
结构化查询语言或 SQL 是一种标准数据库语言,用于从 MySQL、Oracle、SQL Server、PostgreSQL 等关系数据库中创建、维护、销毁、更新和检索数据。
它是一个用于描述数据库中数据结构的概念框架。它旨在以更抽象的方式表示现实世界的实体及其之间的关系。这类似于编程语言的面向对象编程。
实体:这些是现实世界中具有独特存在的对象或“事物”,例如客户、产品或订单。
关系: 这些定义实体如何相互关联。例如,“客户”实体可能与“订单”实体有关系
命令:
create database <database_name>;
show databases;
use <database_name>
DESCRIBE table_name;
用于对数据执行查询的语言。该命令用于从数据库中检索数据。
命令:
1) 选择:
select * from table_name; select column1,column2 from table_name; select * from table_name where column1 = "value";
用于定义数据库模式的语言。该命令用于创建、修改和删除数据库,但不用于数据。
命令
1) 创建:
create table table_name( column_name data_type(size) constraint, column_name data_type(size) constraint column_name data_type(size) constraint );
2) 掉落:
此命令完全删除表/数据库。
drop table table_name; drop database database_name;
3) 截断:
此命令仅删除数据。
truncate table table_name;
4) 更改:
该命令可以添加、删除或更新表的列。
添加
alter table table_name add column_name datatype;
修改
alter table table_name modify column column_name datatype; --ALTER TABLE employees --MODIFY COLUMN salary DECIMAL(10,2);
掉落
alter table table_name drop column_name datatype;
用于操作数据库中存在的数据的语言。
1) 插入:
该命令用于仅插入新值。
insert into table_name values (val1,val2,val3,val4); //4 columns
2)更新:
update table_name set col1=val1, col2=val2 where col3 = val3;
3) 删除:
delete from table_name where col1=val1;
GRANT:允许指定用户执行指定任务。
REVOKE:取消先前授予或拒绝的权限。
它用于管理数据库中的事务。它管理 DML 命令所做的更改。
1) 提交
用于将当前事务期间所做的所有更改保存到数据库
BEGIN TRANSACTION; UPDATE employees SET salary = salary * 1.1 WHERE department = 'Sales'; COMMIT;
2) 回滚
它用于撤消当前事务期间所做的所有更改
BEGIN TRANSACTION; UPDATE employees SET salary = salary * 1.1 WHERE department = 'Sales'; ROLLBACK;
3) 保存点
begin transaction; update customers set first_name= 'one' WHERE customer_id=4; SAVEPOINT one; update customers set first_name= 'two' WHERE customer_id=4; ROLLBACK TO SAVEPOINT one; COMMIT;
此命令用于根据聚合函数过滤结果。“我们不能在 WHERE 语句中使用聚合函数,因此我们可以在此命令中使用”
注意:当我们需要使用组成列进行比较时可以使用此命令,而 WHERE 命令可用于使用现有列进行比较
select Department, sum(Salary) as Salary from employee group by department having sum(Salary) >= 50000;
当他们要求排除任何两个/更多特定项目时使用此命令
select * from table_name
where colname not in ('Germany', 'France', 'UK');
此命令用于根据所选字段仅检索唯一数据。
Select distinct field from table;
SELECT COUNT(DISTINCT salesman_id) FROM orders;
它是一个子查询(嵌套在另一个查询中的查询),引用外部查询中的列
SELECT EmployeeName, Salary
FROM Employees e1
WHERE Salary > (
SELECT AVG(Salary)
FROM Employees e2
WHERE e1.DepartmentID = e2.DepartmentID
);
标准化是一种数据库设计技术,用于以减少冗余并提高数据完整性的方式组织表。规范化的主要目标是将大表划分为更小、更易于管理的部分,同时保留数据之间的关系
第一范式 (1NF)
列中的所有值都是原子的(不可分割的)。
每列仅包含一种类型的数据。
EmployeeID | EmployeeName | Department | PhoneNumbers ---------------------------------------------------- 1 | Alice | HR | 123456, 789012 2 | Bob | IT | 345678
1NF之后:
EmployeeID | EmployeeName | Department | PhoneNumber ---------------------------------------------------- 1 | Alice | HR | 123456 1 | Alice | HR | 789012 2 | Bob | IT | 345678
第二范式 (2NF)
它位于 1NF。
所有非键属性在功能上完全依赖于主键(没有部分依赖)。
EmployeeID | EmployeeName | DepartmentID | DepartmentName --------------------------------------------------------- 1 | Alice | 1 | HR 2 | Bob | 2 | IT
2NF之后:
