核心概念
- 主键索引/辅助索引
- 聚集索引/非聚集索引
- 表查找/索引覆盖
- 索引下推
- 复合索引/最左边前缀匹配
- 前缀索引
- 解释一下
1.【指标定义】
1。索引定义
除了数据本身之外,数据库系统还维护满足特定搜索算法的数据结构。这些结构以某种方式引用(指向)数据,允许在它们上实现高级搜索算法。 这些数据结构就是索引。
2。索引的数据结构
- B-tree / B+ 树(MySQL 的 InnoDB 引擎使用 B+ 树作为默认索引结构)
- 哈希表
- 排序数组
3。为什么选择 B+ 树而不是 B 树

- 假设数据大小为 1KB,索引大小为 16B,数据库使用磁盘数据页,默认磁盘页大小为 16K,相同的三个 I/O 操作将产生:
B 树可以获取 16*16*16=4096 条记录。
B+树可以获取1000*1000*1000=10亿条记录。
2.【索引类型】
1。主键索引和辅助索引
-
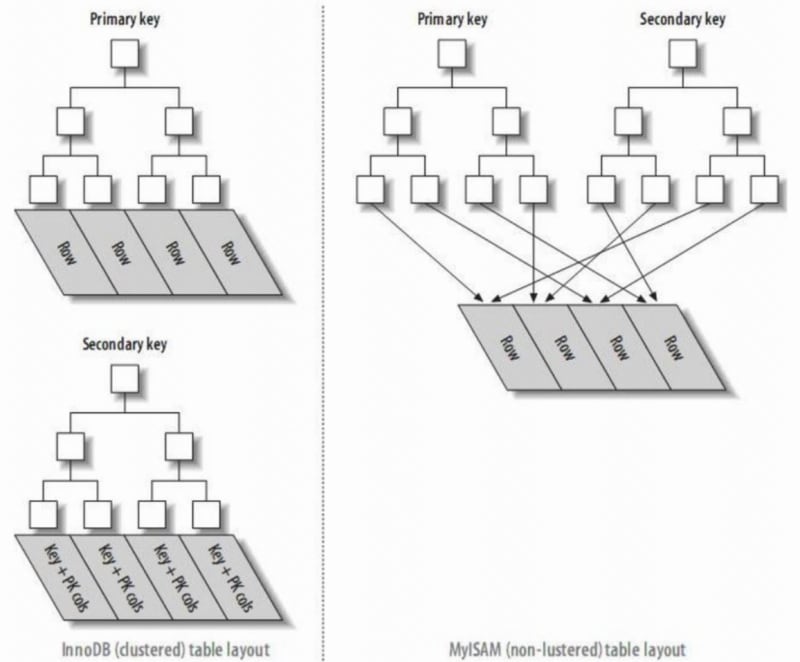
主键索引:索引的叶子节点是数据行。
-
辅助索引:索引的叶子节点是KEY字段加上主键索引。因此,通过二级索引查询时,首先找到主键值,然后InnoDB通过主键索引找到对应的数据块。
-
在InnoDB中,主索引文件直接存储数据行,称为聚集索引,而二级索引则指向主键引用。
-
在MyISAM中,主索引和辅助索引都指向物理行(磁盘位置)。
2。聚集索引和非聚集索引
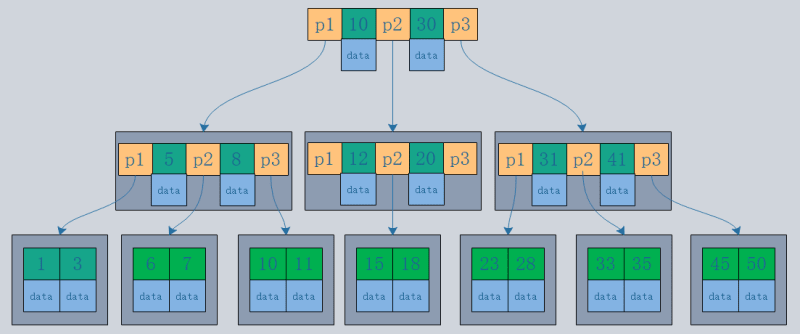
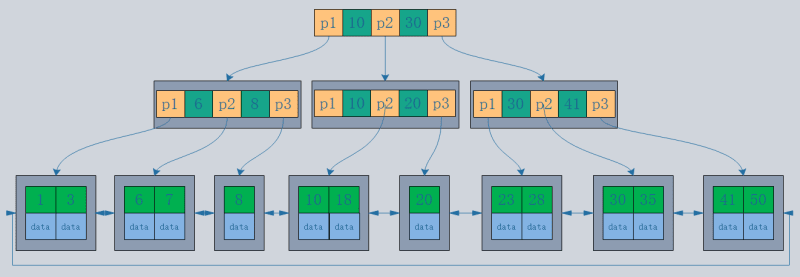
- 聚集索引重新组织磁盘上的实际数据,并按一个或多个指定的列值进行排序。特点是数据的存储顺序和索引顺序一致。一般主键会默认创建聚集索引,一张表只允许有一个聚集索引(原因:数据只能按一种顺序存储)。如图所示,InnoDB的主索引和辅助索引都是聚集索引。
- 与作为数据记录的聚集索引的叶节点相比,非聚集索引的叶节点是指向数据记录的指针。最大的区别是数据记录的顺序与索引顺序不匹配。
3。聚集索引的优点和缺点
- 优点:通过主键查询条目时,不需要查表(数据在主键节点下)。
- 缺点:不规则的数据插入会导致频繁的分页。
3.【扩展索引概念】
1。查表
查表的概念涉及到主键索引查询和非主键索引查询的区别。
- 如果查询是select * from T where ID=500,主键查询只需要查找ID树即可。
- 如果查询是select * from T where k=5,则非主键索引查询需要先查找k索引树得到ID值500,然后再次查找ID索引树。
- 从非主键索引移回主键索引的过程称为查表。
基于非主键索引的查询需要扫描额外的索引树。因此,我们应该在应用中尽量使用主键查询。从存储空间的角度来看,由于非主键索引树的叶子节点存储主键值,建议主键字段尽可能短。这样,非主键索引树的叶子节点就更小,非主键索引占用的空间也更少。一般情况下,建议创建自增主键,以尽量减少非主键索引占用的空间。
2。索引覆盖
- 如果WHERE子句条件是非主键索引,则查询会首先通过非主键索引定位到主键索引(主键位于非主键索引的叶子节点)主键索引搜索树),然后通过主键索引定位查询内容。在这个过程中,回到主键索引树就称为查表。
- 但是,当我们的查询内容是主键值时,我们可以直接提供查询结果,无需查表。也就是说,本次查询中非主键索引已经“覆盖”了我们的查询需求,因此称为覆盖索引。
-
覆盖索引可以直接从辅助索引获取查询结果,无需到主索引进行查表,从而减少搜索次数(不需要从辅助索引树移动到聚集索引树)或减少IO操作(辅助索引树可以一次从磁盘加载更多节点),从而提高性能。
3。综合指数
复合索引是指对表的多个列进行索引。
场景 1:
复合索引(a, b) 按a, b排序(先按a排序,如果a相同则按b排序)。因此,下面的语句可以直接使用复合索引来获取结果(其实就是利用了最左前缀原则):
- 从 xxx 中选择…,其中 a=xxx;
- 从 xxx 中选择…,其中 a=xxx 按 b 排序;
以下语句不能使用复合查询:
场景 2:
对于复合索引(a,b,c),以下语句可以直接通过复合索引获取结果:
- 从 xxx 中选择…,其中 a=xxx 按 b 排序;
