

大模型对语言有自己的理解!MIT 论文揭示大模型'思维过程”

Große Modelle können Ihr eigenes Verständnis der realen Welt entwickeln!
Eine Studie des MIT ergab, dass mit zunehmender Leistungsfähigkeit eines Modells sein Verständnis der Realität möglicherweise über die bloße Nachahmung hinausgeht.
Wenn das große Model beispielsweise noch nie einen Geruch gerochen hat, bedeutet das dann, dass es Gerüche nicht verstehen kann?
Untersuchungen haben ergeben, dass einige Konzepte spontan simuliert werden können, um das Verständnis zu erleichtern.
Diese Forschung bedeutet, dass von großen Modellen in Zukunft ein tieferes Verständnis der Sprache und der Welt erwartet wird. Das Papier wurde von der Spitzenkonferenz ICML 24 angenommen.

Die Autoren dieses Papiers sind der chinesische Doktorand Charles Jin und sein Betreuer Professor Martin Rinard vom MIT Computer and Artificial Intelligence Laboratory (CSAIL).
In der Studie bat der Autor das große Modell, nur den Codetext zu lernen, und stellte fest, dass das Modell nach und nach die Bedeutung dahinter erfasste.
Professor Rinard sagte, dass diese Forschung direkt eine Kernfrage der modernen künstlichen Intelligenz anspricht –
Ob die Fähigkeiten großer Modelle einfach auf groß angelegten statistischen Korrelationen beruhen oder ob sie ein aussagekräftiges Verständnis der realen Probleme generieren, um die es sich dabei handelt beabsichtigt zu lösen?
△Quelle: Offizielle Website des MIT
Gleichzeitig löste diese Forschung auch viele Diskussionen aus.
Einige Internetnutzer sagten, dass große Modelle zwar Sprache anders verstehen als Menschen, diese Studie aber zumindest zeigt, dass das Modell mehr kann, als nur Trainingsdaten zu speichern.

Lassen Sie das große Modell reinen Code lernen
Um zu untersuchen, ob das große Modell ein Verständnis auf semantischer Ebene erzeugen kann, erstellte der Autor einen synthetischen Datensatz, der aus Programmcode und den entsprechenden Eingaben und Ausgaben besteht.
Diese Codeprogramme sind in einer Lehrsprache namens Karel geschrieben und werden hauptsächlich zur Umsetzung der Aufgabe von Robotern verwendet, die in einer 2D-Gitterwelt navigieren.
Diese Gitterwelt besteht aus 8x8 Gittern, jedes Gitter kann Hindernisse, Markierungen oder offene Räume enthalten. Der Roboter kann sich zwischen Gittern bewegen und Vorgänge wie das Platzieren/Aufnehmen von Markierungen ausführen.
Karel-Sprache enthält 5 Grundoperationen – move (einen Schritt vorwärts), turnLeft (um 90 Grad nach links drehen), turnRight (um 90 Grad nach rechts drehen), pickMarker (Marker aufnehmen), putMarker (Marker platzieren), aus denen das Programm besteht Eine Folge dieser primitiven Operationen.
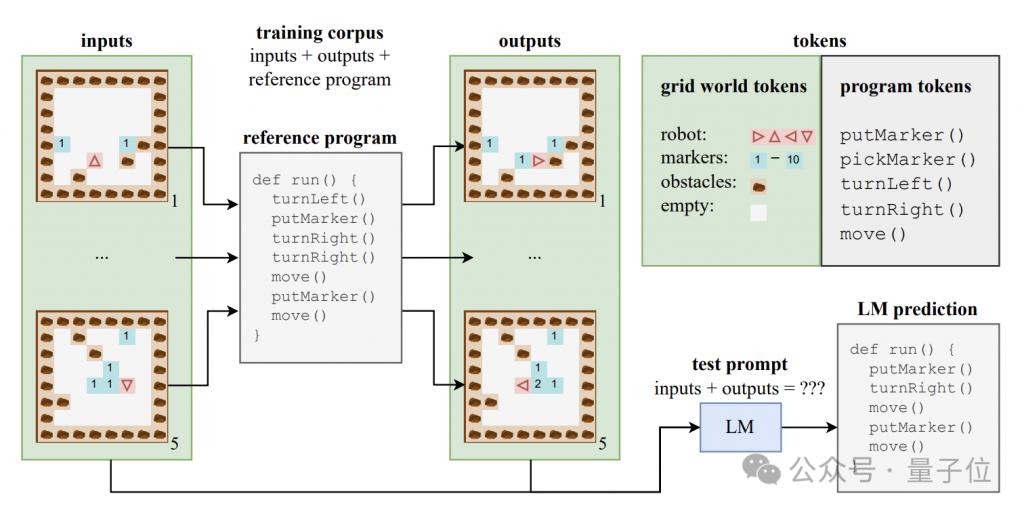
Der Autor hat zufällig einen Trainingssatz mit 500.000 Karel-Programmen generiert, wobei jedes Programm eine Länge zwischen 6 und 10 hat.