EmployeeID | EmployeeName | DepartmentID --------------------------------------- 1 | Alice | 1 2 | Bob | 2 DepartmentID | DepartmentName ------------------------------ 1 | HR 2 | IT
第三范式(3NF)
它位于 2NF。
所有属性在功能上仅依赖于主键(无传递依赖)。
EmployeeID | EmployeeN | DepartmentID | Department | DepartmentLocation -------------------------------------------------------------------------- 1 | Alice | 1 | HR | New York 2 | Bob | 2 | IT | Los Angeles
3NF之后:
EmployeeID | EmployeeN | DepartmentID ---------------------------------------- 1 | Alice | 1 2 | Bob | 2 DepartmentID | DepartmentName | DepartmentLocation ----------------------------------------------- 1 | HR | New York 2 | IT | Los Angeles
此命令用于组合两个或多个 SELECT 语句的结果
Select * from table_name WHERE (subject = 'Physics' AND year = 1970) UNION (SELECT * FROM nobel_win WHERE (subject = 'Economics' AND year = 1971));
此命令用于限制从查询中检索的数据量。
select Department, sum(Salary) as Salary from employee limit 2;
该命令用于在返回结果之前跳过行数。
select Department, sum(Salary) as Salary from employee limit 2 offset 2;
This command is used to sort the data based on the field in ascending or descending order.
Data:
create table employees (
id int primary key,
first_name varchar(50),
last_name varchar(50),
salary decimal(10, 2),
department varchar(50)
);
insert into employees (first_name, last_name, salary, department)
values
('John', 'Doe', 50000.00, 'Sales'),
('Jane', 'Smith', 60000.00, 'Marketing'),
('Jim', 'Brown', 60000.00, 'Sales'),
('Alice', 'Johnson', 70000.00, 'Marketing');
select * from employees order by department; select * from employees order by salary desc
This command is used to test for empty values
select * from tablename where colname IS NULL;
This command is used to arrange similar data into groups using a function.
select department, avg(salary) AS avg_salary from employees group by department;
This command is used to search a particular pattern in a column.

SELECT * FROM employees WHERE first_name LIKE 'a%';
SELECT * FROM salesman WHERE name BETWEEN 'A' AND 'L';
Characters used with the LIKE operator to perform pattern matching in string searches.
% - Percent
_ - Underscore
SELECT 'It\'s a beautiful day';
SELECT * FROM table_name WHERE column_name LIKE '%50!%%' ESCAPE '!';
The CASE statement in SQL is used to add conditional logic to queries. It allows you to return different values based on different conditions.
SELECT first_name, last_name, salary,
CASE salary
WHEN 50000 THEN 'Low'
WHEN 60000 THEN 'Medium'
WHEN 70000 THEN 'High'
ELSE 'Unknown'
END AS salary_category
FROM employees;
1) Print something
Select "message";
select ' For', ord_date, ',there are', COUNT(ord_no) group by colname;
2) Print numbers in each column
Select 1,2,3;
3) Print some calculation
Select 6x2-1;
4) Print wildcard characters
select colname1,'%',colname2 from tablename;
5) Connect two colnames
select first_name || ' ' || last_name AS colname from employees
6) Use the nth field
select * from orders group by colname order by 2 desc;
1) Not Null:
This constraint is used to tell the field that it cannot have null value in a column.