- 从 xxx 中选择…,其中 a=xxx 和 b=xxx 按 c 排序;
以下语句不能使用复合索引,需要进行文件排序操作:
- 从 xxx 中选择 …,其中 a=xxx 按 c 排序;
摘要:
以复合索引(a、b、c)为例,创建这样的索引相当于创建索引a、ab、abc。用一个索引代替三个索引肯定是有好处的,因为每个额外的索引都会增加写入操作的开销和磁盘空间的使用。
4。最左前缀原则
- 从上面的复合索引例子,我们可以了解最左前缀原理。
-
不仅仅是索引的完整定义,只要满足最左边的前缀,就可以用来加速检索。这个最左前缀可以是复合索引最左边的N个字段,也可以是字符串索引最左边的M个字符。利用索引的“最左前缀”原则来定位记录,避免冗余的索引定义。
- 因此,基于最左前缀原则,定义复合索引时考虑索引内的字段顺序至关重要!评价标准是索引的可重用性。例如当(a,b)上已经有索引时,一般不需要在a上单独创建索引
5。索引下推
MySQL 5.6引入了索引下推优化,索引遍历时可以根据索引包含的字段过滤掉不符合条件的记录,减少查表次数。
CREATE TABLE `test` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'Auto-increment primary key',
`age` int(11) NOT NULL DEFAULT '0',
`name` varchar(255) CHARACTER SET utf8 NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_name_age` (`name`,`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
登录后复制
-
SELECT * from user where name like 'Chen%' 最左前缀原则,命中 idx_name_age 索引
-
从名称如“Chen%”且年龄=20 的用户中选择 *
- 5.6版本之前,首先会根据姓名索引匹配2条记录(此时忽略age=20的条件),找到对应的2个ID,进行查表,然后根据age=20进行过滤。
- 5.6版本之后,引入了索引下推。根据姓名匹配2条记录后,在进行查表之前不会忽略age=20的条件,在查表之前根据年龄进行过滤。这种索引下推可以减少查表次数,提高查询性能。
6。前缀索引
当索引是一个长字符序列时,它会占用大量内存并且速度很慢。在这种情况下,可以使用前缀索引。我们不是对整个值进行索引,而是对前几个字符进行索引,以节省空间并获得良好的性能。 前缀索引使用索引的前几个字母。但是,为了降低索引重复率,我们必须评估前缀索引的唯一性。
- 首先计算当前字符串字段的唯一性比例:select 1.0*count(distinct name)/count(*) from test
- 然后,计算不同前缀的唯一性比率:
-
从测试中选择 1.0*count(distinct left(name,1))/count(*) 作为名称的第一个字符作为前缀索引
-
从测试中选择 1.0*count(distinct left(name,2))/count(*) 作为名称的前两个字符作为前缀索引
- ...
- 当 left(str, n) 没有显着增加时,选择 n 作为前缀索引截止值。
- 创建索引 alter table test add key(name(n));
4. [查看索引]
添加索引后,我们如何查看索引呢?或者,如果语句执行速度很慢,我们如何排除故障?
Explain 通常用于检查索引是否有效。
获取慢查询日志后,观察哪些语句是慢的。在语句前添加explain并再次执行。 Explain 在查询上设置一个标志,使其返回执行计划中每个步骤的信息,而不是执行语句。它返回一行或多行信息,显示执行计划的每个部分和执行情况订购。
解释返回的重要字段:
-
type:显示搜索方式(全表扫描或索引扫描)
- key:使用的索引字段,不使用则为null
解释的类型字段:
- ALL:全表扫描
- 索引:完整索引扫描
- 范围:索引范围扫描
- ref:非唯一索引扫描
- eq_ref:唯一索引扫描
以上是Mysql数据库索引初学者详解的详细内容。更多信息请关注PHP中文网其他相关文章!