Jedes Trainingsbeispiel besteht aus drei Teilen: 5 Eingabezustände, 5 Ausgabezustände und vollständiger Programmcode. Die Eingabe- und Ausgabezustände werden in einem bestimmten Format in Zeichenfolgen codiert.
Anhand dieser Daten trainierten die Autoren eine Variante des CodeGen-Modells der Standard-Transformer-Architektur.
Während des Trainingsprozesses kann das Modell auf die Eingabe- und Ausgabeinformationen und Programmpräfixe in jedem Beispiel zugreifen, es kann jedoch nicht den vollständigen Verlauf und die Zwischenzustände der Programmausführung sehen.
Zusätzlich zum Trainingssatz hat der Autor auch einen Testsatz mit 10.000 Proben erstellt, um die Generalisierungsleistung des Modells zu bewerten.
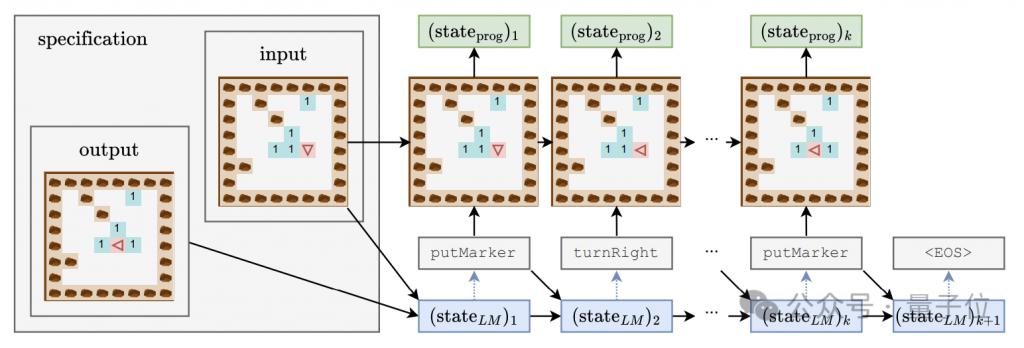
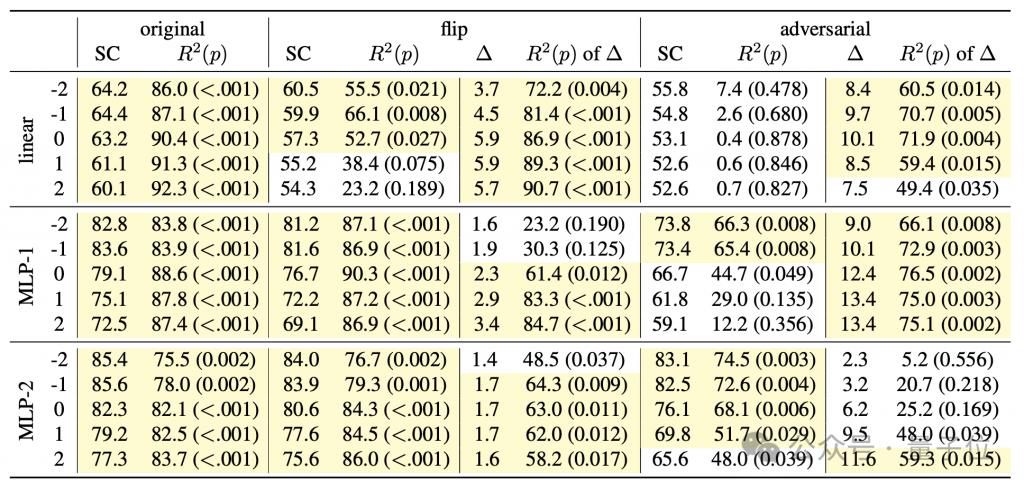
Um zu untersuchen, ob das Sprachmodell die Semantik hinter dem Code erfasst, und gleichzeitig ein tiefes Verständnis des „Denkprozesses“ des Modells zu erlangen, entwarf der Autor eine Detektorkombination, die einen linearen Klassifikator und einen einfachen/doppelten versteckten Klassifikator umfasst Schicht MLP.