create table employees(
id int(6) not null
);
2) Unique:
This constraint is used to tell the field that it cannot have duplicate value. It can accept NULL values and multiple unique constraints are allowed per table.
create table employees (
id int primary key,
first_name varchar(50) unique
);
3) Primary Key:
This constraint is used to tell the field that uniquely identifies in the table. It cannot accept NULL values and it can have only one primary key per table.
create table employees (
id int primary key
);
4) Foreign Key:
This constraint is used to refer the unique row of another table.
create table employees (
id int primary key
foreign key (id) references owner(id)
);
5) Check:
This constraint is used to check a particular condition for data to be stored.
create table employees (
id int primary key,
age int check (age >= 18)
);
6) Default:
This constraint is used to provide default value for a field.
create table employees (
id int primary key,
age int default 28
);
1)Count:
select count(*) as members from employees;
2)Sum:
select sum(salary) as total_amount FROM employees;
3)Average:
select avg(salary) as average_amount FROM employees;
4)Maximum:
select max(salary) as highest_amount FROM employees;
5)Minimum:
select min(salary) as lowest_amount FROM employees;
6)Round:
select round(123.4567, -2) as rounded_value;
1) datediff
select a.id from weather a join weather b on datediff(a.recordDate,b.recordDate)=1 where a.temperature > b.temperature;
2) date_add
select date_add("2017-06-15", interval 10 day);
SECOND
MINUTE
HOUR
DAY
WEEK
MONTH
QUARTER
YEAR
3) date_sub
SELECT DATE_SUB("2017-06-15", INTERVAL 10 DAY);
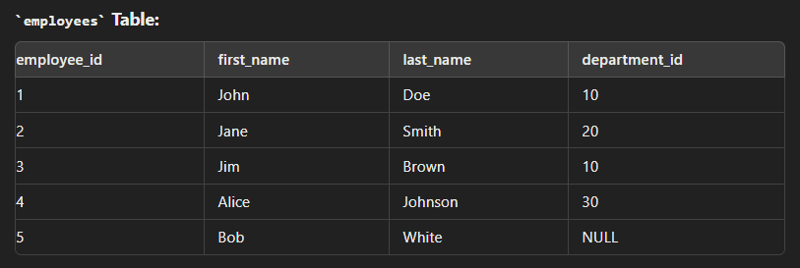
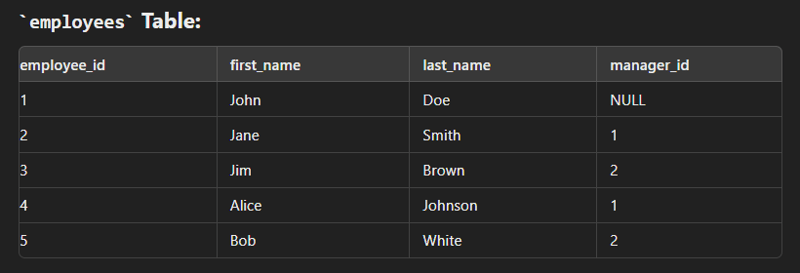
This is used to combine two tables based on one common column.
It returns only the rows where there is a match between both tables.
