Mamba 架构的大模型又一次向 Transformer 发起了挑战。
Mamba 架构模型这次终于要「站」起来了?自 2023 年 12 月首次推出以来,Mamba 便成为了 Transformer 的强有力竞争对手。此后,采用 Mamba 架构的模型不断出现,比如 Mistral 发布的首个基于 Mamba 架构的开源大模型 Codestral 7B。今天,阿布扎比技术创新研究所(TII)发布了一个新的开源 Mamba 模型 ——Falcon Mamba 7B。
先来总结一波 Falcon Mamba 7B 的亮点:无需增加内存存储,就可以处理任意长度的序列,并且能够在单个 24GB A10 GPU 上运行。目前可以在 Hugging Face 上查看并使用 Falcon Mamba 7B,这个仅用因果解码器的模型采用了新颖的 Mamba 状态空间语言模型(State Space Language Model, SSLM)架构来处理各种文本生成任务。从结果来看,Falcon Mamba 7B 在一些基准上超越同尺寸级别的领先模型,包括 Meta 的 Llama 3 8B、Llama 3.1 8B 和 Mistral 7B。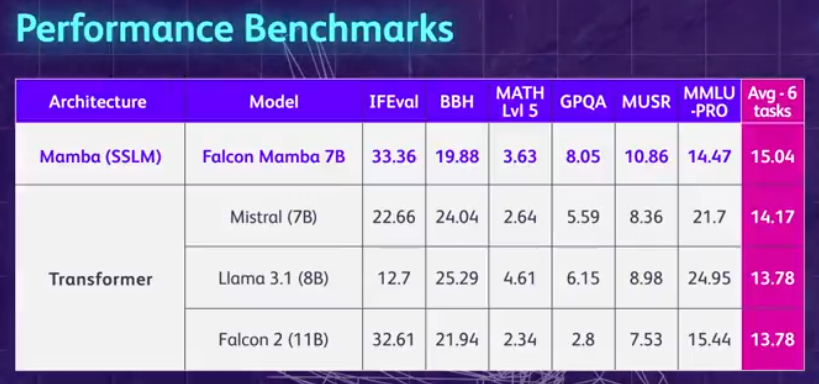
Falcon Mamba 7B 分为四个变体模型,分别是基础版本、指令微调版本、4bit 版本和指令微调 4bit 版本。
作为一个开源模型, Falcon Mamba 7B 采用了基于 Apache 2.0 的许可证「Falcon License 2.0」,支持研究和应用目的。
Hugging Face 地址:https://huggingface.co/tiiuae/falcon-mamba-7bFalcon Mamba 7B 也成为了继 Falcon 180B、Falcon 40B 和 Falcon 2 之后,TII 开源的第四个模型,并且是首个 Mamba SSLM 架构模型。
一直以来,基于 Transformer 的模型一直占据着生成式 AI 的统治地位,然而,研究人员注意到,Transformer 架构在处理较长的文本信息时可能会遇到困难。本质上,Transformer 中的注意力机制通过将每个单词(或 token)与文本中的每个单词进行比较来理解上下文,它需要更多的计算能力和内存需求来处理不断增长的上下文窗口。但是如果不相应地扩展计算资源,模型推理速度就会变慢,超过一定长度的文本就没法处理了。为了克服这些障碍,状态空间语言模型 (SSLM) 架构应运而生,该架构通过在处理单词时不断更新状态来工作,已成为一种有前途的替代方案,包括 TII 在内的很多机构都在部署这种架构。Falcon Mamba 7B 采用了卡内基梅隆大学和普林斯顿大学研究人员最初在 2023 年 12 月的一篇论文中提出的 Mamba SSM 架构。该架构使用一种选择机制,允许模型根据输入动态调整其参数。这样,模型可以关注或忽略特定输入,类似于注意力机制在 Transformer 中的工作方式,同时提供处理长文本序列(例如整本书)的能力,而无需额外的内存或计算资源。TII 指出,该方法使模型适用于企业级机器翻译、文本摘要、计算机视觉和音频处理任务以及估计和预测等任务。Falcon Mamba 7B 训练数据高达 5500GT ,主要由 RefinedWeb 数据集组成,并添加了来自公共源的高质量技术数据、代码数据和数学数据。所有数据通过 Falcon-7B/11B 标记器进行 tokenized 操作。与其他 Falcon 系列模型类似,Falcon Mamba 7B 采用多阶段训练策略进行训练,上下文长度从 2048 增加到了 8192。此外,受到课程学习概念的启发,TII 在整个训练阶段精心选择了混合数据,充分考虑了数据的多样性和复杂性。在最后的训练阶段,TII 使用了一小部分高质量精选数据(即来自 Fineweb-edu 的样本),以进一步提升性能。Falcon Mamba 7B 的大部分训练是在 256 个 H100 80GB GPU 上完成的,采用了 3D 并行(TP=1、PP=1、DP=256)与 ZeRO 相结合的策略。下图为模型超参数细节,包括精度、优化器、最大学习率、权重衰减和 batch 大小。
