

投机采样会损失大语言模型的推理精度吗?

Mitchell Stern 等人于 2018 年提出了投机采样的原型概念。这种方法后来被各种工作进一步发展和完善,包括 Lookahead Decoding、REST、Medusa 和 EAGLE,投机采样显着加快了大型语言模型 (LLM) 的推理过程。
一个重要的问题是:LLM 中的投机采样会损害原始模型的准确性吗?先说答案:不会。
标准的投机采样算法是无损的,本文将通过数学分析和实验来证明这一点。
数学证明
投机采样公式可以定义如下:

其中:
- ? 是从均匀分布中采样的实数。
-
 是要预测的下一个token。
是要预测的下一个token。 - ?(?) 是草稿模型给出的下一个token分布。
- ?(?) 是基础模型给出的下一个token分布。
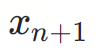 是要预测的下一个token。
是要预测的下一个token。 为简单起见,我们省略了概率条件。实际上,? 和 ? 是基于前缀token序列  的条件分布。
的条件分布。
以下是DeepMind 论文中关于该公式无损性的证明:

如果你觉得阅读数学方程式太枯燥,接下来我们将通过一些直观的图表来说明证明过程。
这是草稿模型 ? 和基础模型 ? 的分布示意图:
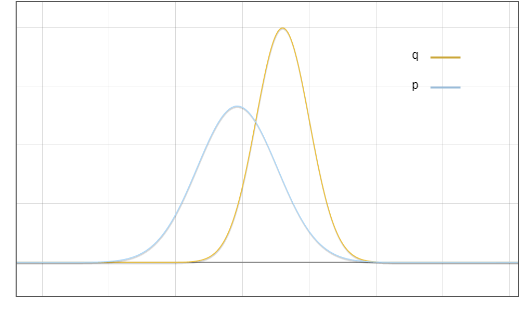
图1:草案模型p和基础模型q输出分布的概率密度函数
需要说明的是,这只是一个理想化的图表。在实践中,我们计算的是一个离散分布,它看起来像这样:
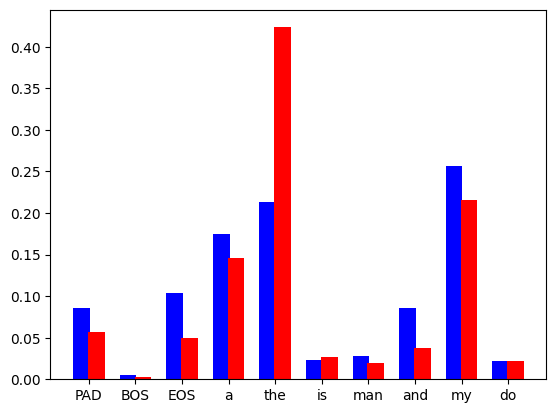
图2:语言模型预测词汇集中每个token的离散概率分布,蓝色条来自草稿模型,红色条来自基础模型。
然而,为了简单和清晰起见,我们使用它的连续近似来讨论这个问题。
现在的问题是:我们从分布 ? 中采样,但我们希望最终结果就像我们从 ? 中采样一样。一个关键思想是:将红色区域的概率搬运到黄色区域:
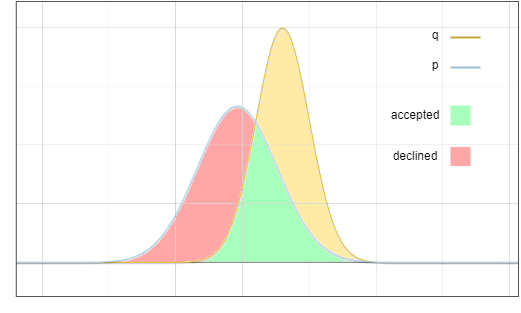
图3:接受和拒绝采样的区域
目标分布 ? 可以看作是两部分的总和:
I. 校验接受
该分支中有两个独立事件:
- 在草稿分布 ? 上采样产生特定token ?。概率为 ?(?)
