

编辑| ScienceAI
近日,上海交通大学、上海AI Lab、中国移动等机构的联合研究团队,在arXiv 预印平台发布文章《Towards Evaluating and Building Versatile Large Language Models for Medicine》,从数据、测评、模型多个角度全面分析讨论了临床医学大语言模型应用。
文中所涉及的所有数据和代码、模型均已开源。

概览
近年来,大型语言模型(LLM)取得了显着的进展,并在医疗领域取得了一定成果。这些模型在医学多项选择问答(MCQA)基准测试中展现出高效的能力,并且 UMLS 等专业考试中达到或超过专家水平。
然而,LLM 距离实际临床场景中的应用仍然有相当长的距离。其主要问题,集中在模型在处理基本医学知识方面的不足,如在解读 ICD 编码、预测临床程序以及解析电子健康记录(EHR)数据方面的误差。
这些问题指向了一个关键:当前的评估基准主要关注于医学考试选择题,而不能充分反映 LLM 在真实临床情景中的应用。
本研究提出了一项新的评估基准MedS-Bench,该基准不仅包括多项选择题,还涵盖了临床报告摘要、治疗建议、诊断和命名实体识别等11 项高级临床任务。
研究团队通过此基准对多个主流的医疗模型进行了评估,发现即便是使用了few-shot prompting,最先进模型,例如,GPT-4,Claude 等,在处理这些复杂的临床任务时也面临困难。
为解决这一问题,受到Super-NaturalInstructions 的启发,研究团队构建了首个全面的医学指令微调数据集MedS-Ins,该数据集整合了来自考试、临床文本、学术论文、医学知识库及日常对话的58 个生物医学文本数据集,包含超过1350 万个样本,涵盖了122 个临床任务。
在此基础上,研究团队对开源医学语言模型进行指令调整,探索了 in-context learning 环境下的模型效果。
该工作中开发的医学大语言模型——MMedIns-Llama 3,在多种临床任务中的表现超过了现有的领先闭源模型,如 GPT-4 和 Claude-3.5。 MedS-Ins 的构建极大的促进了医学大语言模型在实际临床场景的中的能力,使其应用范围远超在线聊天或多项选择问答的限制。
相信这一进展不仅推动了医学语言模型的发展,也为未来临床实践中的人工智能应用提供了新的可能性。
测试基准数据集(MedS-Bench)
为了评估各种LLM 在临床应用中的能力,研究团队开发了MedS -Bench,这是一个超越传统选择题的综合性医学基准。如下图所示,MedS-Bench 源自 39 个现有数据集,覆盖 11 个类别,总共包含 52 个任务。
在 MedS-Bench 中,数据被重新格式化为指令微调的结构。此外,每条任务都配有人工标注的任务定义。涉及的11 个类别分别是:选择题解答(MCQA)、文本摘要(Text Summarization)、信息提取(Information Extraction)、解释与推理(Explanation and Rationale)、命名实体识别(NER) 、诊断(Diagnosis)、治疗计划规划(Treatment Planning)、临床结果预测(Clinical Outcome Prediction)、文本分类(Text Classification)、事实验证(Fact Verification)和自然语言推理(NLI)。
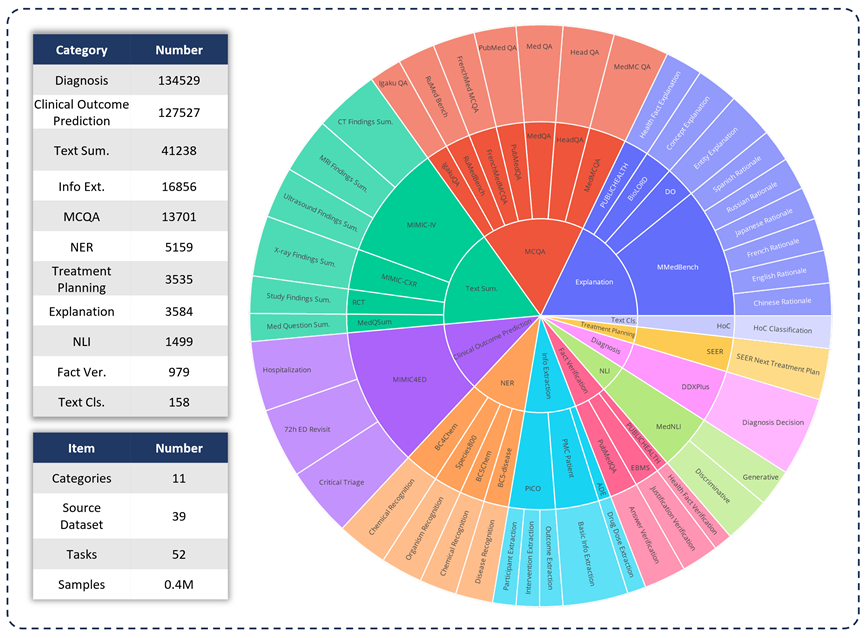