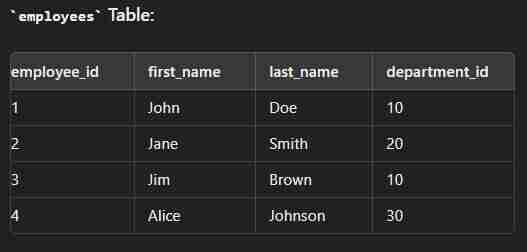
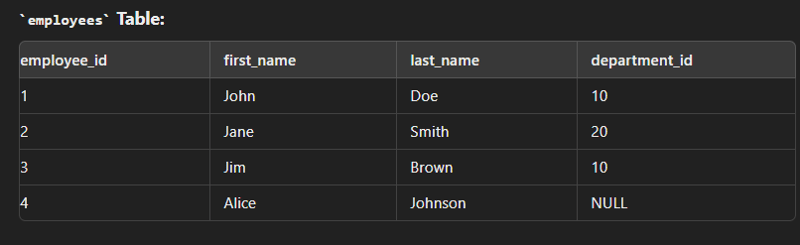
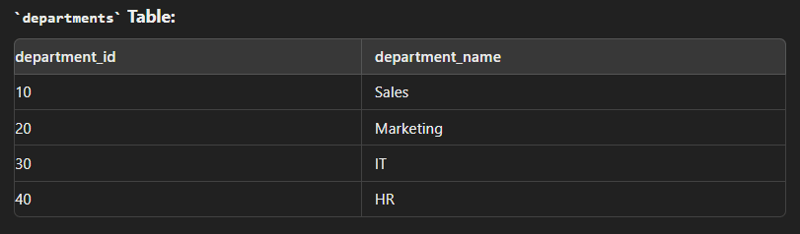
Data
create table employees( employee_id int(2) primary key, first_name varchar(30), last_name varchar(30), department_id int(2) ); create table department( department_id int(2) primary key, department_name varchar(30) ); insert into employees values (1,"John","Dow",10); insert into employees values (2,"Jane","Smith",20); insert into employees values (3,"Jim","Brown",10); insert into employees values (4,"Alice","Johnson",30); insert into department values (10,"Sales"); insert into department values (20,"Marketing"); insert into department values (30,"IT");
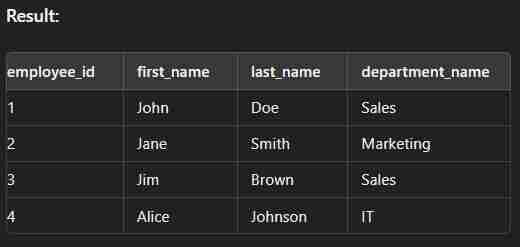
select e.employee_id,e.first_name,e.last_name,d.department_name from employees e inner join department d on e.department_id=d.department_id;
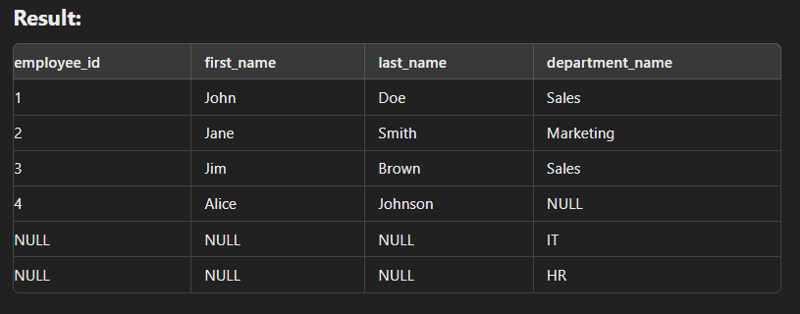
This type of join returns all rows from the left table along with the matching rows from the right table. Note: If there are no matching rows in the right side, it return null.
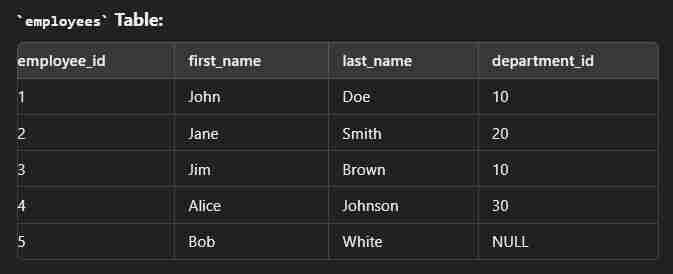
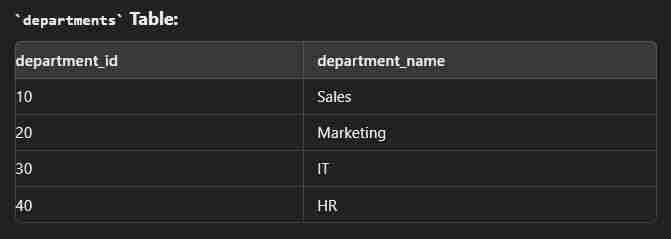
select e.employee_id, e.first_name, e.last_name, d.department_name from employees e left join departments d on e.department_id = d.department_id;
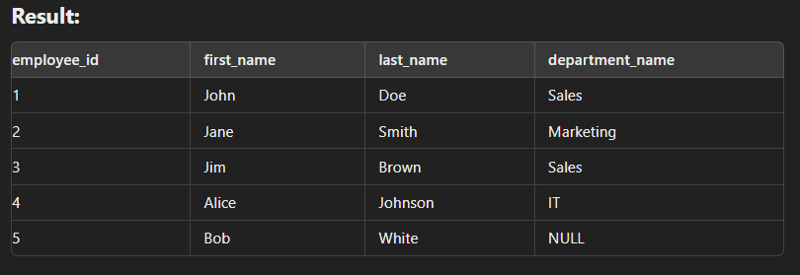
This type of join returns all rows from the right table along with the matching rows from the left table. Note: If there are no matching rows in the left side, it returns null.
