展学术研究。从下表可以看出,开源模型(LLaMA-2, InstructBLIP)在从 7B 提升到 13B 时,性能提升有限,落后于闭源模型(GPT-4 和 GPT-4V)。因此,除了提升模型尺寸,论文作者认为还需要有高质量的多模态预训练数据。值得注意的是,先进的多模态大模型(GPT-4V)已经超过了由多个单模态模型组成的级联模型。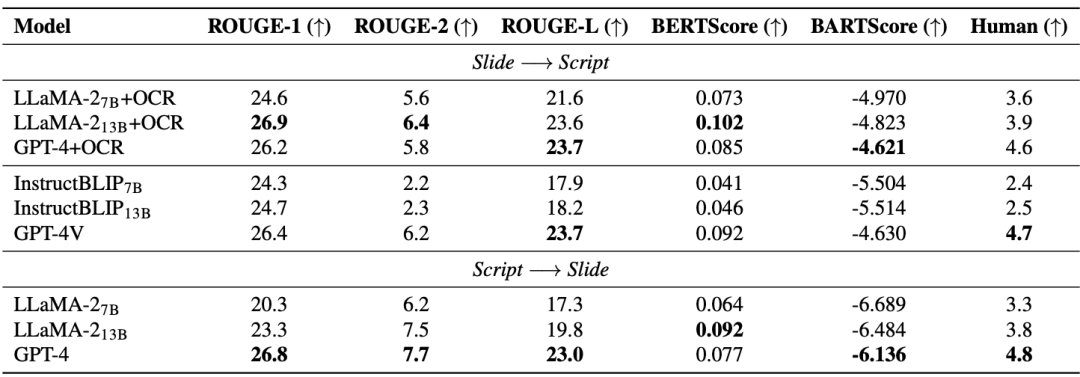
此外,检索增强生成(RAG)有效提升了模型性能:下表显示,引入的论文文本同时提升了生成的幻灯片与脚本的质量。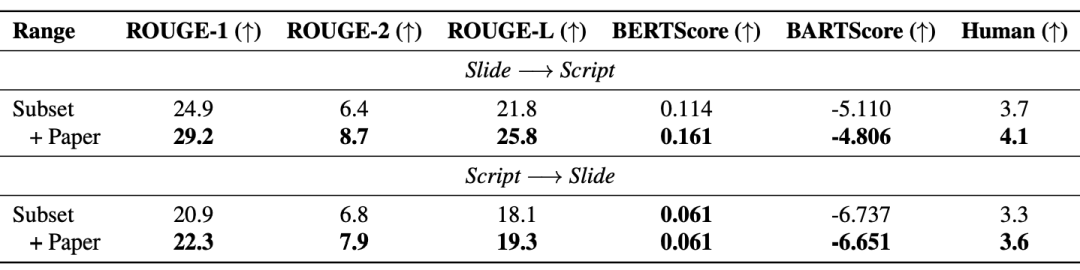
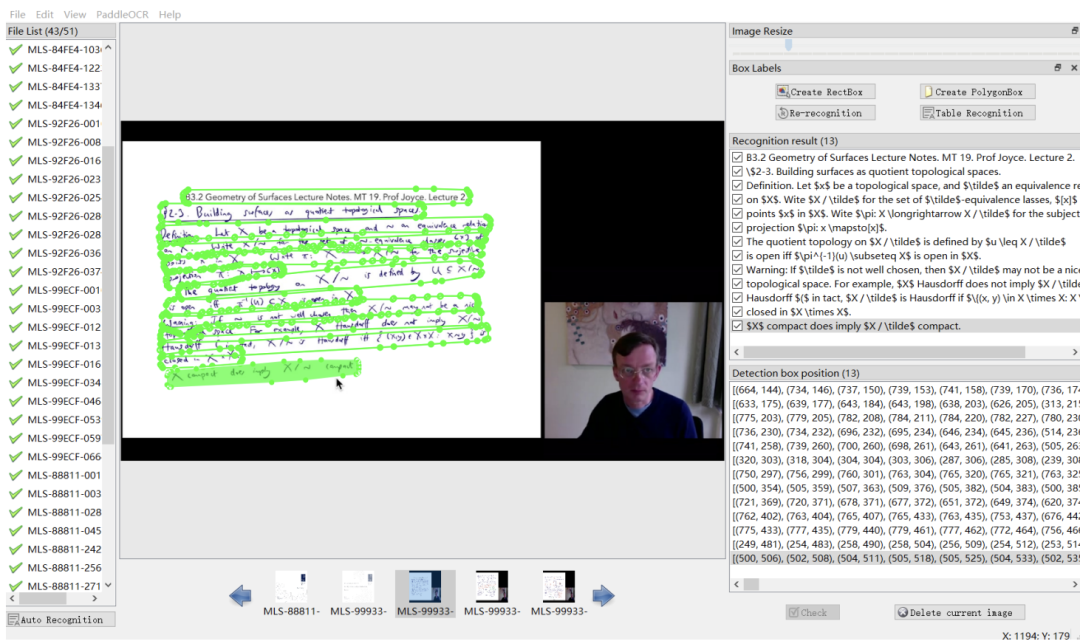
