AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
单元测试是软件开发流程中的一个关键环节,主要用于验证软件中的最小可测试单元,函数或模块是否按预期工作。单元测试的目标是确保每个独立的代码片段都能正确执行其功能,对于提高软件质量和开发效率具有重要意义。然而,大模型自身无力为复杂待测函数(环复杂度大于 10)生成高覆盖率的测试样例集。为了解决该痛点,北京大学李戈教授团队提出一种全新的提升测试用例覆盖率的方法,该方法借助程序分片思想(Method Slicing),将复杂待测函数依据语义拆解为若干简单片段,进而让大模型为各个简单片段分别生成测试样例。生成单个测试样例时,大模型只需分析原待测函数的一个片段,分析难度减小,生成覆盖该片段的单元测试难度随之减小。由此推广,提升整体测试样例集代码覆盖率。相关论文《HITS: High-coverage LLM-based Unit Test Generation via Method Slicing》近期被 ASE 2024(at the 39th IEEE/ACM International Conference on Automated Software Engineering)顶会接受。
论文地址:https://www.arxiv.org/pdf/2408.11324程序分片指将一个程序依据语义划分为若干解决问题的阶段。程序是对一个问题解决方案的形式化表述。一个问题解决方案通常包含多个步骤,每个步骤对应着程序中的一片(slice)代码。如下图所示,一个色块对应着一片代码,也对应着一个问题解决的步骤。
HITS nécessite le grand modèle pour concevoir le code de test unitaire pour chaque morceau de code qui peut le couvrir efficacement. En prenant la figure ci-dessus comme exemple, lorsque nous obtenons les tranches comme indiqué sur la figure, HITS nécessite que le grand modèle génère des échantillons de test pour la tranche 1 (verte), la tranche 2 (bleue) et la tranche 3 (rouge) respectivement. Les échantillons de test générés pour la tranche 1 doivent couvrir la tranche 1 autant que possible, indépendamment des tranches 2 et 3. Il en va de même pour les autres éléments de code. HITS fonctionne pour deux raisons. Premièrement, les grands modèles devraient envisager de réduire la quantité de code couverte. En prenant la figure ci-dessus comme exemple, lors de la génération d'échantillons de test pour la tranche 3, seules les branches conditionnelles de la tranche 3 doivent être prises en compte. Pour couvrir certaines branches conditionnelles dans la Slice 3, il suffit de trouver un chemin d'exécution dans la Slice 1 et la Slice 2, sans considérer l'impact de ce chemin d'exécution sur la couverture de la Slice 1 et de la Slice 2. Deuxièmement, les morceaux de code segmentés en fonction de la sémantique (étapes de résolution de problèmes) aident les grands modèles à saisir les états intermédiaires de l'exécution du code. La génération de cas de test pour les blocs de code ultérieurs nécessite la prise en compte des modifications de l'état du programme provoquées par le code précédent. Étant donné que les blocs de code sont segmentés en fonction des étapes réelles de résolution de problèmes, les opérations des blocs de code précédents peuvent être décrites en langage naturel (comme le montre l'annotation de la figure ci-dessus). Étant donné que la plupart des grands modèles de langage actuels sont le produit d'un apprentissage mixte entre le langage naturel et le langage de programmation, une bonne synthèse en langage naturel peut aider les grands modèles à saisir plus précisément les changements d'état du programme provoqués par le code. HITS utilise de grands modèles pour le partitionnement de programmes. Les étapes de résolution de problèmes sont généralement exprimées en langage naturel avec la couleur subjective du programmeur, de sorte que de grands modèles dotés de capacités supérieures de traitement du langage naturel peuvent être directement utilisés. Plus précisément, HITS utilise l'apprentissage en contexte pour appeler de grands modèles. L'équipe a utilisé son expérience pratique passée dans des scénarios réels pour écrire manuellement plusieurs exemples de partitionnement de programme. Après plusieurs ajustements, l'effet du grand modèle sur le partitionnement de programme a répondu aux attentes de l'équipe de recherche. Générer des exemples de tests pour les extraits de codeÉtant donné l'extrait de code à couvrir, pour générer les échantillons de test