Secara khusus, Falcon Mamba 7B telah dilatih dengan pengoptimum AdamW, pelan kadar pembelajaran WSD (warm-stabilize-decay), dan semasa proses latihan 50 GT pertama, saiz kelompok meningkat daripada b_min=128 kepada b_max=2048 . Dalam fasa stabil, TII menggunakan kadar pembelajaran maksimum η_max=6.4×10^−4, dan kemudian mereputkannya kepada nilai minimum menggunakan pelan eksponen melebihi 500GT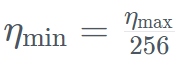 . Pada masa yang sama, TII menggunakan BatchScaling dalam fasa pecutan untuk melaraskan semula kadar pembelajaran η supaya suhu hingar Adam
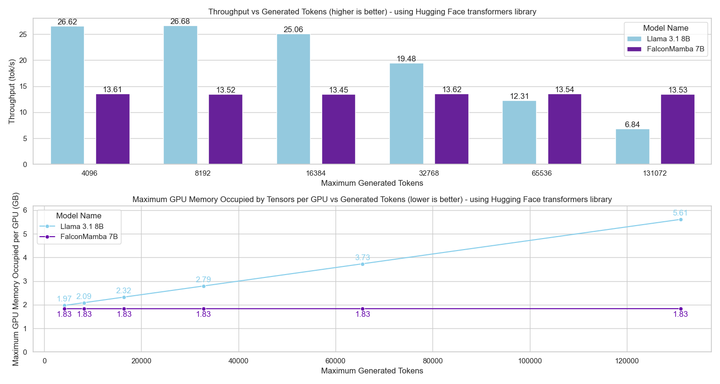
. Pada masa yang sama, TII menggunakan BatchScaling dalam fasa pecutan untuk melaraskan semula kadar pembelajaran η supaya suhu hingar Adam 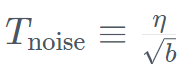 kekal malar. Keseluruhan latihan model mengambil masa kira-kira dua bulan. . panjang. Hasilnya menunjukkan bahawa Falcon Mamba mampu menyesuaikan diri dengan jujukan yang lebih besar daripada model Transformer semasa, manakala secara teorinya mampu menyesuaikan diri dengan panjang konteks tanpa had. Seterusnya, penyelidik mengukur daya pengeluaran penjanaan model menggunakan saiz kelompok 1 dan tetapan perkakasan H100 GPU. Keputusan ditunjukkan dalam rajah di bawah, Falcon Mamba menjana semua token pada daya pemprosesan berterusan tanpa sebarang peningkatan dalam memori puncak CUDA. Untuk model Transformer, memori puncak meningkat dan kelajuan penjanaan menjadi perlahan apabila bilangan token yang dijana meningkat. Malah pada penanda aras industri standard, model baharu ini berprestasi lebih baik daripada atau hampir dengan model pengubah popular serta model ruang keadaan tulen dan hibrid.
