AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。
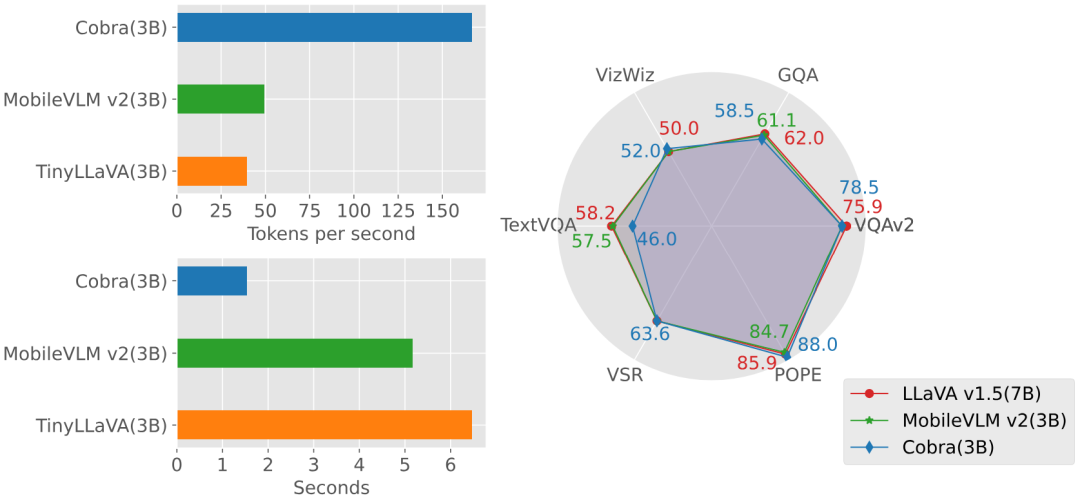
近年来,多模态大型语言模型(MLLM)在各个领域的应用取得了显着的成功。然而,作为许多下游任务的基础模型,当前的 MLLM 由众所周知的 Transformer 网络构成,这种网络具有较低效的二次计算复杂度。为了提高这类基础模型的效率,大量的实验表明:(1)Cobra 与当前计算效率高的最先进方法(例如,LLaVA-Phi,TinyLLaVA 和MobileVLM v2)具有极具竞争力的性能,并且由于Cobra的线性序列建模,其速度更快。 (2)有趣的是,封闭集挑战性预测基准的结果显示,Cobra 在克服视觉错觉和空间关系判断方面表现良好。 (3)值得注意的是,Cobra 甚至在参数数量只有 LLaVA 的 43% 左右的情况下,也取得了与 LLaVA 相当的性能。 大语言模型(LLMs)受限于仅通过语言进行交互,限制了它们处理更多样化任务的适应性。多模态理解对于增强模型有效应对现实世界挑战的能力至关重要。因此,研究人员正在积极努力扩展大型语言模型,以纳入多模态信息处理能力。视觉 - 语言模型(VLMs)如 GPT-4、LLaMA-Adapter 和 LLaVA 已经被开发出来,以增强 LLMs 的视觉理解能力。 然而,先前的研究主要尝试以类似的方法获得高效的 VLMs,即在保持基于注意力的 Transformer 结构不变的情况下减少基础语言模型的参数或视觉 token 的数量。本文提出了一个不同的视角:直接采用状态空间模型(SSM)作为骨干网络,得到了一种线性计算复杂度的 MLLM。此外,本文还探索和研究了各种模态融合方案,以创建一个有效的多模态 Mamba。具体来说,本文采用 Mamba 语言模型作为 VLM 的基础模型,它已经显示出可以与 Transformer 语言模型竞争的性能,但推理效率更高。测试显示 Cobra 的推理性能比同参数量级的 MobileVLM v2 3B 和 TinyLLaVA 3B 快 3 倍至 4 倍。即使与参数数量更多的 LLaVA v1.5 模型(7B 参数)相比,Cobra 仍然可以在参数数量约为其 43% 的情况下在几个基准测试上实现可以匹配的性能。
图Cobra 和LLaVA v1.5 7B 在生成速度上的Demo
- 调查了现有的多模态大型语言模型(MLLMs)通常依赖于Transformer 网络,这表现出二次方的计算复杂度。为了解决这种低效问题,本文引入了 Cobra,一个新颖的具有线性计算复杂度的 MLLM。
- 深入探讨了各种模态融合方案,以优化 Mamba 语言模型中视觉和语言信息的整合。通过实验,本文探索了不同融合策略的有效性,确定了产生最有效多模态表示的方法。