Die Eingabe des Detektors ist der verborgene Zustand des Sprachmodells beim Generieren von Programm-Tokens, und das Vorhersageziel ist der Zwischenzustand der Programmausführung, insbesondere einschließlich der Ausrichtung (Richtung) des Roboters, versetzt relativ zur Anfangsposition (Position) und ob die Vorderseite dem Hindernis (Hindernis) zugewandt ist, sind diese drei Merkmale.
Während des Trainingsprozesses des generativen Modells zeichnete der Autor alle 4000 Schritte die oben genannten drei Merkmale auf und zeichnete auch den verborgenen Zustand des generativen Modells auf, um einen Trainingsdatensatz für den Detektor zu bilden.
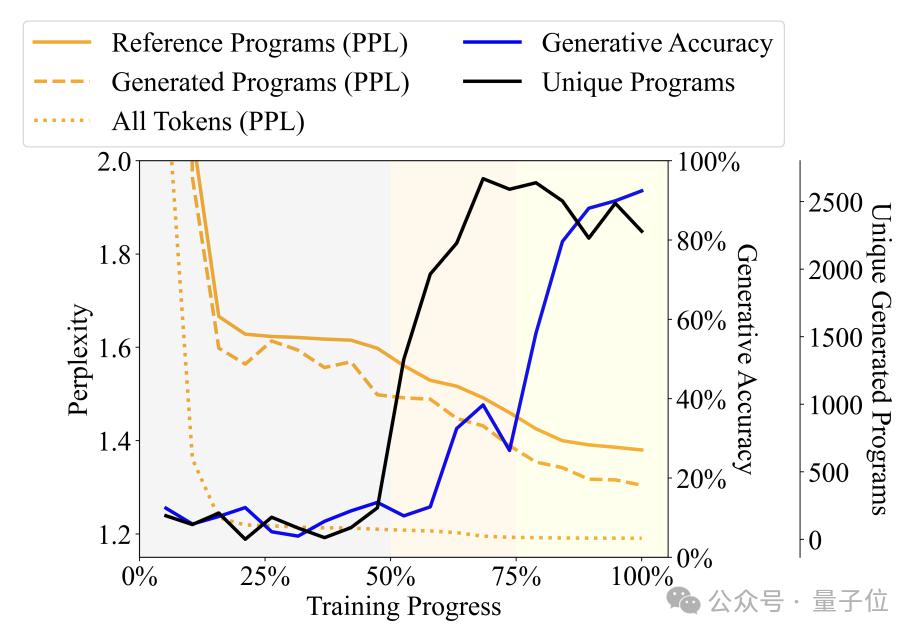
Drei Phasen des Lernens mit großen Modellen
Durch Beobachtung der Veränderungen in der Vielfalt, Verwirrung und anderen Indikatoren der vom Sprachmodell während des Trainingsprozesses generierten Programme hat der Autor den Trainingsprozess in drei Phasen unterteilt -
Phase des Plapperns (Unsinn): Das Ausgabeprogramm wiederholt sich stark und die Genauigkeit des Detektors ist instabil.