除了定义这些任务类别,研究团队还对 MedS-Bench 文本长度进行了详细的统计,并区分了 LLM 处理不同任务所需的能力,如下表所示。LLM 处理任务所需的能力被分为两类:(i)根据模型内部知识进行推理;(ii) 从提供的上下文中检索事实。
广义上讲,前者涉及的任务需要从大规模预训练中获取编码在模型权重中的知识,而后者涉及的任务则需要从所提供的上下文中提取信息,如总结或信息提取。如表 1 所示,总共有八类任务要求模型从模型中调用知识,而其余三类任务则要求从给定上下文中检索事实。
表 1:所用测试任务的详细统计信息。

指令微调数据集(MedS-Ins)
此外,研究团队还开源了指令微调数据集 MedS-Ins。该数据集覆盖 5 个不同的文本源和 19 个任务类别,共计 122 个不同的临床任务。下图总结了 MedS-Ins的构造流程以及统计信息。
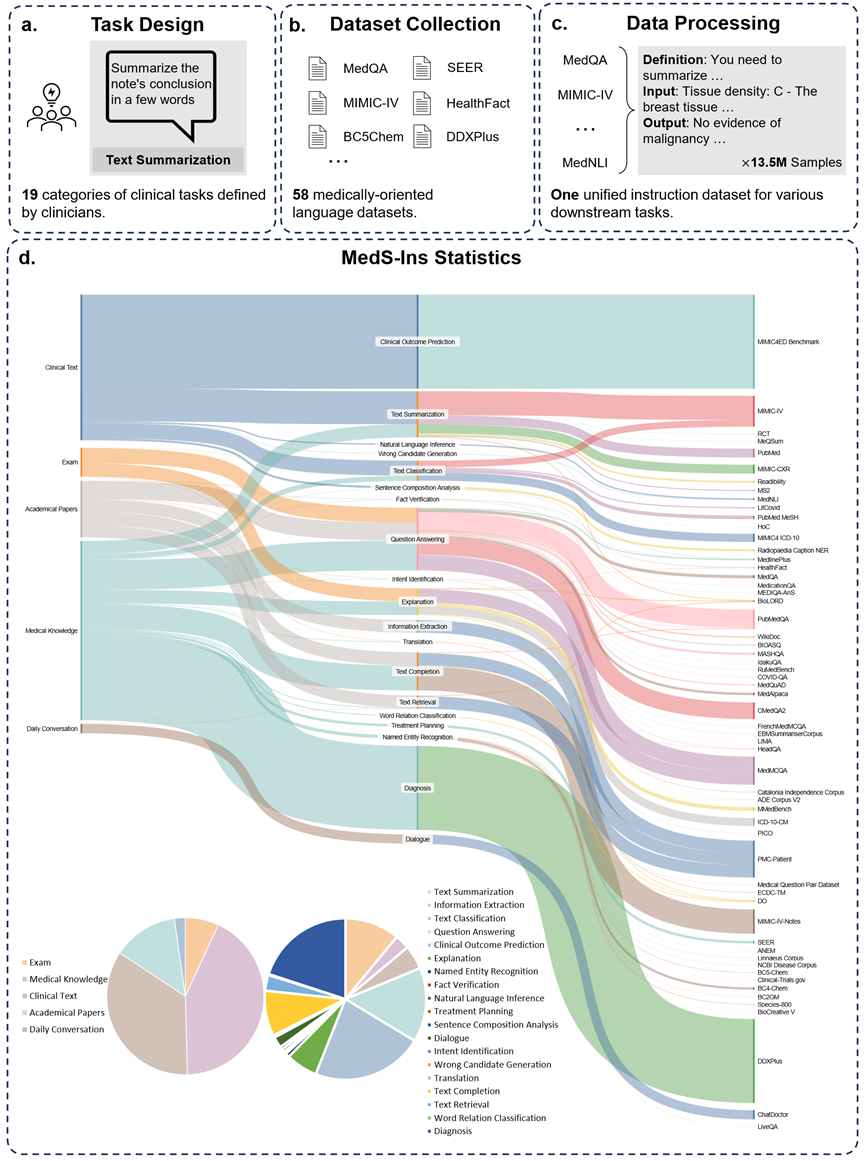
文本源
本文提出的指令微调数据集由五个不同来源的样本组成:考试、临床文本、学术论文、医学知识库和日常对话。
考试:该类别包含来自不同国家医学考试试题的数据。它涵盖了从基本医学常识到复杂临床手续广泛的医学知识。考试题目是了解和评估医学教育水平的重要手段,然而值得注意的是,考试的高度标准化往往导致其案例与真实世界的临床任务相比过于简化。数据集中 7% 的数据来自考试。
临床文本:该类别文本在常规临床实践中产生,包括医院和临床中心的诊断、治疗和预防过程。这类文本包括电子健康记录 (EHR)、放射报告、化验结果、随访指导和用药建议等。这些文本是疾病诊断和患者管理所不可或缺的,因此准确的分析和理解对于 LLM 的有效临床应用至关重要。数据集中 35% 的数据来自临床文本。
学术论文:该类别数据来源于医学研究论文,涵盖了医学研究领域的最新发现和进展。由于学术论文便于获取和结构化组织,从学术论文中提取数据相对简单。这些数据有助于模型掌握最前沿的医学研究信息,引导模型更好地理解当代医学的发展。数据集中有 13% 的数据来自学术论文。
医学知识库:该类别数据由组织良好的综合医学知识组成,包括医学百科全书、知识图谱和医学术语词汇表。这些数据构成了医学知识库的核心,为医学教育和 LLM 在临床实践中的应用提供了支持。数据集中 43% 的数据来自医学知识。
日常对话:该类别数据指的是医生与患者之间产生的日常咨询、主要来源于在线平台和其他互动场景。这些数据反映了医务人员与患者之间的真实互动、在了解患者需求、提升整体医疗服务体验方面发挥着至关重要的作用。数据集中有 2% 的数据来自日常对话。
任务种类
除了对文本涉及领域进行分类外,研究团队对 MedS-Ins 中样本的任务类别进行进一步细分:确定了 19 个任务类别,每个类别都代表了医学大语言模型应具备的关键能力。通过构建该指令微调数据集并相应地微调模型,使大语言模型具备处理医疗应用所需的多种能力,具体如图 2 所示。
MedS-Ins 中的 19 个任务类别包括但不限于 MedS-Bench 基准中的 11 个类别。额外的任务类别涵盖了医学领域所必需的一系列语言和分析任务,包括意图识别、翻译、单词关系分类、文本检索、句子成分分析、错误候选词生成、对话和文本补齐,而 MCQA 则扩展为一般的问答。任务类别的多样性——从普通问答和对话到各种下游临床任务,保证了对医疗应用的全面理解。
量化对比