- 进行了广泛的实验,评估 Cobra 与旨在提高基础 MLLM 计算效率的并行研究的性能。值得注意的是,Cobra 甚至在参数更少的情况下实现了与 LLaVA 相当的性能,突显了其效率。
- 원본 링크: https://arxiv.org/pdf/2403.14520v2.pdf
- 프로젝트 링크: https://sites.google.com/view/cobravlm/
- 논문 제목: Cobra: 효율적인 추론을 위해 Mamba를 다중 모달 대형 언어 모델로 확장
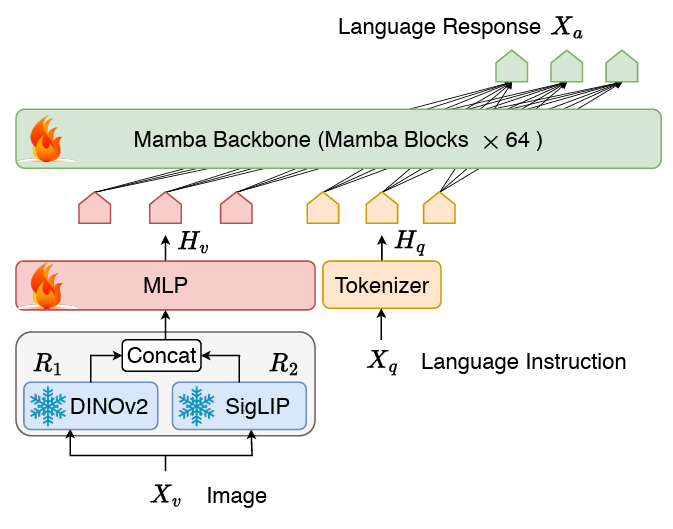
Cobra는 클래식 시각적 인코더를 사용하여 두 모델을 연결합니다. LM 구조 상태 저장 프로젝터와 LLM 언어 백본으로 구성됩니다. LLM의 백본 부분은 600B 토큰으로 SlimPajama 데이터 세트에서 사전 훈련되고 대화 데이터의 지침으로 미세 조정된 2.8B 매개변수 사전 훈련된 Mamba 언어 모델을 사용합니다.网络 Cobra 네트워크 구조 다이어그램
COBRA는 LLAVA 등과는 달리 Dinov2 및 SIGLIP 융합의 시각적 표현을 사용합니다. 두 개의 시각적 코더의 출력을 함께 연결하여 모델이 더 잘 캡처할 수 있습니다. SigLIP에서 가져온 높은 수준의 의미론적 기능과 DINOv2에서 추출한 낮은 수준의 세분화된 이미지 기능입니다. 훈련 계획
최근 연구에 따르면 LLaVA를 기반으로 하는 기존 훈련 패러다임의 경우(예: 투영 계층의 사전 정렬 단계와 LLM 백본의 미세 조정 단계만 한 번 훈련함) 각각) 사전 정렬 단계가 불필요할 수 있으며 미세 조정된 모델이 여전히 과소적합될 수 있습니다. 따라서 Cobra는 사전 정렬 단계를 포기하고 전체 LLM 언어 백본과 프로젝터를 직접 미세 조정합니다. 이 미세 조정 프로세스는 다음으로 구성된 결합된 데이터 세트에서 무작위 샘플링을 사용하여 두 에포크 동안 수행되었습니다. LLaVA v1.5에서 사용된 하이브리드 데이터 세트에는 학술을 포함하여 총 655,000개의 시각적 다단계 대화가 포함되어 있습니다. VQA 샘플, LLaVA-Instruct의 시각적 명령 튜닝 데이터 및 ShareGPT의 일반 텍스트 명령 튜닝 데이터. LVIS-Instruct-4V에는 GPT-4V에서 생성된 시각적 정렬 및 상황 인식 지침이 포함된 220K 이미지가 포함되어 있습니다.
-
LRV-Instruct는 환각 현상 완화를 목표로 하는 16가지 시각적 언어 작업을 다루는 400K 시각적 지침이 포함된 데이터 세트입니다.
- 전체 데이터 세트에는 약 120만 개의 이미지와 해당하는 여러 라운드의 대화 데이터 및 일반 텍스트 대화 데이터가 포함되어 있습니다.
