

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com



 ,并从中抽取一个子集 A⊆C 或使用全部共享词作为锚点词集合 A=C。
,并从中抽取一个子集 A⊆C 或使用全部共享词作为锚点词集合 A=C。 ,DeePEn 计算词表中每个 token 与锚点 token 的嵌入相似度,得到相对表示矩阵
,DeePEn 计算词表中每个 token 与锚点 token 的嵌入相似度,得到相对表示矩阵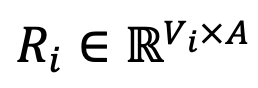 。最后,为了克服离群词的相对表示退化问题,论文作者对相对表示矩阵进行行归一化,通过对矩阵的每一行进行 softmax 操作,得到归一化相对表示矩阵
。最后,为了克服离群词的相对表示退化问题,论文作者对相对表示矩阵进行行归一化,通过对矩阵的每一行进行 softmax 操作,得到归一化相对表示矩阵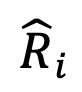 。
。 输出概率分布
输出概率分布 ,DeePEn 使用归一化相对表示矩阵将
,DeePEn 使用归一化相对表示矩阵将 转换为相对表示
转换为相对表示 :
:
 其中
其中 是模型的协作权重。作者尝试了两种确定协作权重值的方法:(1) DeePEn-Avg,对所有模型使用相同的权重;(2) DeePEn-Adapt,根据各个模型的验证集性能成比例地为每个模型设置权重。
是模型的协作权重。作者尝试了两种确定协作权重值的方法:(1) DeePEn-Avg,对所有模型使用相同的权重;(2) DeePEn-Adapt,根据各个模型的验证集性能成比例地为每个模型设置权重。

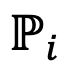 表示模型的绝对空间,
表示模型的绝对空间,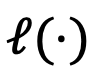 是衡量相对表示之间距离的损失函数(KL 散度)。
是衡量相对表示之间距离的损失函数(KL 散度)。 相对于绝对表示的梯度来指导搜索过程,并迭代地进行搜索。具体来说,DeePEn 将搜索的起始点
相对于绝对表示的梯度来指导搜索过程,并迭代地进行搜索。具体来说,DeePEn 将搜索的起始点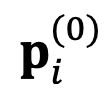 初始化为主模型的原始绝对表示,并进行更新:
初始化为主模型的原始绝对表示,并进行更新:
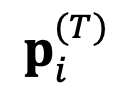 来确定下一步输出的 token。
来确定下一步输出的 token。 


以上是LLama+Mistral+…+Yi=? 免训练异构大模型集成学习框架DeePEn来了的详细内容。更多信息请关注PHP中文网其他相关文章!





