研究团队广泛地测试了现存六大主流模型(MEDITRON, Mistral, InternLM 2, Llama 3, GPT-4 and Claude-3.5)在每种任务类型上的表现,首先讨论各种现有 LLM 的性能,然后与提出的最终模型 MMedIns-Llama 3 进行比较。在本文中,所有结果都是使用 3-shot Prompt 得出的。除了在 MCQA 任务中使用了 zero-shot Prompt,以便与之前的研究保持一致。由于 GPT-4 和 Claude 3.5 等闭源模型会产生费用,受限于成本,实验中仅对每个任务抽样 50-100 个测试用例,全面的测试量化结果如表 2-8 所示。
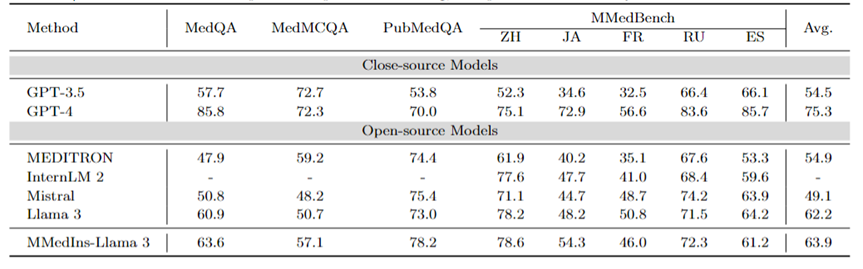
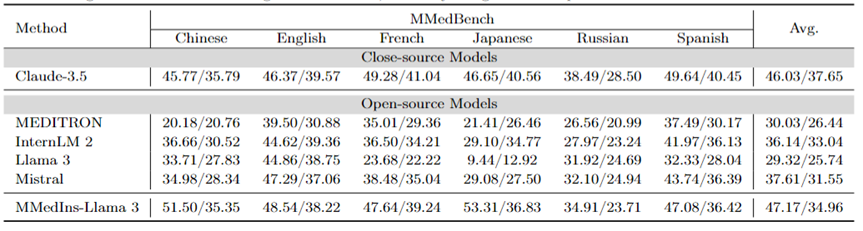
多语种多选题问答:表 2 以「Accuracy」展示了在广泛使用的 MCQA 基准上的评估结果。在这些多选题问答数据集上,现有的大语言模型都表现出了非常高的准确率,例如,在 MedQA 上,GPT-4 可以达到 85.8 分,几乎可以与人类专家相媲美,而 Llama 3 也能以 60.9 分通过考试。同样,在英语以外的语言方面,LLM 在 MMedBench 上的多选准确率也表现出优异的成绩。
结果表明,由于多选题在现有研究中已被广泛考虑,不同的 LLM 可能已针对此类任务进行了专门优化,从而获得了较高的性能。因此,有必要建立一个更全面的基准、 以进一步推动 LLM 向临床应用发展。
表2:选择题上的量化结果,各项指标以选择准确率ACC进行衡量。
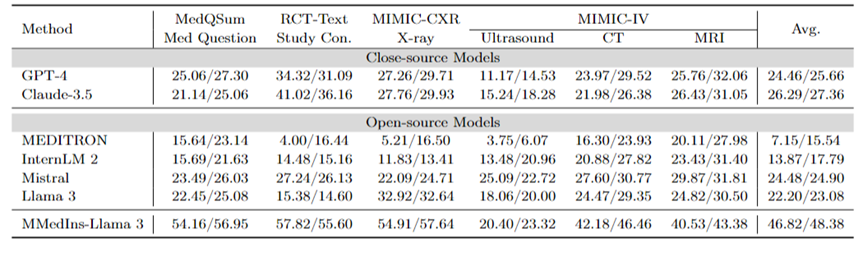
文本总结:表 3 以 「BLEU/ROUGE 」分数的形式报告了不同语言模型在文本总结任务上的性能。测试覆盖了多种报告类型,包括 X 光、CT、MRI、超声波和其他医疗问题。实验结果表明,GPT-4 和 Claude-3.5 等闭源大语言模型的表现优于所有开源大语言模型。
在开源模型中,Mistral 的结果最好,BLEU/ROUGE 分别为 24.48/24.90,Llama 3 紧随其后,为 22.20/23.08。
本文提出的 MMedIns-Llama 3 是在特定医疗教学数据集(MedS-Ins)上训练出来的,其表现明显优于其他模型,包括先进的闭源模型 GPT-4 和 Claude-3.5,平均得分达到 46.82/48.38。
表 3:文本总结任务上的量化结果。
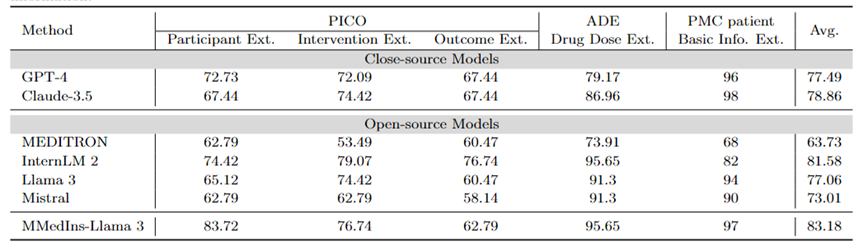
信息抽取:表 4 以「Accuracy」展示了不同模型信息提取的性能。InternLM 2 在这项任务中表现优异,平均得分为 81.58,GPT-4 和 Claude-3.5 等闭源模型的平均得分分别为 77.49 分和 78.86 分,优于所有其他开源模型。
对单个任务结果的分析表明,与专业的医疗数据相比,大多数大语言模型在提取病人基本信息等不太复杂的医疗信息方面表现更好。例如,在从 PMC 患者中提取基本信息方面,大多数大语言模型的得分都在 90 分以上,其中 Claude-3.5 的得分最高,达到 98.02 分。相比之下,PICO 中临床结果提取任务的表现相对较差。本文提出的模型 MMedIns-Llama 3 整体表现最佳,平均得分 83.18,超过 InternLM 2 模型 1.6 分。
表 4:信息提取任务上的量化结果,各项指标以准确度(ACC)进行衡量。「Ext.」表示Extraction,「Info.」表示 Information。
医学概念解释:表 5 以 「BLEU/ROUGE 」分数的形式展示了不同模型医学概念解释能力,GPT-4,Llama 3和Mistral 在这项任务中表现良好。
