近日,快手可灵大模型团队开源了名为LivePortrait的可控人像视频生成框架,该框架能够准确、实时地将驱动视频的表情、姿态迁移到静态或动态人像视频上,生成极具表现力的视频结果。如下动图所示:
快手开源的LivePortrait对应的论文题目为:《 LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control 》
并且,LivePortrait发布即可用,秉承快手风格,论文、主页、代码一键三连。LivePortrait一经开源,就得到了HuggingFace首席执行官Clément Delangue的关注转发,首席战略官 Thomas Wolf还亲自体验了功能,厉害了!
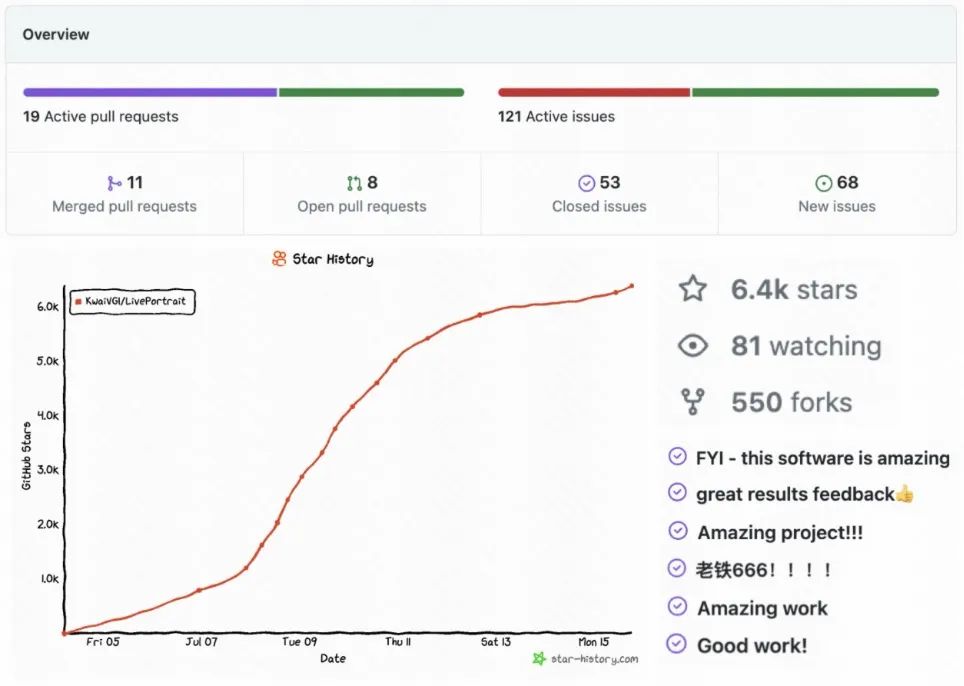
并引起了全世界网友的大规模评测:同时,LivePotrait获得了开源社区的广泛关注,短短一周多时间左右,在GitHub上总计收获了6.4K Stars,550 Forks,140 Issues&PRs,获得广泛好评,关注仍在持续增长中:此外,HuggingFace Space、Papers with code趋势榜连续一周榜一,近日登顶HuggingFace所有主题排行榜榜一:
|
HuggingFace Space榜一Papers with code榜一 |
HuggingFace所有主题排行榜一 |
- 代码地址:https://github.com/KwaiVGI/LivePortrait
- 论文链接:https://arxiv.org/abs/2407.03168
- 项目主页:https://liveportrait.github.io/
- HuggingFace Space一键在线体验:https://huggingface.co/spaces/KwaiVGI/LivePortrait
LivePortrait到底用了什么样的技术,能够在全网快速"走红"呢?和当前主流基于扩散模型的方法不同,LivePortrait探索并拓展了基于隐式关键点框架的潜力,从而平衡了模型计算效率和可控性。LivePortrait聚焦于更好的泛化性,可控性和实用的效率。为了提升生成能力和可控性,LivePortrait采用69M高质量训练帧,视频-图片混合训练策略,升级网络结构,并设计了更好的动作建模和优化方式。此外,LivePortrait将隐式关键点看成一种面部混合变形 (Blendshape) 的有效隐式表示,并基于此精心提出了贴合 (stitching) 和重定向 (retargeting) 模块。这两个模块为轻量MLP网络,因此在提升可控性的同时,计算成本可以忽略。即使是和一些已有的基于扩散模型的方法比较,LivePortrait依旧很能打。同时,在RTX4090 GPU上,LivePortrait的单帧生成速度能够达到12.8ms,若经过进一步优化,如TensorRT,预计能达10ms以内!LivePortrait的模型训练分为两阶段。第一阶段为基础模型训练,第二阶段为贴合和重定向模块训练。
在第一阶段模型训练中,LivePortrait对基于隐式点的框架,如Face Vid2vid[1],做了一系列改进,包括:高质量训练数据收集:LivePortrait采用了公开视频数据集Voxceleb[2],MEAD[3],RAVDESS [4]和风格化图片数据集AAHQ[5]。此外,还使用了大规模4K分辨率的人像视频,包含不同的表情和姿态,200余小时的说话人像视频,一个私有的数据集LightStage[6],以及一些风格化的视频和图片。LivePortrait将长视频分割成少于30秒的片段,并确保每个片段只包含一个人。为了保证训练数据的质量,LivePortrait使用快手自研的KVQ[7](快手自研的视频质量评估方法,能够综合感知视频的质量、内容、场景、美学、编码、音频等特征,执行多维度评价)来过滤低质量的视频片段。