- 随机变量 ? 接受该token ?。概率为:
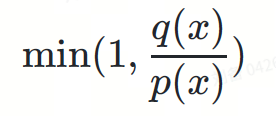
将这些概率相乘: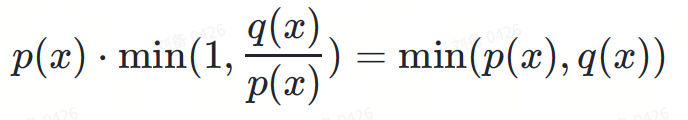
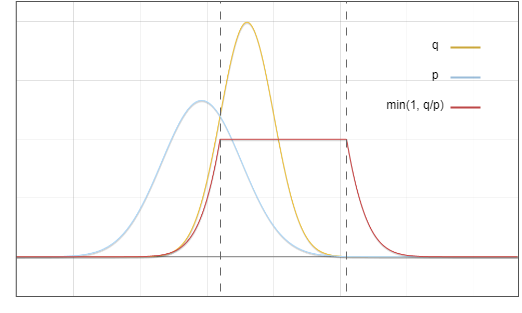
图4:将蓝线和红线相乘,结果是图6中的绿线
II. 校验拒绝
该分支中也有两个独立事件:
- ? 拒绝了? 中的某个token,概率为:
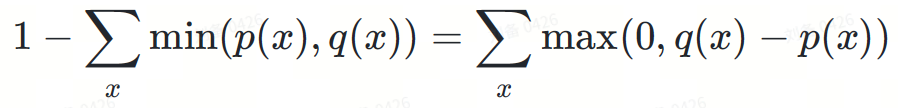
这是一个积分值,数值与特定token x 无关
- 在分布 ?−?(的正数部分)上采样产生特定token ?,概率为:
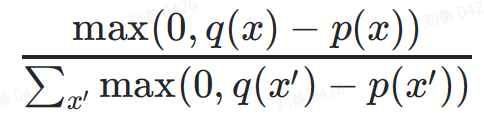
其分母作用是对概率分布进行归一化,以保持概率密度积分等于 1。
两项相乘,第二项的分母被约掉:
max(0,?(?)−?(?))
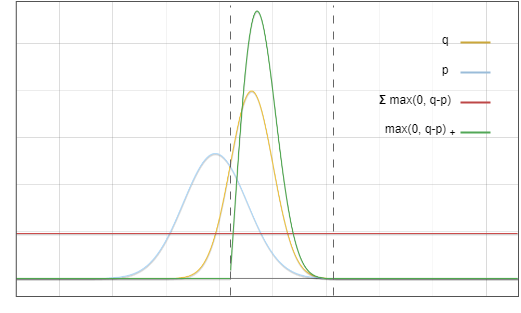
图5. 该图中的红线与绿线对应函数相乘,结果等于图6中的红线
为什么拒绝概率恰好可以归一化max(0,?−?) ?看起来似乎是巧合,这里一个重要的观察是,图 3 中红色区域的面积等于黄色区域的面积,因为所有概率密度函数的积分都等于 1。
将I, II两部分相加: 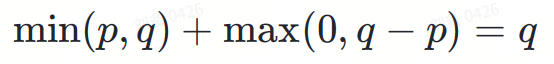
最后,我们得到了目标分布 ?。
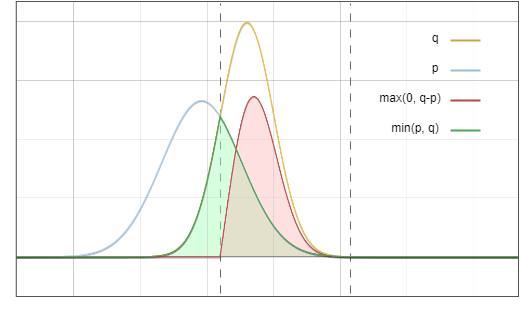
图6. 绿色区域与红色区域相加,正好等于黄线以下的面积
而这正是我们的目标。
实验
尽管我们已经从原理上证明了投机采样是无损的,但算法的实现仍然可能存在bug。因此,实验验证也是必要的。
我们对两种情况进行了实验:贪婪解码的确定性方法和多项式采样的随机方法。
贪婪解码
我们要求 LLM 生成两次短篇故事,首先使用普通推理,然后使用投机采样。两次采样温度均设置为 0。我们使用了 Medusa 中的投机采样实现。模型权重为 medusa-1.0-vicuna-7b-v1.5 及其基础模型 vicuna-7b-v1.5。
测试运行完成后,我们得到了两个精确相同的结果。生成的文本如下:
User: Please tell a tale about a cyperpunk knight named PPIO keeps a charming llama as his pet. Assistant : Once upon a time, in a world where technology had advanced beyond our wildest dreams, there lived a cyberpunk knight named PPIO. PPIO was a skilled warrior, with advanced cybernetic enhancements that gave him incredible strength and speed. He was also a man of great honor, always striving