

KDD2024最佳学生论文解读,中科大、华为诺亚:序列推荐新范式DR4SR


AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
8 月 25 日 - 29 日在西班牙巴塞罗那召开的第 30 届 ACM 知识发现与数据挖掘大会 (KDD2024) 上,中国科学技术大学认知智能全国重点实验室陈恩红教授、IEEE Fellow,和华为诺亚联合发表的论文 “Dataset Regeneration for Sequential Recommendation”,获 2024 年大会 Research Track 唯一最佳学生论文奖。论文第一作者为中科大认知智能全国重点实验室陈恩红教授,连德富教授,与王皓特任副研究员共同指导的博士生尹铭佳同学,华为诺亚刘勇、郭威研究员也参与了论文的相关工作。这是自 KDD 于 2004 年设立该奖项以来,陈恩红教授团队的学生第二次荣获该奖项。

论文链接: https://arxiv.org/abs/2405.17795 代码链接: https://github.com/USTC-StarTeam/DR4SR
 ,并基于
,并基于  学习用户偏好
学习用户偏好 。由于学习从
。由于学习从  的映射涉及两个隐含的映射:
的映射涉及两个隐含的映射: ,因此这一过程具有挑战性。为此,研究团队探索了开发一个显式表示中的物品转移模式的数据集的可能性,这使得我们可以将学习过程明确地分为两个阶段,其中
,因此这一过程具有挑战性。为此,研究团队探索了开发一个显式表示中的物品转移模式的数据集的可能性,这使得我们可以将学习过程明确地分为两个阶段,其中  相对更容易学习。因此,他们的主要关注点是学习一个有效的
相对更容易学习。因此,他们的主要关注点是学习一个有效的 的映射函数,这是一个一对多的映射。研究团队将这一学习过程定义为数据集重生成范式,如图 1 所示,其中 “重生成” 意味着他们不引入任何额外信息,仅依赖原始数据集。
的映射函数,这是一个一对多的映射。研究团队将这一学习过程定义为数据集重生成范式,如图 1 所示,其中 “重生成” 意味着他们不引入任何额外信息,仅依赖原始数据集。
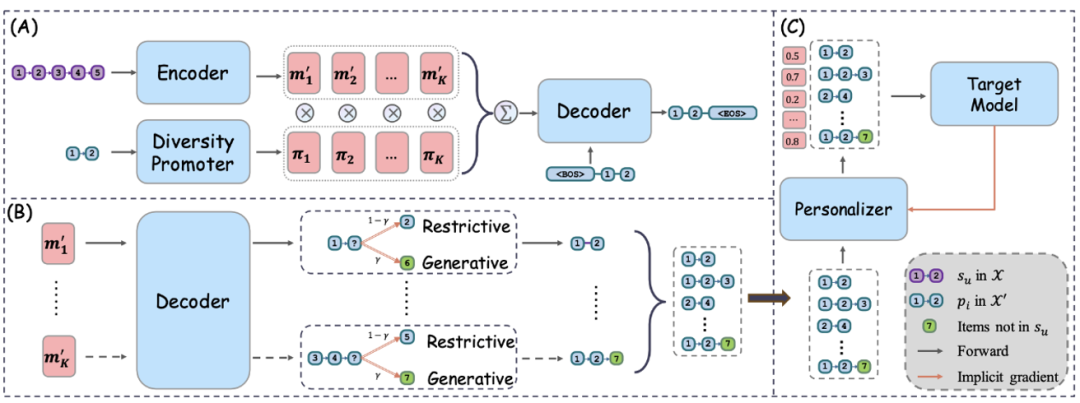


 Régénérateur qui favorise la diversité :
Régénérateur qui favorise la diversité : 

Avec tâches de pré-formation, les équipes de recherche peuvent désormais pré-former un régénérateur d'ensembles de données. Dans cet article, ils adoptent le modèle Transformer comme architecture principale du régénérateur, et sa capacité de génération a été largement vérifiée. Le régénérateur d'ensemble de données se compose de trois modules : un encodeur pour obtenir des représentations de séquence dans l'ensemble de données d'origine, un décodeur pour régénérer les modèles et un module d'amélioration de la diversité pour capturer les relations de mappage un à plusieurs. Ensuite, l'équipe de recherche présentera ces modules séparément.
