
在本文中,我们将探讨两种在 Java 中从堆栈中删除重复元素的方法。我们将比较使用 嵌套循环 的简单方法和使用 HashSet 的更有效方法。目标是演示如何优化重复删除并评估每种方法的性能。
编写一个Java程序,从堆栈中删除重复元素。
输入
雷雷输出
雷雷要从给定堆栈中删除重复项,我们有 2 种方法 -
下面是 Java 程序首先构建一个随机堆栈,然后创建它的副本以供进一步使用 -
initData 帮助创建一个具有指定大小和范围从 1 到 100 的随机元素的 Stack。
manualCloneStack 通过从另一个堆栈复制数据来帮助生成数据,用它来比较两种想法之间的性能。
以下是使用 Naïve 方法从给定堆栈中删除重复项的步骤 -
下面是使用 Naïve 方法从给定堆栈中删除重复项的 Java 程序 -
雷雷对于朴素的方法,我们使用
Stack<Integer> data = initData(10L);
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">Unique elements using Naive Approach: [1, 4, 3, 2, 8, 7, 5]
Time spent for Naive Approach: 18200 nanoseconds
Unique elements using Optimized Approach: [1, 4, 3, 2, 8, 7, 5]
Time spent for Optimized Approach: 34800 nanoseconds</pre><div class="contentsignin">登录后复制</div></div>
检查该元素是否已经存在。以下是使用优化方法从给定堆栈中删除重复项的步骤 -
下面是使用 HashSet 从给定堆栈中删除重复项的 Java 程序 -
雷雷为了优化方法,我们使用
private static Stack initData(Long size) {
Stack stack = new Stack < > ();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i < size; ++i) {
stack.add(random.nextInt(bound) + 1);
}
return stack;
}
private static Stack < Integer > manualCloneStack(Stack < Integer > stack) {
Stack < Integer > newStack = new Stack < > ();
for (Integer item: stack) {
newStack.push(item);
}
return newStack;
}以下是使用上述两种方法从给定堆栈中删除重复项的步骤 -
下面是使用上述两种方法从堆栈中删除重复元素的 Java 程序 -
雷雷输出
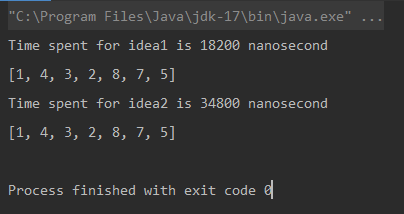
* 测量单位是纳秒。
public static void main(String[] args) {
Stack<Integer> data1 = initData(<number of stack size want to test>);
Stack<Integer> data2 = manualCloneStack(data1);
idea1(data1);
idea2(data2);
}| Method | 100 elements | 1000 elements |
10000 elements |
100000 elements |
1000000 elements |
| Idea 1 | 693100 |
4051600 |
19026900 |
114201800 |
1157256000 |
| Idea 2 | 135800 |
681400 |
2717800 |
11489400 |
36456100 |
As observed, the time running for Idea 2 is shorter than for Idea 1 because the complexity of Idea 1 is O(n²), while the complexity of Idea 2 is O(n). So, when the number of stacks increases, the time spent on calculations also increases based on it.
以上是Java程序从给定堆栈中删除重复项的详细内容。更多信息请关注PHP中文网其他相关文章!





















