

Reddit CEO:微软等公司必须付费才能抓取数据

本站 8 月 1 日消息,Reddit CEO 史蒂夫・霍夫曼近日表示,如果微软等公司希望继续抓取该网站的数据,就必须付费。此前,Reddit 已经与谷歌和 OpenAI 达成协议。

图源 Pexels
霍夫曼指出,如果没有这些协议,Reddit 无法控制或了解其数据的使用方式,这迫使他们不得不屏蔽那些不愿意接受数据使用条件的公司。他特别点名了微软、Anthropic 和 Perplexity 三家公司,称他们拒绝谈判,并称封锁这些公司“非常麻烦”。
近几个月来,Reddit 一直在加大力度打击爬虫。7 月初,Reddit 更新了 robots.txt 文件,屏蔽了未经授权的网络爬虫。随后人们发现,Reddit 的内容只出现在谷歌搜索结果中,而 Bing 等其他搜索引擎上则看不到。
霍夫曼指责微软未经授权利用 Reddit 的数据训练 AI,并在 Bing 搜索结果中总结 Reddit 内容,甚至通过 Bing API 将这些数据出售给其他搜索引擎。他还回应了微软 AI 负责人穆斯塔法・苏莱曼此前关于互联网公共数据是“免费软件”的言论,称微软等公司认为互联网上的所有内容都可以供他们免费使用,这是他们的真实立场。
本站注意到,针对 Reddit 搜索结果从 Bing 消失一事,微软搜索主管乔迪・里巴斯在社交媒体上表示,Reddit 屏蔽了 Bing 的爬虫,偏袒另一家搜索引擎,影响了 Bing 和基于 Bing 的搜索引擎的竞争。微软发言人凯特琳・劳尔顿也表示,公司尊重网站不希望其内容被用于生成式 AI 模型的意愿。
霍夫曼以 OpenAI 的 SearchGPT 为例,强调了付费协议的重要性。今年早些时候,Reddit 和 OpenAI 达成协议,允许 SearchGPT 显示 Reddit 内容。Reddit 发言人蒂姆・拉特施密特表示,目前签订的所有内容许可协议都不涉及数据独占使用权。
Reddit 要求付费的做法与传统媒体出版商类似,他们也希望从允许内容用于生成式 AI 中获得收益。霍夫曼认为,搜索引擎的传统价值交换已经改变,搜索、摘要和训练正在融合,单纯依靠爬取内容换取流量的模式变得模糊。
以上是Reddit CEO:微软等公司必须付费才能抓取数据的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 用户遭遇罕见故障 三星 Watch 智能手表突现白屏问题
Apr 03, 2024 am 08:13 AM
用户遭遇罕见故障 三星 Watch 智能手表突现白屏问题
Apr 03, 2024 am 08:13 AM
你可能遇到过智能手机屏幕出现绿色线条的问题,即使没见过,也一定在网络上看到过相关图片。那么,智能手表屏幕变白的情况你遇见过吗?4月2日,CNMO从外媒了解到,一名Reddit用户在社交平台上分享了一张图片,展示了三星Watch系列智能手表屏幕变白的情况。该用户写道:"我离开时正在充电,回来时就这样了,我尝试重启,但重启过程中屏幕还是这样。"三星Watch智能手表屏幕变白这位Reddit用户并未指明这款智能手表的具体型号。不过,从图片上看,应该是三星Watch5。此前,另一位Reddit用户也报告
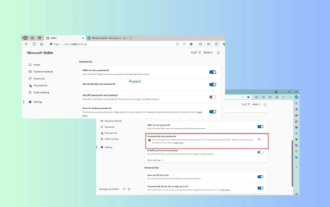 Microsoft Edge升级:自动存密码功能遭禁?!用户惊了!
Apr 19, 2024 am 08:13 AM
Microsoft Edge升级:自动存密码功能遭禁?!用户惊了!
Apr 19, 2024 am 08:13 AM
4月18日消息,近日,一些使用Canary频道的MicrosoftEdge浏览器的用户反映,在升级到最新版本后,他们发现自动保存密码的选项被禁用了。经过调查,这是浏览器升级后的一个微调,而非功能被取消。在使用Edge浏览器访问网站前,用户反馈说浏览器会弹出一个窗口询问是否希望保存该网站的登录密码。选择保存后,在下一次登录时,Edge就会自动填充已保存的账号和密码,为用户提供了极大的便利。但最近的更新类似于微调,修改了默认设置。用户需要在选择保存密码后,再手动在设置中开启自动填充已保存的账号和密码
 微软发布 Win11 八月累积更新:提高安全、优化锁屏等
Aug 14, 2024 am 10:39 AM
微软发布 Win11 八月累积更新:提高安全、优化锁屏等
Aug 14, 2024 am 10:39 AM
本站8月14日消息,在今天的8月补丁星期二活动日中,微软发布了适用于Windows11系统的累积更新,包括面向22H2和23H2的KB5041585更新,面向21H2的KB5041592更新。上述设备安装8月累积更新之后,本站附上版本号变化如下:21H2设备安装后版本号升至Build22000.314722H2设备安装后版本号升至Build22621.403723H2设备安装后版本号升至Build22631.4037面向Windows1121H2的KB5041585更新主要内容如下:改进:提高了