L'encodeur se compose de plusieurs couches empilées d'auto-attention multi-têtes (MHSA) et de réseau à action directe (FFN). Quant au décodeur, il reproduira les modèles de l'ensemble de données X' en entrée. Le but du décodeur est de reconstruire le motif
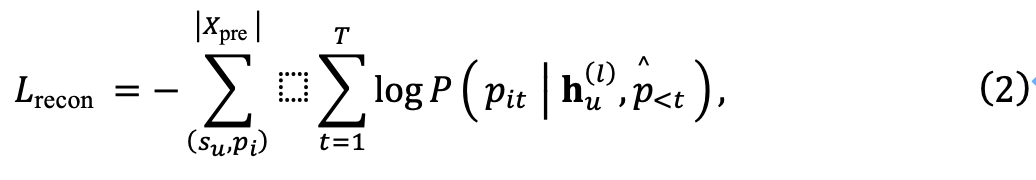
. Ils ont compressé



 où
où 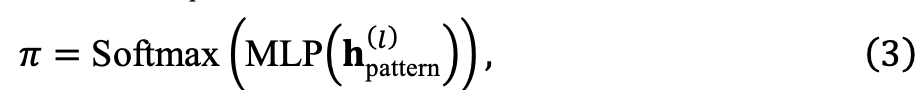
 mis en œuvre par MLP pour évaluer le score de chaque échantillon de données
mis en œuvre par MLP pour évaluer le score de chaque échantillon de données  W pour le modèle cible. Pour garantir la généralité du cadre, l’équipe de recherche a utilisé les scores calculés pour ajuster les poids des pertes d’entraînement, ce qui n’a pas nécessité de modifications supplémentaires du modèle cible. Ils commencent par définir la perte de prédiction de l'élément suivant d'origine :
W pour le modèle cible. Pour garantir la généralité du cadre, l’équipe de recherche a utilisé les scores calculés pour ajuster les poids des pertes d’entraînement, ce qui n’a pas nécessité de modifications supplémentaires du modèle cible. Ils commencent par définir la perte de prédiction de l'élément suivant d'origine : 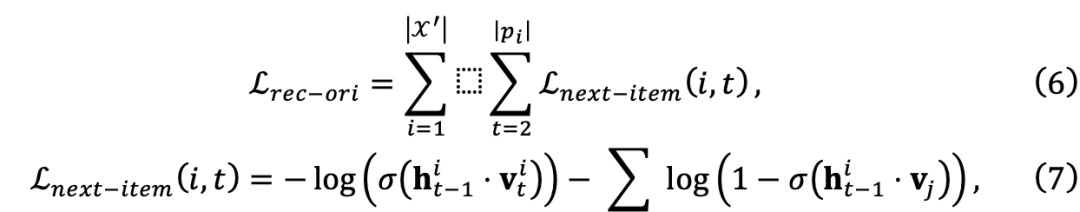
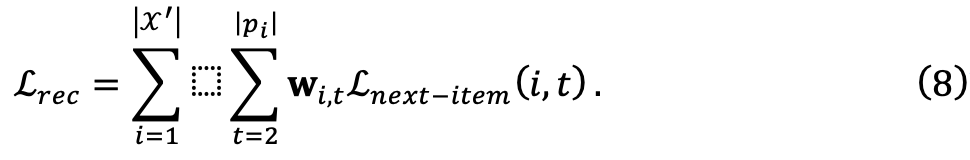
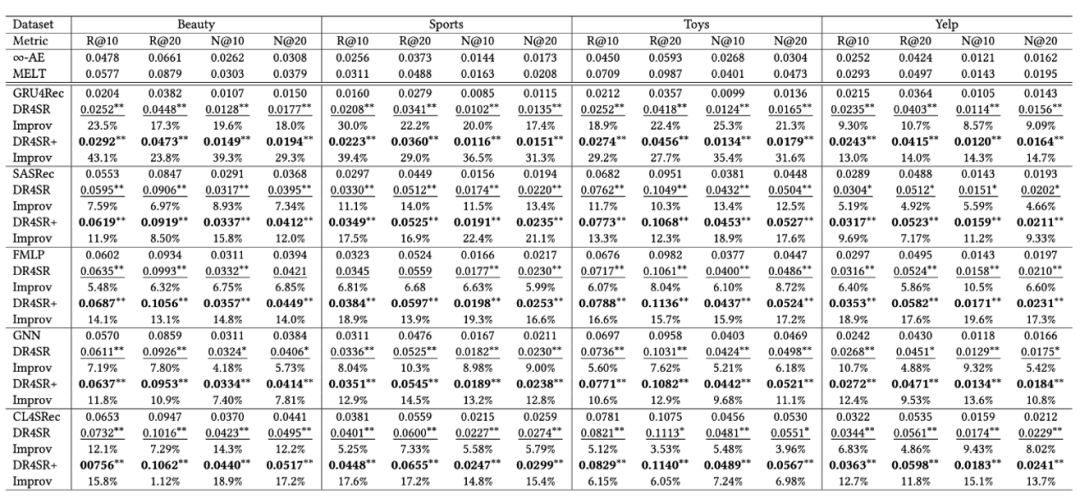
Différents modèles cibles préfèrent différents ensembles de données
Le débruitage n'est qu'un sous-ensemble du problème de reconstruction des données