Grammatikerwerbsphase: Die Programmvielfalt nimmt schnell zu, die Generierungsgenauigkeit nimmt leicht zu und die Verwirrung nimmt ab, was darauf hinweist, dass das Sprachmodell die syntaktische Struktur des Programms gelernt hat.
Semantische Erfassungsphase: Der Grad der Programmvielfalt und die Beherrschung der syntaktischen Struktur sind stabil, aber die Generierungsgenauigkeit und die Detektorleistung sind erheblich verbessert, was darauf hinweist, dass das Sprachmodell die Semantik des Programms gelernt hat.
具体来说,Babbling 阶段占据了整个训练过程的前50%,例如在训练到20% 左右的时候,无论输入什么规范,模型都只会生成一个固定的程序—— "pickMarker" 重复9 次。
语法习得阶段处于训练过程的50% 到75%,模型在Karel 程序上的困惑度显着下降,表明语言模型开始更好地适应Karel 程序的统计特性,但生成程序的准确率提升幅度不大(从10% 左右提升到25% 左右),仍然无法准确完成任务。
语义习得阶段是最后的 25%,程序的准确率出现了急剧提升,从 25% 左右提升到 90% 以上,生成的程序能够准确地完成给定的任务。
进一步实验又发现,探测器不仅可以对 t 时刻的同时间步进行预测,还能预测后续时间步的程序执行状态。
举例来说,假设生成模型在 t 时刻生成了 token"move",并将在 t+1 时刻生成 "turnLeft"。
与此同时,t 时刻的程序状态是机器人面向北方,位于坐标 ( 0,0 ) ,而 t+1 时刻机器人将是机器人将面向西方,位置不变。
如果探测器能够从语言模型在t 时刻的隐藏状态中,成功预测到t+1 时刻机器人会面向西方,就说明在生成"turnLeft" 之前,隐藏状态就已经包含了这一操作带来的状态变化信息。
这一现象说明,模型并非只对已生成的程序部分有语义理解,而是在生成每一步时,就已经对接下来要生成的内容有所预期和规划,显现出了初步的面向未来的推理能力。
但这一发现又给这项研究带来了新的问题——
实验中观察到的准确度提升,到底真的是生成模型进步了,还是探测器自己推论的结果呢?
为了解决这个疑惑,作者补充了语义探测干预实验。
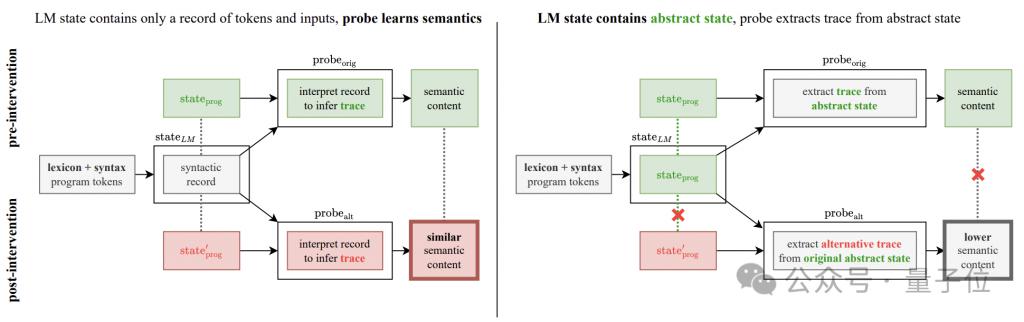
实验的基本思路是改变程序操作的语义解释规则,具体又分为 "flip" 和 "adversarial" 两种方式。
"flip" 是强行反转指令含义,如将"turnRight" 强行解释为" 左转" 不过能进行这种反转的也只有"turnLeft" 和"turnRight";#🎜 🎜#
"adversarial" 则是将所有指令对应的语义随机打乱,具体方式如下方表格。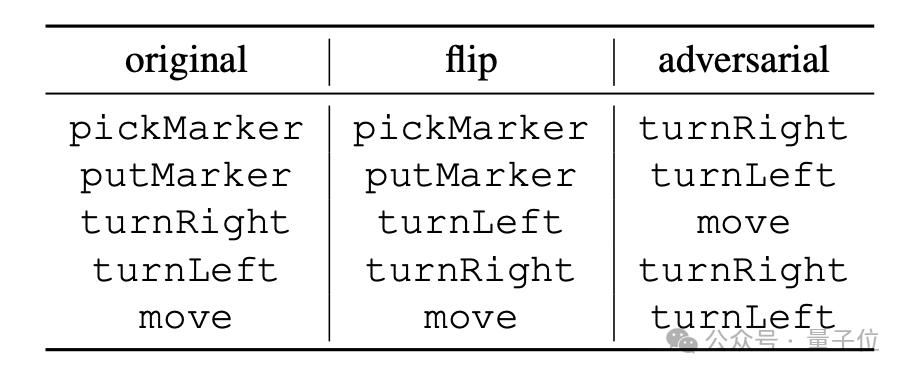
# 🎜🎜# [ 1 ] https://news.mit.edu/2024/llms-develop-own-understanding-of-reality-as-language-abilities-improve-0814
[ 2 ] https://www.reddit.com/r/LocalLLaMA/comments/1esxkin/llms_develop_their_own_understanding_of_reality/