 微软全屏弹窗催促:Windows 10用户抓紧时间升级到Windows 11
Jun 06, 2024 am 11:35 AM
微软全屏弹窗催促:Windows 10用户抓紧时间升级到Windows 11
Jun 06, 2024 am 11:35 AM
6月3日消息,微软正在积极向所有Windows10用户发送全屏通知,鼓励他们升级到Windows11操作系统。这一举措涉及了那些硬件配置并不支持新系统的设备。自2015年起,Windows10已经占据了近70%的市场份额,稳坐Windows操作系统的霸主地位。然而,市场占有率远超过82%的市场份额,占有率远超过2021年面世的Windows11。尽管Windows11已经推出已近三年,但其市场渗透率仍显缓慢。微软已宣布,将于2025年10月14日后终止对Windows10的技术支持,以便更专注于
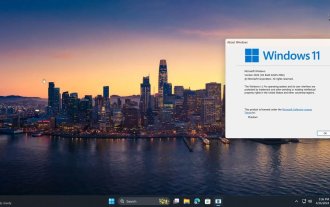 微软 Win11 压缩为 7z、TAR 文件的功能已从 24H2 下放到 23H2/22H2 版本
Apr 28, 2024 am 09:19 AM
微软 Win11 压缩为 7z、TAR 文件的功能已从 24H2 下放到 23H2/22H2 版本
Apr 28, 2024 am 09:19 AM
本站4月27日消息,微软本月初向Canary和Dev频道发布了Windows11Build26100预览版更新,预估会成为Windows1124H2更新的候选RTM版本。新版本中最主要的变化在于文件资源管理器、整合Copilot、编辑PNG文件元数据、创建TAR和7z压缩文件等等。@PhantomOfEarth发现,微软已经将24H2版本(Germanium)部分功能下放到23H2/22H2(Nickel)版本中,例如创建TAR和7z压缩文件。如示意图所示,Windows11将支持原生创建TAR
 微软Edge浏览器更新:新增'放大图像”功能,提升用户体验
Mar 21, 2024 pm 01:40 PM
微软Edge浏览器更新:新增'放大图像”功能,提升用户体验
Mar 21, 2024 pm 01:40 PM
3月21日消息,微软近日对其MicrosoftEdge浏览器进行了更新,新增了一项实用的“放大图像”功能。现在,用户在使用Edge浏览器时,只需右键点击图片,便可在弹出的菜单中轻松找到这一新功能。更为便捷的是,用户还可以将光标悬停在图片上方,然后双击Ctrl键,即可快速呼出放大图像的功能。根据小编的了解,最新发布的MicrosoftEdge浏览器已经在Canary频道进行了新功能测试。该浏览器的稳定版中也已经正式推出了实用的“放大图像”功能,为用户提供了更便捷的图片浏览体验。外国科技媒体也对这一
 微软计划2024年下半年在Windows 11中淘汰NTLM,全面转向Kerberos认证
Jun 09, 2024 pm 04:17 PM
微软计划2024年下半年在Windows 11中淘汰NTLM,全面转向Kerberos认证
Jun 09, 2024 pm 04:17 PM
2024年下半年,微软安全官方博客发布了一条消息,以回应安全社区的呼吁。公司计划在2024年下半年发布的Windows11中淘汰NTLANManager(NTLM)认证协议,以提升安全性。根据之前的解释,微软此前已经有过类似的动作。去年10月12日,微软在一份官方新闻稿中就已经提出了一个过渡计划,旨在逐步淘汰NTLM身份验证方式,并推动更多企业和用户转向使用Kerberos。为了帮助那些可能在关闭NTLM身份验证后遇到硬连接(hardwired)应用程序和服务问题的企业,微软提供了IAKerb和
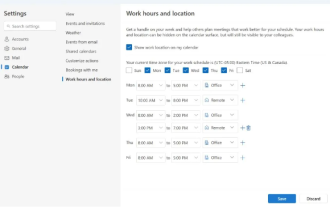 微软推出新版Outlook for Windows:日历功能全面升级
Apr 27, 2024 pm 03:44 PM
微软推出新版Outlook for Windows:日历功能全面升级
Apr 27, 2024 pm 03:44 PM
在4月27日的消息中,微软公司宣布即将发布新版OutlookforWindows客户端的测试。此次更新主要聚焦于优化日历功能,旨在提升用户的工作效率,进一步简化日常工作流程。新版OutlookforWindows客户端的改进点在于其更加强大的日历管理功能。现在,用户能够更便捷地分享个人的工作时间与地点信息,使得会议规划变得更为高效。此外,Outlook还新增了人性化设置,允许用户设定会议自动提前结束或推迟开始,为用户提供了更多的灵活性,无论是换会议室、稍作休息还是享受一杯咖啡,都能轻松安排。根据