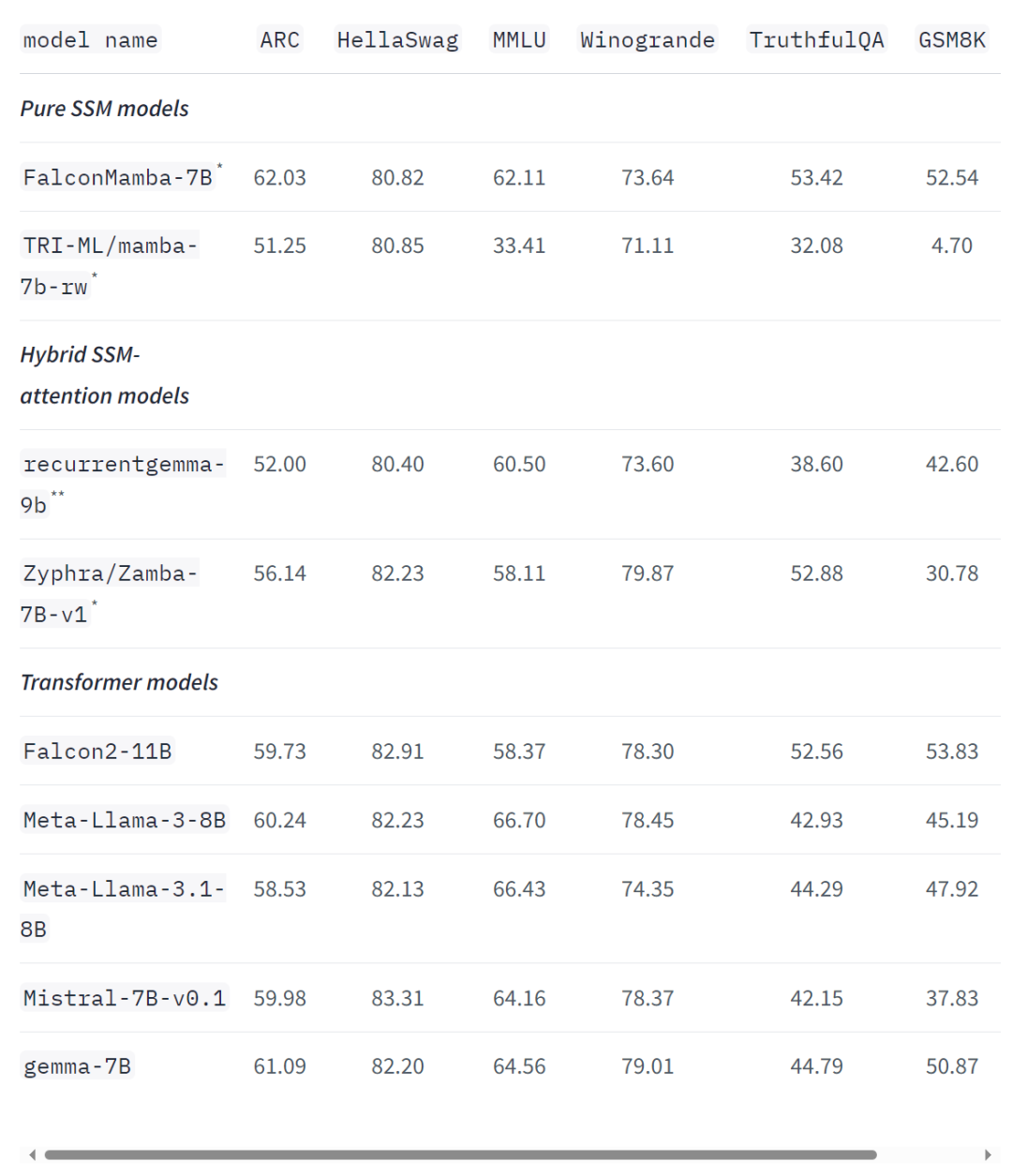
kekal malar. Keseluruhan latihan model mengambil masa kira-kira dua bulan. . panjang. Hasilnya menunjukkan bahawa Falcon Mamba mampu menyesuaikan diri dengan jujukan yang lebih besar daripada model Transformer semasa, manakala secara teorinya mampu menyesuaikan diri dengan panjang konteks tanpa had. Seterusnya, penyelidik mengukur daya pengeluaran penjanaan model menggunakan saiz kelompok 1 dan tetapan perkakasan H100 GPU. Keputusan ditunjukkan dalam rajah di bawah, Falcon Mamba menjana semua token pada daya pemprosesan berterusan tanpa sebarang peningkatan dalam memori puncak CUDA. Untuk model Transformer, memori puncak meningkat dan kelajuan penjanaan menjadi perlahan apabila bilangan token yang dijana meningkat. Malah pada penanda aras industri standard, model baharu ini berprestasi lebih baik daripada atau hampir dengan model pengubah popular serta model ruang keadaan tulen dan hibrid. 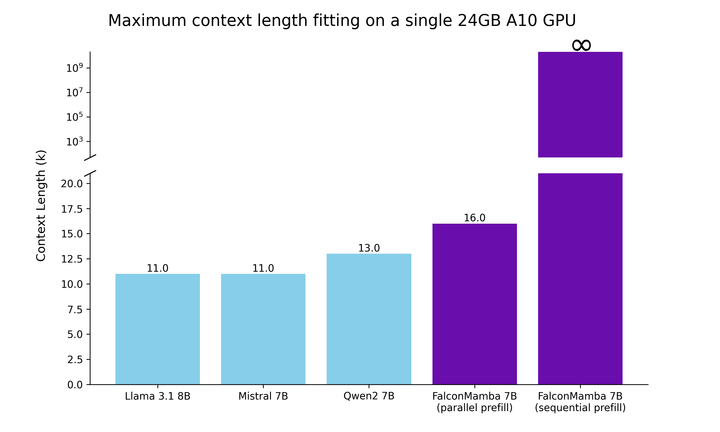 Sebagai contoh, dalam penanda aras Arc, TruthfulQA dan GSM8K, Falcon Mamba 7B masing-masing memperoleh 62.03%, 53.42% dan 52.54%, mengatasi Llama 3 8B, Llama 78B, Mistral 78B dan Mistral 3.1 Walau bagaimanapun, Falcon Mamba 7B jauh ketinggalan di belakang model ini dalam penanda aras MMLU dan Hellaswag.
