
我喜欢表情符号。谁不呢?
几天前我正在整理一篇高智商的X帖子时,我意识到了一些事情。
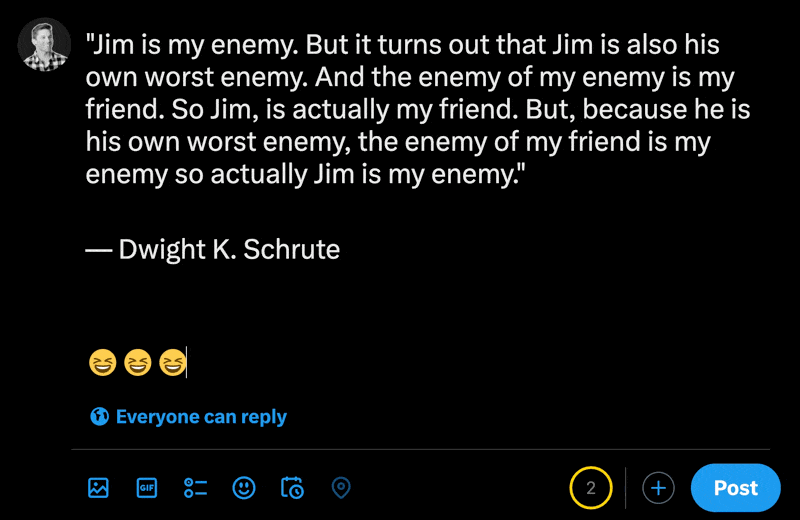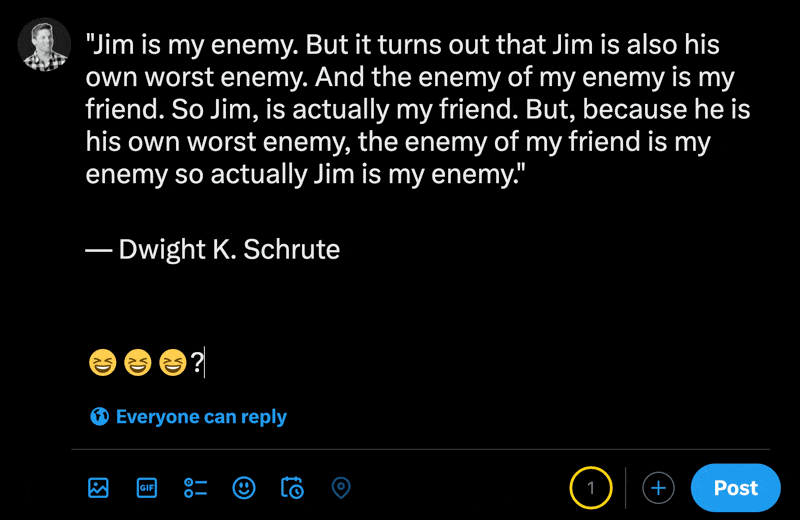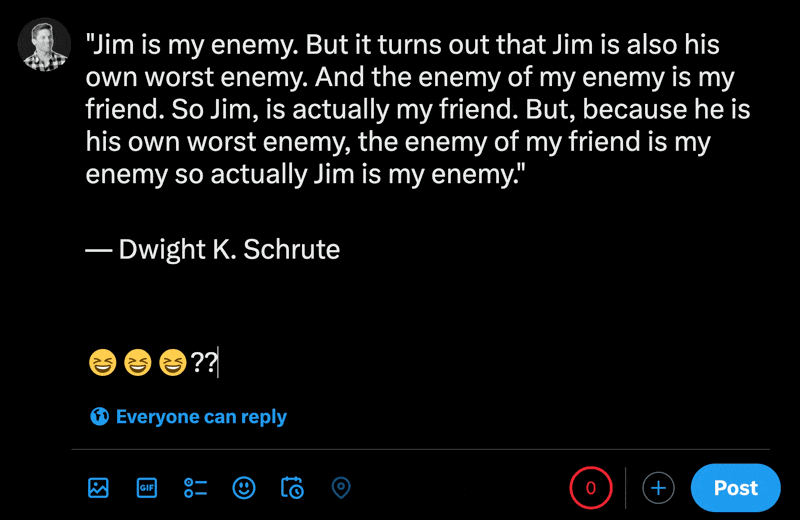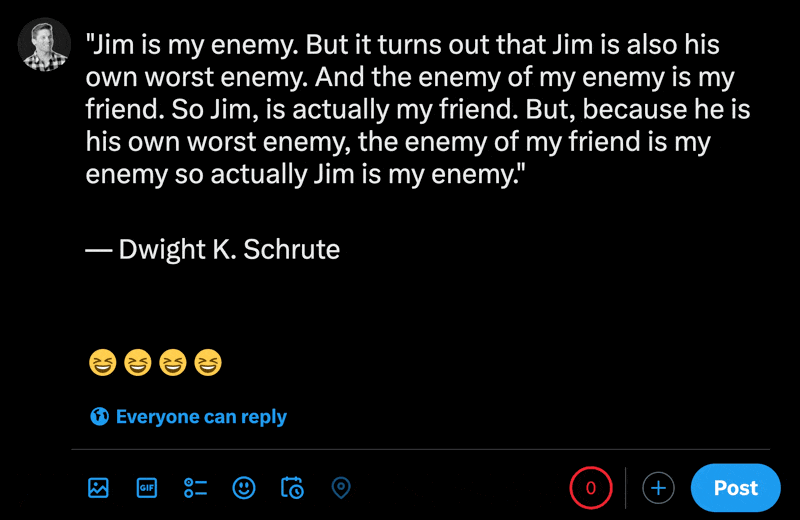
在X的新帖子部分中输入表情符号时,您可以看到常规字符的数量比表情符号少。
经过快速搜索,我发现这与它们在 Unicode 系统中的编码方式有关。
本质上,表情符号是由多个代码点组成的,长度只计算代码点,而不计算字符。
无论它为何发生,我都会思考我创建的所有文本计数器以及 SaaS 领域中存在多少个文本计数器。
表情符号没有得到公平对待?.
仅仅计算字符串的长度并不是准确的计数。举个例子,像这样:
import { useState } from "react";
export default function App() {
const [text, setText] = useState("");
function countString() {
return text.length;
}
function handleChange(e) {
setText(e.target.value);
}
return (
<div className="App">
<h1>Make the emojis count ?</h1>
<textarea value={text} onChange={handleChange} />
<small>Characters: {countString()}</small>
</div>
);
}
这是一个简单的 React 组件,用于跟踪输入到文本字段中的字符。这是此功能最常见的实现。
但是输出给我们带来了与我的 X 帖子相同的问题:

您可以使用名为 Intl.Segmenter 的内置对象。