correspondants, vous devez suivre les trois étapes suivantes : 1. Analyser l'entrée du fragment 2. Construire une invite pour demander au grand modèle de générer un échantillon de test initial 3. Utiliser le post-traitement des règles ; ajustement d'auto-débogage du grand modèle Testez l'échantillon afin qu'il fonctionne correctement. Analyser l'entrée du fragment, ce qui signifie extraire toutes les entrées externes acceptées par le fragment à couvrir pour une utilisation rapide ultérieure. L'entrée externe fait référence aux variables locales définies par les fragments précédents auxquels ce fragment est appliqué, aux paramètres formels de la méthode testée, aux méthodes appelées dans le fragment et aux variables externes. La valeur de l'entrée externe détermine directement l'exécution du fragment à couvrir, donc extraire ces informations pour inciter le grand modèle aide à concevoir des cas de test de manière ciblée. L'équipe de recherche a découvert lors d'expériences que les grands modèles ont une bonne capacité à extraire des entrées externes, c'est pourquoi de grands modèles sont utilisés pour accomplir cette tâche dans HITS. Ensuite, HITS crée une invite de chaîne de pensée pour guider le grand modèle afin de générer des échantillons de test. Les étapes de raisonnement sont les suivantes. La première étape consiste à fournir l'entrée externe et à analyser les permutations et les combinaisons des différentes branches conditionnelles dans le morceau de code à couvrir. Quelles propriétés les entrées externes doivent-elles satisfaire ? Par exemple : la combinaison 1, la chaîne a doit contenir le ? caractère 'x', la variable entière i doit être non négative ; dans la combinaison 2, la chaîne a doit être non vide et la variable entière i doit être un nombre premier. Dans la deuxième étape, pour chaque combinaison de l'étape précédente, analysez la nature de l'environnement dans lequel le code correspondant testé est exécuté, y compris, mais sans s'y limiter, les caractéristiques des paramètres réels et les paramètres des variables globales. La troisième étape consiste à générer un échantillon test pour chaque combinaison. L’équipe de recherche a construit des exemples à la main pour chaque étape afin que le grand modèle puisse comprendre et exécuter correctement les instructions. Enfin, HITS permet aux échantillons de test générés par de grands modèles de s'exécuter correctement grâce au post-traitement et à l'auto-débogage. Les échantillons de test générés par de grands modèles sont souvent difficiles à utiliser directement, et il y aura diverses erreurs de compilation et d'exécution causées par des échantillons de test mal écrits. L'équipe de recherche a conçu plusieurs règles et cas courants de réparation d'erreurs sur la base de leurs propres observations et résumés d'articles existants. Essayez d’abord de réparer selon les règles. Si la règle ne peut pas être réparée, utilisez la fonction d'auto-débogage du grand modèle pour la réparer. Des cas de réparation d'erreurs courantes sont fournis dans l'invite de référence du grand modèle.
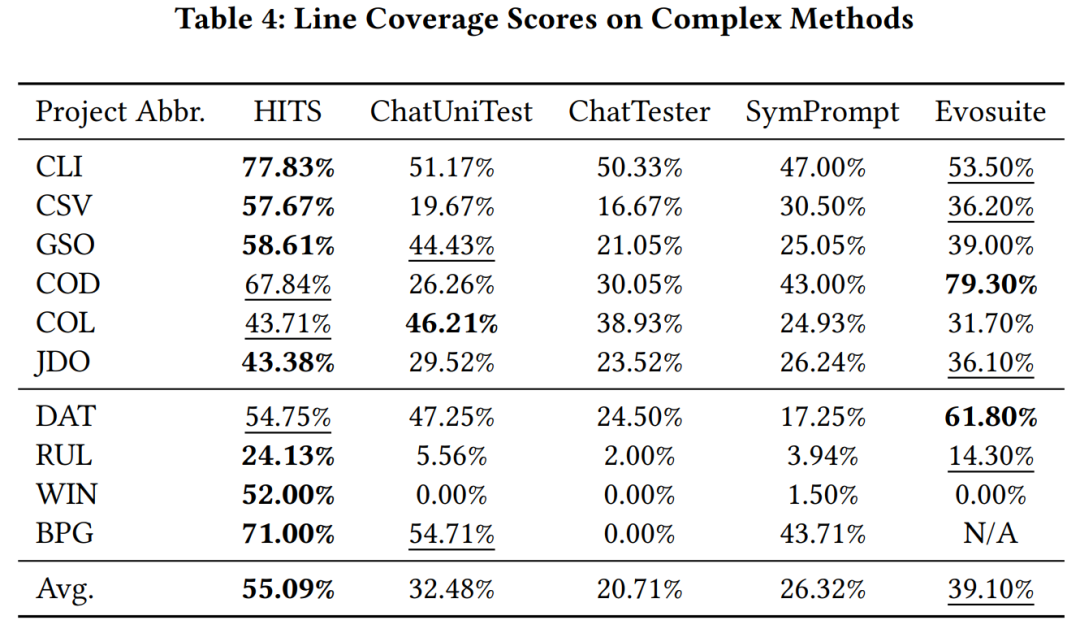
研究团队使用 gpt-3.5-turbo 作为 HITS 调用的大模型,分别在大模型学习过和未学习过的 Java 项目中的复杂函数(环复杂度大于 10)上对比 HITS,其他基于大模型的单元测试方法和 evosuite 的代码覆盖率。实验结果显示 HITS 相较于被比较的诸方法有较明显的性能提升。
研究团队通过样例分析展示分片方法如何提升代码覆盖率。如图所示。该案例中,基线方法生成的测试样例未能完全覆盖 Slice 2 中的红色代码片段。然而,HITS 由于聚焦于 Slice 2,对其所引用的外部变量进行了分析,捕捉到 “如果要覆盖红色代码片段,变量’arguments’ 需要非空 “的性质,根据该性质构建了测试样例,成功实现了对红色区域代码的覆盖。提升单元测试覆盖率,增强系统的可靠性和稳定性,进而提高软件质量。HITS使用程序分片实验证明,该技术不仅能大幅提升整体测试样例集代码覆盖率,且实施方法简洁直接,未来有望在真实场景实践中,帮助团队更早发现并修正开发中的错误,提升软件交付质量。以上是北大李戈团队提出大模型单测生成新方法,显着提升代码测试覆盖率的详细内容。更多信息请关注PHP中文网其他相关文章!