总训练数据有69M视频,包含18.9K身份和60K静态风格化人像。视频-图像混合训练:仅使用真人人像视频训练的模型对于真人人像表现良好,但对风格化人像(例如动漫)的泛化能力不足。风格化的人像视频是较为稀有的,LivePortrait从不到100个身份中收集了仅约1.3K视频片段。相比之下,高质量的风格化人像图片更为丰富,LivePortrait收集了大约60K身份互异的图片,提供多样身份信息。为了利用这两种数据类型,LivePortrait将每张图片视为一帧视频片段,并同时在视频和图片上训练模型。这种混合训练提升了模型的泛化能力。升级的网络结构:LivePortrait将规范隐式关键点估计网络 (L),头部姿态估计网络 (H) 和表情变形估计网络 (Δ) 统一为了一个单一模型 (M),并采用ConvNeXt-V2-Tiny[8]为其结构,从而直接估计输入图片的规范隐式关键点,头部姿态和表情变形。此外,受到face vid2vid相关工作启发,LivePortrait采用效果更优的SPADE[9]的解码器作为生成器 (G)。隐式特征 (fs) 在变形后被细致地输入SPADE解码器,其中隐式特征的每个通道作为语义图来生成驱动后的图片。为了提升效率,LivePortrait还插入PixelShuffle[10]层作为 (G) 的最后一层,从而将分辨率由256提升为512。更灵活的动作变换建模:原始隐式关键点的计算建模方式忽视了缩放系数,导致该缩放容易被学到表情系数里,使得训练难度变大。为了解决这个问题,LivePortrait在建模中引入了缩放因子。LivePortrait发现缩放正则投影会导致过于灵活的可学习表情系数,造成跨身份驱动时的纹理粘连。因此LivePortrait采用的变换是一种灵活性和驱动性之间的折衷。关键点引导的隐式关键点优化:原始的隐式点框架似乎缺少生动驱动面部表情的能力,例如眨眼和眼球运动。具体来说,驱动结果中人像的眼球方向和头部朝向往往保持平行。LivePortrait将这些限制归因于无监督学习细微面部表情的困难。为了解决这个问题,LivePortrait引入了2D关键点来捕捉微表情,用关键点引导的损失 (Lguide)作为隐式关键点优化的引导。级联损失函数:LivePortrait采用了face vid2vid的隐式关键点不变损失 (LE),关键点先验损失 (LL),头部姿态损失 (LH) 和变形先验损失 (LΔ)。为了进一步提升纹理质量,LivePortrait采用了感知和GAN损失,不仅对输入图的全局领域,面部和嘴部的局部领域也施加了这些损失,记为级联感知损失 (LP,cascade) 和级联GAN损失 (LG,cascade) 。面部和嘴部区域由2D语义关键点定义。LivePortrait也采用了人脸身份损失 (Lfaceid) 来保留参考图片的身份。第一阶段的所有模块为从头训练,总的训练优化函数 (Lbase) 为以上损失项的加权和。LivePortrait将隐式关键点可以看成一种隐式混合变形,并发现这种组合只需借助一个轻量的MLP便可被较好地学习,计算消耗可忽略。考虑到实际需求,LivePortrait设计了一个贴合模块、眼部重定向模块和嘴部重定向模块。当参考人像被裁切时,驱动后的人像会从裁图空间被反贴回原始图像空间,贴合模块的加入是为了避免反贴过程中出现像素错位,比如肩膀区域。由此,LivePortrait能对更大的图片尺寸或多人合照进行动作驱动。眼部重定向模块旨在解决跨身份驱动时眼睛闭合不完全的问题,尤其是当眼睛小的人像驱动眼睛大的人像时。嘴部重定向模块的设计思想类似于眼部重定向模块,它通过将参考图片的嘴部驱动为闭合状态来规范输入,从而更好地进行驱动。