相反,Claude-3.5、InternLM 2 和 MEDITRON 的得分相对较低。MEDITRON 的表现相对较差可能是由于其训练语料更侧重于学术论文和指南,因此在对于医学概念解释方面能力有所欠缺。
最终模型 MMedIns-Llama 3 在所有概念解释任务中的表现都明显优于其他模型。
表 5:医学概念解释上的量化结果,各项指标以 BLEU-1/ROUGE-1 进行衡量;「Exp.」表示 Explanation。
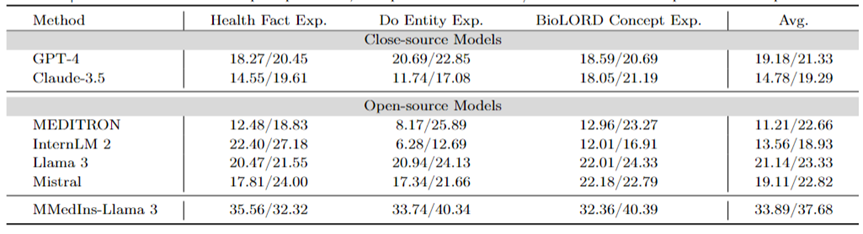
归因分析(Rationale):表 6 以 「BLEU/ROUGE 」分数的形式评估了各个模型在归因分析任务上的性能,使用 MMedBench 数据集对六种语言的各种模型的推理能力进行了比较。
在测试的模型中,闭源模型 Claude-3.5 表现出最强的性能,平均得分为 46.03/37.65。这种优异的表现可能是因为该任务与生成 COT 相似,而后者在许多通用 LLM 中均得到了特别增强。
在开源模型中,Mistral 和 InternLM 2 表现出了相当的性能,平均得分分别为 37.61/31.55 和 30.03/26.44。值得注意的是,GPT-4 被排除在本次评估之外,因为 MMedBench 数据集的归因分析部分主要使用 GPT-4 来生成构建,这可能会引入测试偏差,从而导致不公平的比较。
与概念解释任务上的表现一致,最终模型 MMedIns-Llama 3 也展现了最佳的整体性能,所有语言上的平均得分为 47.17/34.96。这种优异的表现可能是因为选用的基础语言模型(MMed-Llama 3)最初是为多语言开发的。因此,即使指令调整没有明确针对多语言数据,最终模型在多种语言中的表现仍然优于其他模型。
表 6:归因分析(Rationale)上的量化结果,各项指标以 BLEU-1/ROUGE-1 进行衡量。此处没有 GPT-4 是因为原始数据基于 GPT-4 生成结果构造,存在公平性偏倚,故未比较 GPT-4。
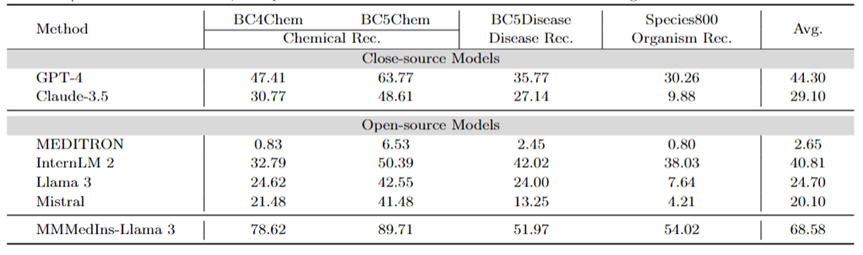
医学实体抽取(NER):表 7 以「F1」分数的形式测试了现有的 6 个模型在 NER 任务上的表现。GPT-4 是唯一一个在命名实体识别 (NER) 各项任务中均表现优异的模型,平均 F1 分数为 44.30 。
它在 BC5Chem 化学实体识别任务中表现尤为出色,得分为 63.77。InternLM 2 则紧随其后,平均 F1 分数为 40.81,在 BC5Chem 和 BC5Disease 任务中均表现出色。Llama 3 和 Mistral 的平均 F1 分数则分别为 24.70 和 20.10,表现中等。MEDITRON 未针对 NER 任务进行优化,在此领域的效果差强人意。MMedIns-Llama 3 的表现则明显优于所有其他模型,平均 F1 得分为68.58。
表 7:NER 任务上的量化结果,各项指标以F1-score进行衡量;「Rec.」代表「recognition」
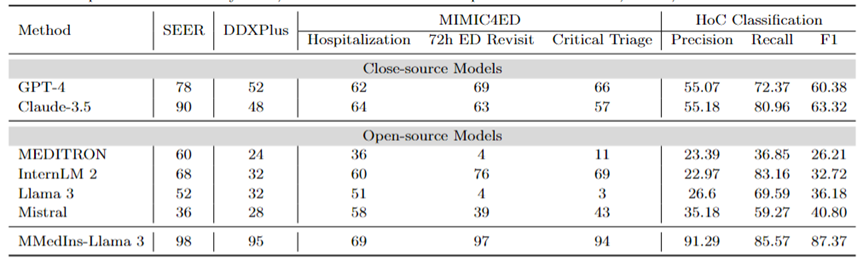
诊断、治疗推荐、和临床结果预测:表 8 使用 DDXPlus 数据集作为诊断基准、SEER 数据集作为治疗推荐基准和 MIMIC4ED 数据作为临床结果预测任务基准来评估诊断、治疗推荐和临床结果预测三大任务的模型表现,结果以准确度来衡量,如表 8 所示。