to do what was right and just.One day, while out on a mission, PPIO stumbled upon a beautiful llama. Despite being a cybernetic being, PPIO had a soft spot for animals and he couldn't resist rescuing the llama from whatever danger it may have been in. From that day on, the llama followed PPIO wherever he went, and the two became fast friends.The llama, whose name was Llama-ella, was a special llama. It had a unique ability to sense when someone was in danger and would let out a loud, distinctive call to alert them to the danger. PPIO was grateful for Llama-ella's ability and the two became an unstoppable team. Together, PPIO and Llama-ella took on all sorts of challenges, from battling cybernetic villains to rescuing innocent people from harm. They were a force to be reckoned with, and their bravery and honor were an inspiration to all who knew them.
|
 |
 |
|
|
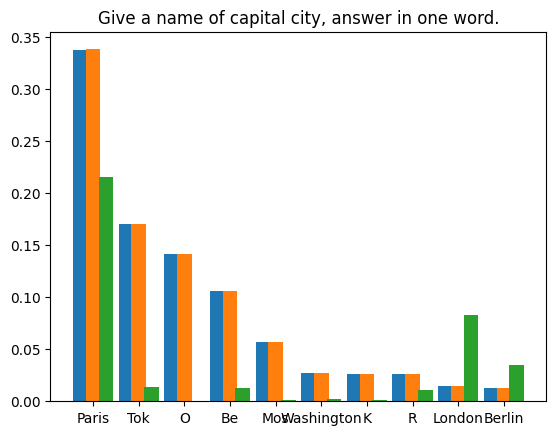
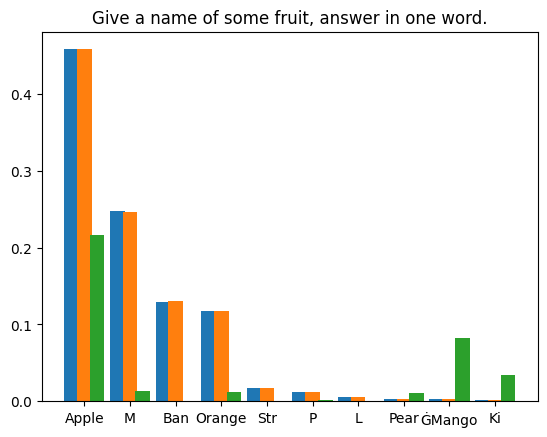
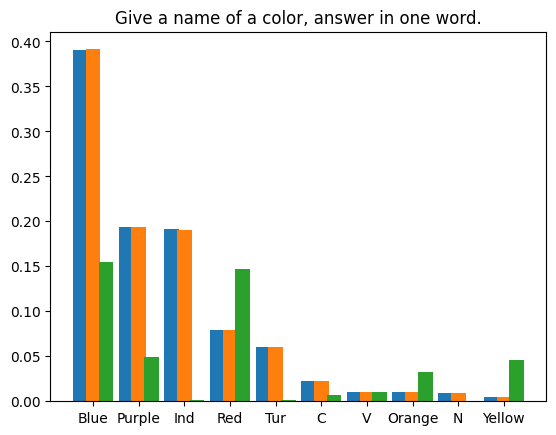
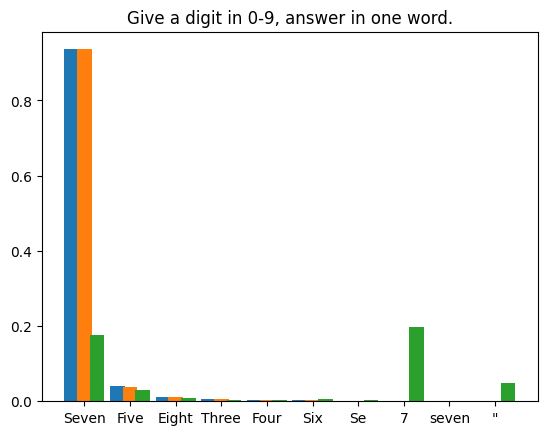
- 蓝色:来自基础模型输出 logits 的 softmax
- 绿色:来自草稿模型输出 logits 的 softmax
- 橙色:来自投机采样(1,000,000 次)的首个token计数占比
基础模型输出结果与采样分布之间的标准差为 9.694e-5。符合预期。
结论
投机采样不会损害大型语言模型的推理精度。通过严格的数学分析和实际实验,我们证明了标准投机采样算法的无损性。其中数学证明说明了投机采样公式如何保留基础模型的原始分布。我们的实验,包括确定性贪婪解码和概率多项式采样,进一步验证了这些理论发现。贪婪解码实验在使用和不使用投机采样的情况下产生了相同的结果,而多项式采样实验表明,在大量样本中,token分布的差异可以忽略不计。