贴合模块:在训练过程中,贴合模块 (S) 的输入为参考图的隐式关键点 (xs) 和另一身份驱动帧的隐式关键点 (xd),并估计驱动隐式关键点 (xd) 的表情变化量 (Δst)。可以看到,和第一阶段不同,LivePortrait采用跨身份的动作替代同身份的动作来增加训练难度,旨在使贴合模块具有更好的泛化性。接着,驱动隐式关键点 (xd) 被更新,对应的驱动输出为 (Ip,st) 。LivePortrait在这一阶段也同时输出自重建图片 (Ip,recon)。最后,贴合模块的损失函数 (Lst) 计算两者肩膀区域的像素一致损失以及贴合变化量的正则损失。眼部和嘴部重定向模块:眼部重定向模块 (Reyes) 的输入为参考图隐式关键点 (xs),参考图眼部张开条件元组和一个随机的驱动眼部张开系数,由此估计驱动关键点的变形变化量 (Δeyes)。眼部张开条件元组表示眼部张开比例,越大表示眼部张开程度越大。类似的,嘴部重定向模块 (Rlip) 的输入为参考图隐式关键点 (xs),参考图嘴部张开条件系数和一个随机的驱动嘴部张开系数,并由此估计驱动关键点的变化量 (Δlip)。接着,驱动关键点 (xd) 分别被眼部和嘴部对应的变形变化量更新,对应的驱动输出为 (Ip,eyes) 和 (Ip,lip) 。最后,眼部和嘴部重定向模块的目标函数分别为 (Leyes) 和 (Llip),分别计算眼部和嘴部区域的像素一致性损失,眼部和嘴部变化量的正则损失,以及随机驱动系数与驱动输出的张开条件系数之间的损失。眼部和嘴部的变化量 (Δeyes) 和 (Δlip) 是相互独立的,因此在推理阶段,它们可以被线性相加并更新驱动隐式关键点。
同身份驱动:由如上同身份驱动对比结果可见,与已有的非扩散模型方法和基于扩散模型的方法相比,LivePortrait具有较好的生成质量和驱动精确度,可以捕捉驱动帧的眼部和嘴部细微表情,同时保有参考图片的纹理和身份。即使在较大的头部姿态下,LivePortrait也有较稳定的表现。
跨身份驱动:由如上跨身份驱动对比结果可见,与已有的方法相比,LivePortrait可以准确地继承驱动视频中细微的眼部和嘴部动作,同时在姿态较大时也比较稳定。LivePortrait在生成质量上略弱于基于扩散模型的方法AniPortrait[11],但与后者相比,LivePortrait具有极快的推理效率且需要较少的FLOPs。多人驱动:得益于LivePortrait的贴合模块,对于多人合照,LivePortrait可以用指定驱动视频对指定人脸进行驱动,从而实现多人合照驱动,拓宽了LivePortrait的实际应用。动物驱动:LivePortrait不仅对人像具有良好的泛化性,当在动物数据集上微调后,对动物肖像也可进行精准驱动。
人像视频编辑:除了人像照片,给定一段人像视频,比如舞蹈视频,LivePortrait可以用驱动视频对头部区域进行动作编辑。得益于贴合模块,LivePortrait可以精准地编辑头部区域的动作,如表情、姿态等,而不影响非头部区域的画面。LivePortrait的相关技术点,已在快手的诸多业务完成落地,包括快手魔表、快手私信、快影的AI表情玩法、快手直播、以及快手孵化的面向年轻人的噗叽APP等,并将探索新的落地方式,持续为用户创造价值。此外,LivePortrait会基于可灵基础模型,进一步探索多模态驱动的人像视频生成,追求更高品质的效果。[1] Ting-Chun Wang, Arun Mallya, and Ming-Yu Liu. One-shot free-view neural talking-head synthesis for video conferencing. In CVPR, 2021.[2] Arsha Nagrani, Joon Son Chung, and Andrew Zisserman. Voxceleb: a large-scale speaker identification dataset. In Interspeech, 2017.