在此,使用可以使用准确度指标来评估生成预测是因为这些数据集每一个都将原始问题简化为一个闭集上的选择问题。具体而言,DDXPlus 使用预定义的疾病列表,模型必须根据提供的患者背景从中选择一个疾病。在 SEER 中,治疗建议则被分为了八个高级类别,而在 MIMIC4ED 中,最终的临床结果决策是始终是二值的(True or False)。
总体而言,开源 LLM 在这些任务中的表现不如闭源 LLM,在某些情况下,它们无法提供有意义的预测。例如,Llama 3 在预测 Critical Triage 方面表现不佳。对于 DDXPlus 诊断任务而言,InternLM 2 和 Llama 3 的表现略好一些,准确度为 32。然而,GPT-4 和 Claude-3.5 等闭源模型表现出明显更好的性能。例如,Claude-3.5在SEER上准确度可以达到为90,而GPT-4则在 DDXPlus 的诊断方面的准确度上更高,得分为 52,突显出了开源和闭源 LLM 之间的巨大差距。
尽管取得了这些成果,但这些分数仍然不足以可靠地用于临床。相比之下, MMedIns-Llama 3 在临床决策支持任务中则表现出了更加卓越的准确性,例如 SEER 上为 98,DDXPlus 上为 95,临床结果预测任务上平均准确度为86.67(Hospitalization, 72h ED Revisit, and Critical Triage 得分的平均值)。
文本分类:表 8 还展示了对 HoC 多标签分类任务的评估,并报告了 Macro-precision、Macro-recall 和 Macro-F1 Scores。对于这类任务,所有候选标签都以列表的形式输入到语言模型中,并要求模型选择其对应的答案,并允许进行多项选择。然后根据模型最终的选择输出计算准确度指标。
GPT-4 和 Claude-3.5 在此任务上表现良好,GPT-4 的 Macro-F1 分数为 60.38,Claude-3.5 则更为优异,取得了63.32。这两个模型都表现出很强的召回能力,尤其是 Claude-3.5,其 Macro-Recall 为 80.96。Mistral 表现中等,Macro-F1 分数为 40.8,在精度和召回率之间保持平衡。
相比之下,Llama 3 和 InternLM 2 的整体表现较差,Macro-F1 得分分别为36.18 和 32.72。这些模型(尤其是 InternLM 2)表现出较高的召回率,但准确率却很差,导致 Macro-F1 得分较低。
MEDITRON 在此任务中排名最低,Macro-F1 得分为 26.21。MMedIns-Llama 3 明显优于所有其他模型,在所有指标中均获得最高分,Macro-precision 为 91.29,Macro-recall 为 85.57,Macro-F1 得分为 87.37。这些结果凸显了 MMedIns-Llama 3 准确分类文本的能力,使其成为处理这类复杂任务最有效的模型。
表 8:治疗规划(SEER)、诊断(DDXPlus)、临床结果预测(MIMIC4ED)和文本分类(HoC Classification)四类任务上的结果。前 3 项任务的结果以准确率(Accuracy)为依据,文本分类结果以精确度(Precision)、召回率(Recall)和 F1 分数为依据。
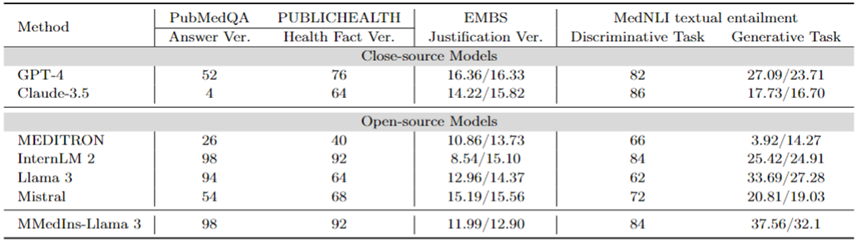
事实纠正:表 9 展示了在事实验证任务上模型评估结果。对于 PubMedQA 答案验证和 HealthFact 验证,LLM 需要从提供的候选列表中选择一个答案,因此以准确度作为评估指标。