以上是KDD2024最佳学生论文解读,中科大、华为诺亚:序列推荐新范式DR4SR的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 ControlNet作者又出爆款!一张图生成绘画全过程,两天狂揽1.4k Star
Jul 17, 2024 am 01:56 AM
ControlNet作者又出爆款!一张图生成绘画全过程,两天狂揽1.4k Star
Jul 17, 2024 am 01:56 AM
同样是图生视频,PaintsUndo走出了不一样的路线。ControlNet作者LvminZhang又开始整活了!这次瞄准绘画领域。新项目PaintsUndo刚上线不久,就收获1.4kstar(还在疯狂涨)。项目地址:https://github.com/lllyasviel/Paints-UNDO通过该项目,用户输入一张静态图像,PaintsUndo就能自动帮你生成整个绘画的全过程视频,从线稿到成品都有迹可循。绘制过程,线条变化多端甚是神奇,最终视频结果和原图像非常相似:我们再来看一个完整的绘
 登顶开源AI软件工程师榜首,UIUC无Agent方案轻松解决SWE-bench真实编程问题
Jul 17, 2024 pm 10:02 PM
登顶开源AI软件工程师榜首,UIUC无Agent方案轻松解决SWE-bench真实编程问题
Jul 17, 2024 pm 10:02 PM
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com这篇论文的作者均来自伊利诺伊大学香槟分校(UIUC)张令明老师团队,包括:StevenXia,四年级博士生,研究方向是基于AI大模型的自动代码修复;邓茵琳,四年级博士生,研究方
 从RLHF到DPO再到TDPO,大模型对齐算法已经是「token-level」
Jun 24, 2024 pm 03:04 PM
从RLHF到DPO再到TDPO,大模型对齐算法已经是「token-level」
Jun 24, 2024 pm 03:04 PM
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com在人工智能领域的发展过程中,对大语言模型(LLM)的控制与指导始终是核心挑战之一,旨在确保这些模型既强大又安全地服务于人类社会。早期的努力集中于通过人类反馈的强化学习方法(RL
 arXiv论文可以发「弹幕」了,斯坦福alphaXiv讨论平台上线,LeCun点赞
Aug 01, 2024 pm 05:18 PM
arXiv论文可以发「弹幕」了,斯坦福alphaXiv讨论平台上线,LeCun点赞
Aug 01, 2024 pm 05:18 PM
干杯!当论文讨论细致到词句,是什么体验?最近,斯坦福大学的学生针对arXiv论文创建了一个开放讨论论坛——alphaXiv,可以直接在任何arXiv论文之上发布问题和评论。网站链接:https://alphaxiv.org/其实不需要专门访问这个网站,只需将任何URL中的arXiv更改为alphaXiv就可以直接在alphaXiv论坛上打开相应论文:可以精准定位到论文中的段落、句子:右侧讨论区,用户可以发表问题询问作者论文思路、细节,例如:也可以针对论文内容发表评论,例如:「给出至