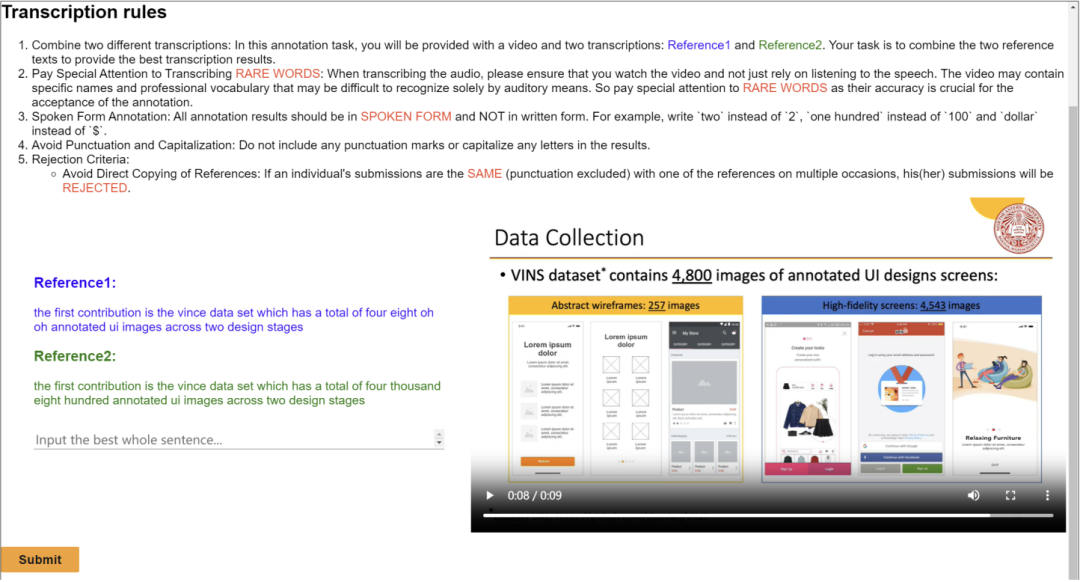
这篇工作发布了涵盖多个学术领域的多模态、多类型、多用途视听数据集(M3AV)。该数据集包含人工标注的语音转录、幻灯片和额外提取的论文文本,为评估 AI 模型识别多模态内容和理解学术知识的能力提供了基础。论文作者详细介绍了创建流程,并对该数据集进行了各种分析。此外,他们构建了基准并围绕数据集进行了多项实验。最终,论文作者发现现有的模型在感知和理解学术演讲视频方面仍有较大的提升空间。部分标注界面
以上是ACL 2024 | 引领学术视听研究,上海交大、清华大学、剑桥大学、上海AILAB联合发布学术视听数据集M3AV的详细内容。更多信息请关注PHP中文网其他相关文章!