以上是大模型对语言有自己的理解!MIT 论文揭示大模型'思维过程”的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 全球最强开源 MoE 模型来了,中文能力比肩 GPT-4,价格仅为 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
全球最强开源 MoE 模型来了,中文能力比肩 GPT-4,价格仅为 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
想象一下,一个人工智能模型,不仅拥有超越传统计算的能力,还能以更低的成本实现更高效的性能。这不是科幻,DeepSeek-V2[1],全球最强开源MoE模型来了。DeepSeek-V2是一个强大的专家混合(MoE)语言模型,具有训练经济、推理高效的特点。它由236B个参数组成,其中21B个参数用于激活每个标记。与DeepSeek67B相比,DeepSeek-V2性能更强,同时节省了42.5%的训练成本,减少了93.3%的KV缓存,最大生成吞吐量提高到5.76倍。DeepSeek是一家探索通用人工智
 AI颠覆数学研究!菲尔兹奖得主、华裔数学家领衔11篇顶刊论文|陶哲轩转赞
Apr 09, 2024 am 11:52 AM
AI颠覆数学研究!菲尔兹奖得主、华裔数学家领衔11篇顶刊论文|陶哲轩转赞
Apr 09, 2024 am 11:52 AM
AI,的确正在改变数学。最近,一直十分关注这个议题的陶哲轩,转发了最近一期的《美国数学学会通报》(BulletinoftheAmericanMathematicalSociety)。围绕「机器会改变数学吗?」这个话题,众多数学家发表了自己的观点,全程火花四射,内容硬核,精彩纷呈。作者阵容强大,包括菲尔兹奖得主AkshayVenkatesh、华裔数学家郑乐隽、纽大计算机科学家ErnestDavis等多位业界知名学者。AI的世界已经发生了天翻地覆的变化,要知道,其中很多文章是在一年前提交的,而在这一
 谷歌狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理训练最快选择
Apr 01, 2024 pm 07:46 PM
谷歌狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理训练最快选择
Apr 01, 2024 pm 07:46 PM
谷歌力推的JAX在最近的基准测试中性能已经超过Pytorch和TensorFlow,7项指标排名第一。而且测试并不是在JAX性能表现最好的TPU上完成的。虽然现在在开发者中,Pytorch依然比Tensorflow更受欢迎。但未来,也许有更多的大模型会基于JAX平台进行训练和运行。模型最近,Keras团队为三个后端(TensorFlow、JAX、PyTorch)与原生PyTorch实现以及搭配TensorFlow的Keras2进行了基准测试。首先,他们为生成式和非生成式人工智能任务选择了一组主流
 你好,电动Atlas!波士顿动力机器人复活,180度诡异动作吓坏马斯克
Apr 18, 2024 pm 07:58 PM
你好,电动Atlas!波士顿动力机器人复活,180度诡异动作吓坏马斯克
Apr 18, 2024 pm 07:58 PM