相对的,由于 EBMS 理由验证,任务涉及生成自由格式的文本,使用 BLEU-1 和 ROUGE-1 分数来评估性能。InternLM 2 在 PubMedQA 答案验证和 HealthFact 验证中获得了最高的准确度,得分分别为 98 和 92。
在 EBMS 基准测试中,GPT-4 表现出最强的性能,BLEU-1/ROUGE-1 得分分别为16.36/16.33。Claude-3.5 紧随其后,得分为14.22/15.82,但它在PubMedQA答案验证中表现不佳。
Llama 3 在 PubMedQA 和 HealthFact Verification 上的准确率分别为 94 和 64,BLEU-1/ROUGE-1 得分为12.96/14.37。MMedIns-Llama 3 继续超越现有模型,与 InternLM 2 一样在PubMedQA答案验证任务上取得了最高的准确度得分,而在 EMBS 中,MMedIns-Llama 3 在 BLEU-1和 ROUGE-1 中以 11.99/12.90 的成绩略微落后于 GPT-4。
医学文本蕴含(NLI):表 9 还展示了以 MedNLI 为主的,在医学文本蕴含(NLI)上的评估结果。测试方式有两种,一种是判别任务(从候选列表中选择正确答案),以准确度衡量,另一种是生成任务(生成自由格式文本答案),以BLEU/ROUGE 指标来衡量。
InternLM 2 在开源 LLM 中得分最高,得分为 84。对于闭源 LLM,GPT-4 和 Claude-3.5 都显示出相对较高的分数,准确度分别为 82 和 86。在生成任务中,Llama 3 与真实值的一致性最高,BLEU 和 ROUGE 得分为 33.69/27.28。Mistral 和 Llama 3 则表现出中等水平。GPT-4 紧随其后,得分为 27.09/23.71,而 Claude-3.5 在生成任务中表现并不理想。
MMedIns-Llama 3 在判别任务中准确率最高,得分为 84,但略落后于 Claude-3.5。MMedIns-Llama 3 在生成任务中也表现出色,BLEU/ROUGE 得分为 37.56/32.17,明显优于其他模型。
表 9:事实验证和文本蕴含两类任务上的量化结果,结果以准确度(ACC)和BLEU/ROUGE来衡量;表中「Ver.」是「verification」的简写。
总的而言,研究团队在各种任务维度上,评测了六大主流模型,研究结果表明目前的主流 LLMs 处理临床任务时仍旧相当脆弱,会在多样化的复杂临床场景下产生严重的性能不足。
同时,实验结果也展示出,通过在指令数据集中加入更多临床任务文本,强化 LLM 与临床实际适用的匹配程度,可以大大的加强 LLM 性能。
数据收集方法与训练流程
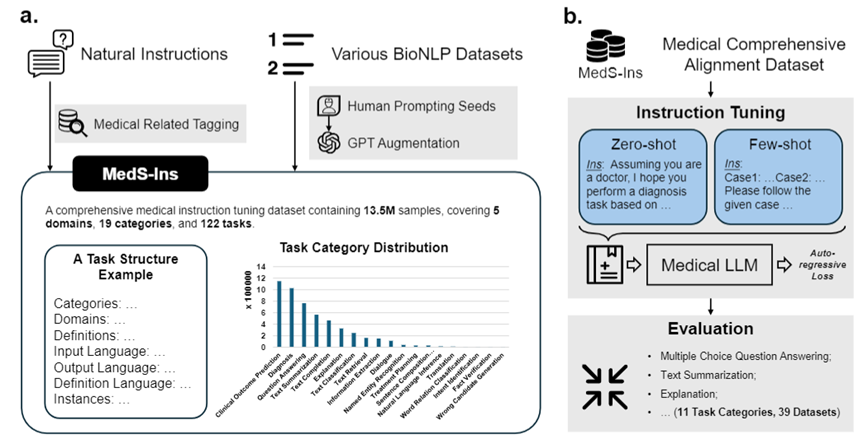
本节将详细介绍训练过程,如图 3b 所示。具体方法与之前的工作 MMedLM 和 PMC-LLaMA 相同,均通过在医学相关的语料库上进行进一步的自回归训练可以为模型注入相应的医学知识,从而使它们在不同的下游任务中表现得更好。
具体而言,研究团队从多语言 LLM 基座模型(MMed-Llama 3)开始,利用来自 MedS-Ins 的指令微调数据对其进行进一步训练。
指令微调的数据主要涉及两个方面:
医学过滤后的自然指令数据:首先从自然领域最大规模的指令数据集Super-NaturalInstructions中筛选出与医疗相关的任务。由于Super-NaturalInstructions更侧重于通用领域的不同自然语言处理任务,因此对医疗领域的分类粒度相对较粗。
首先提取了 「医疗保健 」和 「医学 」类别中的所有指令,然后在任务类别不变的情况下,手动为它们添加了更详细的领域标签。此外,许多通用领域的有组织指令微调数据集也涵盖了一些医疗相关数据,例如LIMA和ShareGPT。
为了过滤出这些数据中的医疗部分,研究团队使用了InsTag对每条指令的领域进行粗粒度分类。具体来说,InsTag是一种 LLM,专门用于标记不同的指令样本。给定一个指令查询,它将分析该指令属于哪个领域和任务,在此基础上筛选出标记为医疗保健、医疗或生物医学的样本。
最后,通过过滤一般领域的指令数据集,收集到 37 个任务,共计 75373 个样本。
提示构造现有的 BioNLP 数据集:在现有数据集中有许多关于临床场景中文本分析的优秀数据集。然而,由于大多数数据集的收集目的不同,它们不能直接用于训练大型语言模型。然而,可以通过将这些现有的医学 NLP 任务转换成可用于训练生成模型的格式,从而将它们加入到指令调整中。
具体来说,研究团队以 MIMIC-IV-Note 为例。MIMIC-IV-Note 提供了高质量的结构化报告,其中既有发现也有也有结论,发现到结论的生成被视为经典的临床文本总结任务。首先手动编写提示来定义任务,例如:「鉴于超声成像诊断的详细结果,用几个词概括发现。」 考虑到指令调整的多样性需求,研究团队要求5个人独立地用3种不同的提示描述某项任务。
这样,每个任务就有了 15 条自由文本提示,保证了语义相似,但措辞和格式尽可能多样化。然后,受 Self-Instruct 的启发,将这些人工编写的指令作为种子指令,并要求 GPT-4 根据其进行改写,从而获得更多的多样化指令。
通过上述过程,将额外的 85 个任务提示为统一的自由问答格式,再结合过滤后的数据,得到了总计 1350 万个高质量样本,涵盖 122 个任务,称为 MedS-Ins,并通过指令微调,训练了一个全新的 8B 尺寸的医学 LLM,结果表明该方法显著提高了临床任务的性能。
在指令微调中,研究团队重点考虑了两种指令形式:
零样本提示:在这里,任务的指令包含一些语义任务描述作为提示,因此要求模型根据其内部模型知识直接回答问题。在收集到的 MedS-Ins 中,每个任务的 「定义 」内容都可以自然地用作零点指令输入。由于涵盖了各种不同的医疗任务定义,该模型有望学习对各种任务描述的语义理解。
少样本提示:在这里,指令包含了少量的示例,这些示例允许模型从上下文中学习到任务的大致需求。只需从同一任务的训练集中随机抽取其他案例,并使用以下简单模板对其进行组织,即可获得此类指令:
Case1: Input: {CASE1_INPUT}, Output: {CASE1_OUTPUT} ... CaseN: Input: {CASEN_INPUT}, Output: {CASEN_OUTPUT} {INSTRUCTION} Please learn from the few-shot cases to see what content you have to output. Input: {INPUT}
讨论
总体而言,本文做出了几项重要贡献:
综合评估基准--MedS-Bench
医学 LLM 的开发在很大程度上依赖于多选题回答(MCQA)的基准测试。然而,这种狭隘的评估框架回忽略 LLM 在各种复杂临床场景下中真实的能力表现。