这些结果共同证明,投机采样可以显着加快 LLM 推理速度,而不会牺牲准确性,为未来更高效、更易于访问的 AI 系统铺平了道路。
以上是投机采样会损失大语言模型的推理精度吗?的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 ControlNet作者又出爆款!一张图生成绘画全过程,两天狂揽1.4k Star
Jul 17, 2024 am 01:56 AM
ControlNet作者又出爆款!一张图生成绘画全过程,两天狂揽1.4k Star
Jul 17, 2024 am 01:56 AM
同样是图生视频,PaintsUndo走出了不一样的路线。ControlNet作者LvminZhang又开始整活了!这次瞄准绘画领域。新项目PaintsUndo刚上线不久,就收获1.4kstar(还在疯狂涨)。项目地址:https://github.com/lllyasviel/Paints-UNDO通过该项目,用户输入一张静态图像,PaintsUndo就能自动帮你生成整个绘画的全过程视频,从线稿到成品都有迹可循。绘制过程,线条变化多端甚是神奇,最终视频结果和原图像非常相似:我们再来看一个完整的绘
 登顶开源AI软件工程师榜首,UIUC无Agent方案轻松解决SWE-bench真实编程问题
Jul 17, 2024 pm 10:02 PM
登顶开源AI软件工程师榜首,UIUC无Agent方案轻松解决SWE-bench真实编程问题
Jul 17, 2024 pm 10:02 PM
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com这篇论文的作者均来自伊利诺伊大学香槟分校(UIUC)张令明老师团队,包括:StevenXia,四年级博士生,研究方向是基于AI大模型的自动代码修复;邓茵琳,四年级博士生,研究方
 从RLHF到DPO再到TDPO,大模型对齐算法已经是「token-level」
Jun 24, 2024 pm 03:04 PM
从RLHF到DPO再到TDPO,大模型对齐算法已经是「token-level」
Jun 24, 2024 pm 03:04 PM
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com在人工智能领域的发展过程中,对大语言模型(LLM)的控制与指导始终是核心挑战之一,旨在确保这些模型既强大又安全地服务于人类社会。早期的努力集中于通过人类反馈的强化学习方法(RL
 arXiv论文可以发「弹幕」了,斯坦福alphaXiv讨论平台上线,LeCun点赞
Aug 01, 2024 pm 05:18 PM
arXiv论文可以发「弹幕」了,斯坦福alphaXiv讨论平台上线,LeCun点赞
Aug 01, 2024 pm 05:18 PM
干杯!当论文讨论细致到词句,是什么体验?最近,斯坦福大学的学生针对arXiv论文创建了一个开放讨论论坛——alphaXiv,可以直接在任何arXiv论文之上发布问题和评论。网站链接:https://alphaxiv.org/其实不需要专门访问这个网站,只需将任何URL中的arXiv更改为alphaXiv就可以直接在alphaXiv论坛上打开相应论文:可以精准定位到论文中的段落、句子:右侧讨论区,用户可以发表问题询问作者论文思路、细节,例如:也可以针对论文内容发表评论,例如:「给出至