波士顿动力Atlas,正式进入电动机器人时代!昨天,液压Atlas刚刚「含泪」退出历史舞台,今天波士顿动力就宣布:电动Atlas上岗。看来,在商用人形机器人领域,波士顿动力是下定决心要和特斯拉硬刚一把了。新视频放出后,短短十几小时内,就已经有一百多万观看。旧人离去,新角色登场,这是历史的必然。毫无疑问,今年是人形机器人的爆发年。网友锐评:机器人的进步,让今年看起来像人类的开幕式动作、自由度远超人类,但这真不是恐怖片?视频一开始,Atlas平静地躺在地上,看起来应该是仰面朝天。接下来,让人惊掉下巴
 替代MLP的KAN,被开源项目扩展到卷积了
Jun 01, 2024 pm 10:03 PM
替代MLP的KAN,被开源项目扩展到卷积了
Jun 01, 2024 pm 10:03 PM
本月初,来自MIT等机构的研究者提出了一种非常有潜力的MLP替代方法——KAN。KAN在准确性和可解释性方面表现优于MLP。而且它能以非常少的参数量胜过以更大参数量运行的MLP。比如,作者表示,他们用KAN以更小的网络和更高的自动化程度重现了DeepMind的结果。具体来说,DeepMind的MLP有大约300,000个参数,而KAN只有约200个参数。KAN与MLP一样具有强大的数学基础,MLP基于通用逼近定理,而KAN基于Kolmogorov-Arnold表示定理。如下图所示,KAN在边上具
 特斯拉机器人进厂打工,马斯克:手的自由度今年将达到22个!
May 06, 2024 pm 04:13 PM
特斯拉机器人进厂打工,马斯克:手的自由度今年将达到22个!
May 06, 2024 pm 04:13 PM
特斯拉机器人Optimus最新视频出炉,已经可以在厂子里打工了。正常速度下,它分拣电池(特斯拉的4680电池)是这样的:官方还放出了20倍速下的样子——在小小的“工位”上,拣啊拣啊拣:这次放出的视频亮点之一在于Optimus在厂子里完成这项工作,是完全自主的,全程没有人为的干预。并且在Optimus的视角之下,它还可以把放歪了的电池重新捡起来放置,主打一个自动纠错:对于Optimus的手,英伟达科学家JimFan给出了高度的评价:Optimus的手是全球五指机器人里最灵巧的之一。它的手不仅有触觉
 FisheyeDetNet:首个基于鱼眼相机的目标检测算法
Apr 26, 2024 am 11:37 AM
FisheyeDetNet:首个基于鱼眼相机的目标检测算法
Apr 26, 2024 am 11:37 AM
目标检测在自动驾驶系统当中是一个比较成熟的问题,其中行人检测是最早得以部署算法之一。在多数论文当中已经进行了非常全面的研究。然而,利用鱼眼相机进行环视的距离感知相对来说研究较少。由于径向畸变大,标准的边界框表示在鱼眼相机当中很难实施。为了缓解上述描述,我们探索了扩展边界框、椭圆、通用多边形设计为极坐标/角度表示,并定义一个实例分割mIOU度量来分析这些表示。所提出的具有多边形形状的模型fisheyeDetNet优于其他模型,并同时在用于自动驾驶的Valeo鱼眼相机数据集上实现了49.5%的mAP
 牛津大学最新!Mickey:3D中的2D图像匹配SOTA!(CVPR\'24)
Apr 23, 2024 pm 01:20 PM
牛津大学最新!Mickey:3D中的2D图像匹配SOTA!(CVPR\'24)
Apr 23, 2024 pm 01:20 PM
写在前面项目链接:https://nianticlabs.github.io/mickey/给定两张图片,可以通过建立图片之间的对应关系来估计它们之间的相机姿态。通常,这些对应关系是二维到二维的,而我们估计的姿态在尺度上是不确定的。一些应用,例如随时随地实现即时增强现实,需要尺度度量的姿态估计,因此它们依赖于外部的深度估计器来恢复尺度。本文提出了MicKey,这是一个关键点匹配流程,能够够预测三维相机空间中的度量对应关系。通过学习跨图像的三维坐标匹配,我们能够在没有深度测试的情况下推断出度量相对