因此,在这项工作中,研究团队引入了 MedS-Bench,这是一个综合基准,旨在评估闭源和开源 LLM 在各种临床任务中的性能,包括那些需要从模型预训练语料中回忆事实或从给定上下文中进行推理的任务。
研究结果表明,虽然现有的 LLM 在 MCQA 基准测试中表现优异,但它们却很难与临床实践保持一致,尤其是在治疗推荐和解释等任务中。这一发现凸显了进一步开发适配于更广泛临床和医学场景的医学大语言模型的必要性。
综合指令调整数据集--MedS-Ins
研究团队从现有的 BioNLP 数据集中广泛获取数据,并将这些样本转换为统一格式,同时采用半自动化的提示策略,构建开发了 MedS-Ins--一种新型的医疗指令调整数据集。以往的指令微调数据集的工作主要集中在从日常对话、考试或学术论文中构建问答对,往往忽略了从实际临床实践中生成的文本。
相比之下,MedS-Ins 整合了更广泛的医学文本资源,包括 5 个主要文本领域和 19 个任务类别。这种对数据组成的系统性分析有利于用户理解 LLM 的临床应用边界。
医学大语言模型--MMedIns-Llama 3
在模型方面,研究团队证明了通过在MedS-Ins上进行指令微调训练,可以显著提高开源医学LLM与临床需求的一致性。
需要强调的是,最终模型MMedIns-Llama 3更多是一个「概念验证」模型,它采用了8B的中等参数规模,最终的模型对各种临床任务展现出了深刻的理解,并能通过零次或少量的指令提示灵活适应多种医疗场景,而无需进一步的特定任务训练。
结果表明,MMedIns-Llama 3在特定临床任务类型上优于现有的LLM、 包括 GPT-4、Claude-3.5等。
现有的局限性
在此,研究团队也要强调了本文的局限性以及未来可能的改进。
首先,MedS-Bench 目前只涵盖了 11 项临床任务、 这并不能完全涵盖所有临床场景的复杂性。此外,虽然评估了六种主流 LLM,但分析中仍然缺少部分最新的 LLM。为了解决这些局限性,研究团队计划在发表本文的同时发布一个医学 LLM 的 Leaderboard,旨在鼓励更多的研究人员一同不断扩展和完善医学 LLM 的综合评估基准。通过在评估过程中纳入更多来自不同文本源的任务类别,希望能更深入地了解医学领域中 LLMs 的开发情况及使用边界。
其次,尽管现在 MedS-Ins 包含了广泛的医疗任务,但它仍然不完整,还是缺少某些实用的医疗场景。为了解决这个问题,研究团队在 GitHub 上开源了所有收集到的数据和资源。由衷希望更多的临床医生或者研究学者可以一同维护扩张这个指令调整数据集,类似于通用领域中的 Super-NaturalInstructions。研究团队在 GitHub 页面上提供了详细的上传指南,同时将在论文的迭代更新中书面感谢每一位参与数据集更新的贡献者。
第三,研究团队计划在 MedS-Bench 和 MedS-Ins 中加入更多语言,以支持开发更强大的多语言医学 LLM。目前,尽管在 MedS-Bench 和 MedS-Ins 中包含了一些多语言任务,但这些资源主要以英语为中心。将其扩展到更广泛的语言范围将是一个很有前景的未来方向,以便确保医疗人工智能的最新进展能够公平地惠及更广泛、更多样的地区。
最后,研究团队已将所有代码、数据和评估流程进行开源。希望这项工作能引导医学 LLM 的开发更多的关注到如何将这些强大的语言模型与现实世界的临床应用结合。
以上是迈向「多面手」医疗大模型,上交大团队发布大规模指令微调数据、开源模型与全面基准测试的详细内容。更多信息请关注PHP中文网其他相关文章!






