 黎曼猜想显着突破!陶哲轩强推MIT、牛津新论文,37岁菲尔兹奖得主参与
Aug 05, 2024 pm 03:32 PM
黎曼猜想显着突破!陶哲轩强推MIT、牛津新论文,37岁菲尔兹奖得主参与
Aug 05, 2024 pm 03:32 PM
最近,被称为千禧年七大难题之一的黎曼猜想迎来了新突破。黎曼猜想是数学中一个非常重要的未解决问题,与素数分布的精确性质有关(素数是那些只能被1和自身整除的数字,它们在数论中扮演着基础性的角色)。在当今的数学文献中,已有超过一千条数学命题以黎曼猜想(或其推广形式)的成立为前提。也就是说,黎曼猜想及其推广形式一旦被证明,这一千多个命题将被确立为定理,对数学领域产生深远的影响;而如果黎曼猜想被证明是错误的,那么这些命题中的一部分也将随之失去其有效性。新的突破来自MIT数学教授LarryGuth和牛津大学
 OpenAI超级对齐团队遗作:两个大模型博弈一番,输出更好懂了
Jul 19, 2024 am 01:29 AM
OpenAI超级对齐团队遗作:两个大模型博弈一番,输出更好懂了
Jul 19, 2024 am 01:29 AM
如果AI模型给的答案一点也看不懂,你敢用吗?随着机器学习系统在更重要的领域得到应用,证明为什么我们可以信任它们的输出,并明确何时不应信任它们,变得越来越重要。获得对复杂系统输出结果信任的一个可行方法是,要求系统对其输出产生一种解释,这种解释对人类或另一个受信任的系统来说是可读的,即可以完全理解以至于任何可能的错误都可以被发现。例如,为了建立对司法系统的信任,我们要求法院提供清晰易读的书面意见,解释并支持其决策。对于大型语言模型来说,我们也可以采用类似的方法。不过,在采用这种方法时,确保语言模型生
 LLM用于时序预测真的不行,连推理能力都没用到
Jul 15, 2024 pm 03:59 PM
LLM用于时序预测真的不行,连推理能力都没用到
Jul 15, 2024 pm 03:59 PM
语言模型真的能用于时序预测吗?根据贝特里奇头条定律(任何以问号结尾的新闻标题,都能够用「不」来回答),答案应该是否定的。事实似乎也果然如此:强大如斯的LLM并不能很好地处理时序数据。时序,即时间序列,顾名思义,是指一组按照时间发生先后顺序进行排列的数据点序列。在很多领域,时序分析都很关键,包括疾病传播预测、零售分析、医疗和金融。在时序分析领域,近期不少研究者都在研究如何使用大型语言模型(LLM)来分类、预测和检测时间序列中的异常。这些论文假设擅长处理文本中顺序依赖关系的语言模型也能泛化用于时间序
 首个基于Mamba的MLLM来了!模型权重、训练代码等已全部开源
Jul 17, 2024 am 02:46 AM
首个基于Mamba的MLLM来了!模型权重、训练代码等已全部开源
Jul 17, 2024 am 02:46 AM
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。引言近年来,多模态大型语言模型(MLLM)在各个领域的应用取得了显着的成功。然而,作为许多下游任务的基础模型,当前的MLLM由众所周知的Transformer网络构成,这种网