Sebagai contoh, dalam penanda aras Arc, TruthfulQA dan GSM8K, Falcon Mamba 7B masing-masing memperoleh 62.03%, 53.42% dan 52.54%, mengatasi Llama 3 8B, Llama 78B, Mistral 78B dan Mistral 3.1 Walau bagaimanapun, Falcon Mamba 7B jauh ketinggalan di belakang model ini dalam penanda aras MMLU dan Hellaswag.
Penyiasat utama TII Hakim Hacid berkata dalam satu kenyataan: Pelancaran Falcon Mamba 7B mewakili satu langkah besar ke hadapan bagi agensi itu, memberi inspirasi kepada perspektif baharu dan memajukan dorongan untuk penerokaan sistematik perisikan. Di TII, mereka menolak sempadan SSLM dan model transformer untuk memberi inspirasi kepada inovasi selanjutnya dalam AI generatif.
Pada masa ini, keluarga model bahasa Falcon TII telah dimuat turun lebih daripada 45 juta kali – menjadikannya salah satu versi LLM yang paling berjaya di UAE.
 Kertas Falcon Mamba 7B akan dikeluarkan tidak lama lagi, anda boleh tunggu sebentar.
Kertas Falcon Mamba 7B akan dikeluarkan tidak lama lagi, anda boleh tunggu sebentar.
https://huggingface.co/blog/falconmamba
-senibina-ai-baru-menawarkan-model-alternatif-kepada-transformer/以上是非Transformer架构站起来了!首个纯无注意力大模型,超越开源巨头Llama 3.1的详细内容。更多信息请关注PHP中文网其他相关文章!






