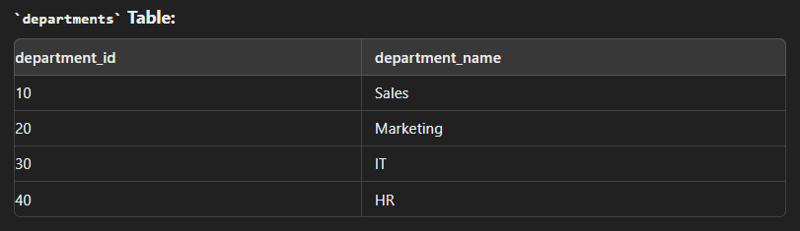
SELECT e.employee_id, e.first_name, e.last_name, d.department_name FROM employees e RIGHT JOIN departments d ON e.department_id = d.department_id;
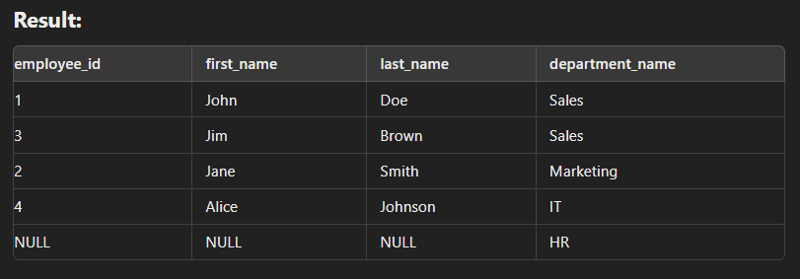
This type of join is used to combine with itself especially for creation of new column of same data.
SELECT e.employee_id AS employee_id,
e.first_name AS employee_first_name,
e.last_name AS employee_last_name,
m.first_name AS manager_first_name,
m.last_name AS manager_last_name
FROM employees e
LEFT JOIN employees m ON e.manager_id = m.employee_id;
This type of join is used to combine the result of both left and right join.
SELECT e.employee_id, e.first_name, e.last_name, d.department_name FROM employees e FULL JOIN departments d ON e.department_id = d.department_id;
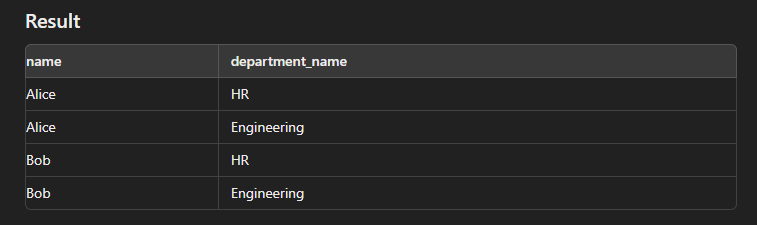
This type of join is used to generate a Cartesian product of two tables.