 黎曼猜想显着突破!陶哲轩强推MIT、牛津新论文,37岁菲尔兹奖得主参与
Aug 05, 2024 pm 03:32 PM
黎曼猜想显着突破!陶哲轩强推MIT、牛津新论文,37岁菲尔兹奖得主参与
Aug 05, 2024 pm 03:32 PM
最近,被称为千禧年七大难题之一的黎曼猜想迎来了新突破。黎曼猜想是数学中一个非常重要的未解决问题,与素数分布的精确性质有关(素数是那些只能被1和自身整除的数字,它们在数论中扮演着基础性的角色)。在当今的数学文献中,已有超过一千条数学命题以黎曼猜想(或其推广形式)的成立为前提。也就是说,黎曼猜想及其推广形式一旦被证明,这一千多个命题将被确立为定理,对数学领域产生深远的影响;而如果黎曼猜想被证明是错误的,那么这些命题中的一部分也将随之失去其有效性。新的突破来自MIT数学教授LarryGuth和牛津大学
 OpenAI超级对齐团队遗作:两个大模型博弈一番,输出更好懂了
Jul 19, 2024 am 01:29 AM
OpenAI超级对齐团队遗作:两个大模型博弈一番,输出更好懂了
Jul 19, 2024 am 01:29 AM
如果AI模型给的答案一点也看不懂,你敢用吗?随着机器学习系统在更重要的领域得到应用,证明为什么我们可以信任它们的输出,并明确何时不应信任它们,变得越来越重要。获得对复杂系统输出结果信任的一个可行方法是,要求系统对其输出产生一种解释,这种解释对人类或另一个受信任的系统来说是可读的,即可以完全理解以至于任何可能的错误都可以被发现。例如,为了建立对司法系统的信任,我们要求法院提供清晰易读的书面意见,解释并支持其决策。对于大型语言模型来说,我们也可以采用类似的方法。不过,在采用这种方法时,确保语言模型生
 LLM用于时序预测真的不行,连推理能力都没用到
Jul 15, 2024 pm 03:59 PM
LLM用于时序预测真的不行,连推理能力都没用到
Jul 15, 2024 pm 03:59 PM
语言模型真的能用于时序预测吗?根据贝特里奇头条定律(任何以问号结尾的新闻标题,都能够用「不」来回答),答案应该是否定的。事实似乎也果然如此:强大如斯的LLM并不能很好地处理时序数据。时序,即时间序列,顾名思义,是指一组按照时间发生先后顺序进行排列的数据点序列。在很多领域,时序分析都很关键,包括疾病传播预测、零售分析、医疗和金融。在时序分析领域,近期不少研究者都在研究如何使用大型语言模型(LLM)来分类、预测和检测时间序列中的异常。这些论文假设擅长处理文本中顺序依赖关系的语言模型也能泛化用于时间序
 首个基于Mamba的MLLM来了!模型权重、训练代码等已全部开源
Jul 17, 2024 am 02:46 AM
首个基于Mamba的MLLM来了!模型权重、训练代码等已全部开源
Jul 17, 2024 am 02:46 AM
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。引言近年来,多模态大型语言模型(MLLM)在各个领域的应用取得了显着的成功。然而,作为许多下游任务的基础模型,当前的MLLM由众所周知的Transformer网络构成,这种网