[3] Kaisiyuan Wang, Qianyi Wu, Linsen Song, Zhuoqian Yang, Wayne Wu, Chen Qian, Ran He, Yu Qiao, and Chen Change Loy. Mead: A large-scale audio-visual dataset for emotional talking-face generation. In ECCV, 2020.[4] Steven R Livingstone and Frank A Russo. The ryerson audio-visual database of emotional speech and song (ravdess): A dynamic, multimodal set of facial and vocal expressions in north american english. In PloS one, 2018[5] Mingcong Liu, Qiang Li, Zekui Qin, Guoxin Zhang, Pengfei Wan, and Wen Zheng. Blendgan: Implicitly gan blending for arbitrary stylized face generation. In NeurIPS, 2021.[6] Haotian Yang, Mingwu Zheng, Wanquan Feng, Haibin Huang, Yu-Kun Lai, Pengfei Wan, Zhongyuan Wang, and Chongyang Ma. Towards practical capture of high-fidelity relightable avatars. In SIGGRAPH Asia, 2023.[7] Kai Zhao, Kun Yuan, Ming Sun, Mading Li, and Xing Wen. Quality-aware pre-trained models for blind image qualityassessment. In CVPR, 2023.[8] Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, and Saining Xie. Con-vnext v2: Co-designing and scaling convnets with masked autoencoders. In CVPR, 2023.[9] Taesung Park, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu. Semantic image synthesis with spatially-adaptive normalization. In CVPR, 2019.[10] Wenzhe Shi, Jose Caballero, Ferenc Husz ´ar, Johannes Totz, Andrew P Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In CVPR, 2016.[11] Huawei Wei, Zejun Yang, and Zhisheng Wang. Aniportrait: Audio-driven synthesis of photorealistic portrait animation. arXiv preprint:2403.17694, 2024.以上是快手开源LivePortrait,GitHub 6.6K Star,实现表情姿态极速迁移的详细内容。更多信息请关注PHP中文网其他相关文章!






 HuggingFace Space榜一
HuggingFace Space榜一 Papers with code榜一
Papers with code榜一 HuggingFace所有主题排行榜一
HuggingFace所有主题排行榜一






