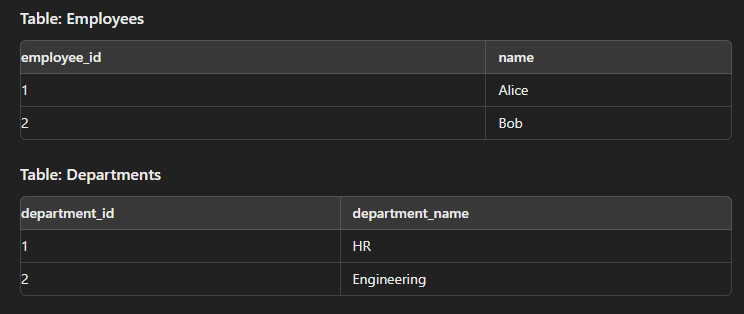
SELECT e.name, d.department_name FROM Employees e CROSS JOIN Departments d;
A nested query, also known as a subquery, is a query within another SQL query. The nested query is executed first, and its result is used by the outer query.
Subqueries can be used in various parts of a SQL statement, including the SELECT clause, FROM clause, WHERE clause, and HAVING clause.
1) Nested Query in SELECT Clause:
SELECT e.first_name, e.last_name,
(SELECT d.department_name
FROM departments d
WHERE d.id = e.department_id) AS department_name
FROM employees e;
2) Nested Query in WHERE Clause:
SELECT first_name, last_name, salary FROM employees WHERE salary > (SELECT AVG(salary) FROM employees);
SELECT pro_name, pro_price FROM item_mast WHERE pro_price = (SELECT MIN(pro_price) FROM item_mast);
3) Nested Query in FROM Clause:
SELECT department_id, AVG(salary) AS avg_salary FROM employees GROUP BY department_id;
4) Nested Query with EXISTS:
SELECT customer_name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
);
This command is used to test the existence of a particular record. Note: When using EXISTS query, actual data returned by subquery does not matter.
SELECT customer_name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
);
SELECT customer_name
FROM customers c
WHERE NOT EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
);
The COALESCE function in SQL is used to return the first non-null expression among its arguments. It is particularly useful for handling NULL values and providing default values when dealing with potentially missing or undefined data.
CREATE TABLE employees (
first_name VARCHAR(50),
middle_name VARCHAR(50),
last_name VARCHAR(50)
);
INSERT INTO employees (first_name, middle_name, last_name) VALUES
('John', NULL, 'Doe'),
('Jane', 'Marie', 'Smith'),
('Emily', NULL, 'Johnson');
SELECT
first_name,
COALESCE(middle_name, 'No Middle Name') AS middle_name,
last_name
FROM
employees;
It is Oracle's procedural extension to SQL. If multiple SELECT statements are issued, the network traffic increases significantly very fast. For example, four SELECT statements cause eight network trips. If these statements are part of the PL/SQL block, they are sent to the server as a single unit.
They are the fundamental units of execution and organization.
1) Named block
Named blocks are used when creating subroutines. These subroutines are procedures, functions, and packages. The subroutines can be stored in the database and referenced by their names later on.
Ex.
CREATE OR REPLACE PROCEDURE procedure_name (param1 IN datatype, param2 OUT datatype) AS BEGIN -- Executable statements END procedure_name;
2) Anonymous
They are blocks do not have names. As a result, they cannot be stored in the database and referenced later.
DECLARE -- Declarations (optional) BEGIN -- Executable statements EXCEPTION -- Exception handling (optional) END;
Declaration
It contains identifiers such as variables, constants, cursors etc
Ex.
declare v_first_name varchar2(35) ; v_last_name varchar2(35) ; v_counter number := 0 ; v_lname students.lname%TYPE; // takes field datatype from column
DECLARE v_student students%rowtype; BEGIN select * into v_student from students where sid='123456'; DBMS_OUTPUT.PUT_LINE(v_student.lname); DBMS_OUTPUT.PUT_LINE(v_student.major); DBMS_OUTPUT.PUT_LINE(v_student.gpa); END;
Execution
It contains executable statements that allow you to manipulate the variables.