Experiment
실험 부분에서는 기본 벤치마크에서 제안한 Cobra 모델과 오픈 소스 SOTA VLM 모델을 비교하고, 동일 크기는 Transformer 아키텍처 기반 VLM 모델의 응답 속도를 기반으로 합니다. 동시에 그래프의 생성 속도와 성능 비교를 통해 COBRA는 VQA-V2, GQA, Vizwiz, TextVQA 및 VSR의 4가지 개방형 VQA 작업, POPE 2개 폐쇄 세트 예측 작업에 대해 , 점수는 총 6개의 벤치마크에서 비교되었습니다. 벤치마크와 기타 오픈 소스 모델의 지도 비교 정성 테스트
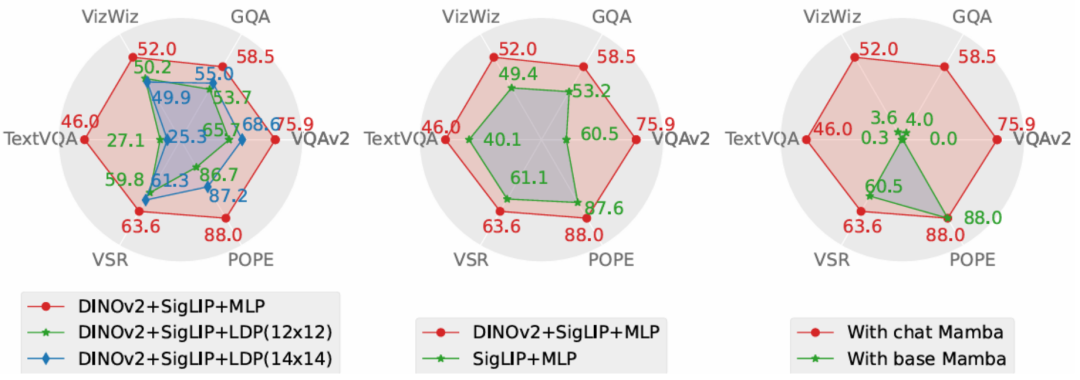
또한 Cobra는 객체의 Cobra를 정성적으로 설명하기 위해 두 가지 VQA 예제도 제공합니다. 공간 관계를 인식하고 모델 환상을 줄이는 능력이 우수합니다.和 객체 공간 관계를 판단하는 COBRA 및 기타 기본 모델을 그림 图Cobra 和其他基线模型在关于视觉错觉现象的示例在示例中,LLaVA v1.5 和MobileVLM 均给出了错误答案,而Cobra 则在两个问题上都做出了准确的描述,尤其在第二个实例中,Cobra 准确的识别出了图片是来自于机器人的仿真环境。 本文从性能和生成速度这两个维度对 Cobra 采取的方案进行了消融研究。实验方案分别对投影器、视觉编码器、LLM 语言主干进行了消融实验。
投影器部分的消融实验结果显示,本文采取的MLP 投影器在效果上显着优于致力于减少视觉token 数量以提升运算速度的LDP 模块,同时,由于Cobra 处理序列的速度和运算复杂度均优于Transformer,在生成速度上LDP 模块并没有明显优势,因此在Mamba 类模型中使用通过牺牲精度减少视觉token 数量的采样器可能是不必要的。
视觉编码器部分的消融结果表明,DINOv2 特征的融合有效的提升了 Cobra 的性能。而在语言主干的实验中,未经过指令微调的 Mamba 语言模型在开放问答的测试中完全无法给出合理的答案,而经过微调的 Mamba 语言模型则可以在各类任务上达到可观的表现。 本文提出了 Cobra,它解决了现有依赖于具有二次计算复杂度的 Transformer 网络的多模态大型语言模型的效率瓶颈。本文探索了具有线性计算复杂度的语言模型与多模态输入的结合。在融合视觉和语言信息方面,本文通过对不同模态融合方案的深入研究,成功优化了 Mamba 语言模型的内部信息整合,实现了更有效的多模态表征。实验表明,Cobra 不仅显着提高了计算效率,而且在性能上与先进模型如 LLaVA 相当,尤其在克服视觉幻觉和空间关系判断方面表现出色。它甚至显着减少了参数的数量。这为未来在需要高频处理视觉信息的环境中部署高性能 AI 模型,如基于视觉的机器人反馈控制,开辟了新的可能性。 以上是首个基于Mamba的MLLM来了!模型权重、训练代码等已全部开源的详细内容。更多信息请关注PHP中文网其他相关文章!