该对象有更广泛的用例,但它本质上根据您提供的区域设置将字符串分解为更有意义的项目,例如单词和句子。它比简单地使用代码点提供了更多的粒度。
要修复上面的示例,我们所要做的就是更新我们的 countString 函数,如下所示:
import { useState } from "react";
export default function App() {
const [text, setText] = useState("");
function countString() {
return Array.from(new Intl.Segmenter().segment(text)).length;
}
function handleChange(e) {
setText(e.target.value);
}
return (
<div className="App">
<h1>Make the emojis count ?</h1>
<textarea value={text} onChange={handleChange} />
<small>Characters: {countString()}</small>
</div>
);
}
我们创建 Intl.Segmenter 对象的新实例并将文本传递给它。我们将该输出放入一个数组中,然后最后获取长度,这比简单地获取原始字符串的长度要准确得多。
结果如下:

简短回答:我不知道。
我已经编程太久了,以至于无法自欺欺人地认为有一个简单的答案。
但是 Intl.Segmenter 具有良好的浏览器支持,任何性能或内存限制都可以忽略不计。
我最好的猜测是代码库太大而且太旧,不值得重构的副作用。
如果有人对此有更深入的了解,我很乐意了解更多信息。
我希望这有帮助?.
编码愉快?.
以上是如何在 JavaScript 中使用表情符号计算字符串数量的详细内容。更多信息请关注PHP中文网其他相关文章!






