declare v_regno number; v_variable number:=0; begin select regno into v_regno from student where regno=1; dbms_output.put_line(v_regno || ' '|| v_variable); end
DECLARE v_inv_value number(8,2); v_price number(8,2); v_quantity number(8,0) := 400; BEGIN v_price := :p_price; v_inv_value := v_price * v_quantity; dbms_output.put_line(v_inv_value); END;
IF rating > 7 THEN
v_message := 'You are great';
ELSIF rating >= 5 THEN
v_message := 'Not bad';
ELSE
v_message := 'Pretty bad';
END IF;
Simple Loop
declare
begin
for i in 1..5 loop
dbms_output.put_line('Value of i: ' || i);
end loop;
end;
While Loop
declare
counter number := 1;
begin
while counter <= 5 LOOP
dbms_output.put_line('Value of counter: ' || counter);
counter := counter + 1;
end loop;
end;
Loop with Exit
declare
counter number := 1;
begin
loop
exit when counter > 5;
dbms_output.put_line('Value of counter: ' || counter);
counter := counter + 1;
end loop;
end;
A series of statements accepting and/or returning
zero variables.
--creating a procedure create or replace procedure proc (var in number) as begin dbms_output.put_line(var); end --calling of procedure begin proc(3); end
A series of statements accepting zero or more variables that returns one value.
create or replace function func(var in number) return number is res number; begin select regno into res from student where regno=var; return res; end --function calling declare var number; begin var :=func(1); dbms_output.put_line(var); end
All types of I/O
p_name IN VARCHAR2 p_lname OUT VARCHAR2 p_salary IN OUT NUMBER
DML (Data Manipulation Language) triggers are fired in response to INSERT, UPDATE, or DELETE operations on a table or view.
BEFORE Triggers:
Execute before the DML operation is performed.
AFTER Triggers:
Execute after the DML operation is performed.
INSTEAD OF Triggers:
Execute in place of the DML operation, typically used for views.
Note: :new represents the cid of the new row in the orders table that was just inserted.
create or replace trigger t_name after update on student for each row begin dbms_output.put_line(:NEW.regno); end --after updation update student set name='name' where regno=1;
SELECT
id,name,gender,
ROW_NUMBER() OVER(
PARTITION BY name
order by gender
) AS row_number
FROM student;
SELECT
employee_id,
department_id,
salary,
RANK() OVER(
PARTITION BY department_id
ORDER BY salary DESC
) AS salary_rank
FROM employees;
Atomicity:
All operations within a transaction are treated as a single unit.
Ex. Consider a bank transfer where money is being transferred from one account to another. Atomicity ensures that if the debit from one account succeeds, the credit to the other account will also succeed. If either operation fails, the entire transaction is rolled back to maintain consistency.
一致性:
一致性保证数据库在事务前后保持一致的状态。
例如如果一笔转账交易减少了一个账户的余额,它也应该增加接收账户的余额。这维持了系统的整体平衡。
隔离:
隔离性确保事务的并发执行会产生一种系统状态,如果事务是串行执行的,即一个接一个地执行,则将获得该系统状态。
前任。考虑两个事务 T1 和 T2。如果 T1 将资金从账户 A 转账到账户 B,并且 T2 检查账户 A 的余额,则隔离可确保 T2 在转账之前(如果 T1 尚未提交)或转账之后(如果 T1 尚未提交)看到账户 A 的余额已提交),但不是中间状态。
耐用性:
持久性保证事务一旦提交,其影响是永久性的,并且不会出现系统故障。即使系统崩溃或重启,事务所做的更改也不会丢失。
1) 数字数据类型
int
decimal(p,q) - p 是大小,q 是精度
2) 字符串数据类型
char(value) - max(8000) && 不可变
varchar(值) - max(8000)
文本 - 最大尺寸
3) 日期数据类型
日期
时间
日期时间
以上是SQL面试完整指南的详细内容。更多信息请关注PHP中文网其他相关文章!





















