
アプリケーションにおけるコンピューティングのジレンマ
開発とフレームワーク、どちらを優先すべきですか?
Java は、アプリケーション開発で最も一般的に使用されるプログラミング言語です。しかし、Java でデータを処理するコードを記述するのは簡単ではありません。たとえば、以下は 2 つのフィールドでグループ化と集計を実行する Java コードです:
Map<Integer, Map<String, Double>> summary = new HashMap<>();
for (Order order : orders) {
int year = order.orderDate.getYear();
String sellerId = order.sellerId;
double amount = order.amount;
Map<String, Double> salesMap = summary.get(year);
if (salesMap == null) {
salesMap = new HashMap<>();
summary.put(year, salesMap);
}
Double totalAmount = salesMap.get(sellerId);
if (totalAmount == null) {
totalAmount = 0.0;
}
salesMap.put(sellerId, totalAmount + amount);
}
for (Map.Entry<Integer, Map<String, Double>> entry : summary.entrySet()) {
int year = entry.getKey();
Map<String, Double> salesMap = entry.getValue();
System.out.println("Year: " + year);
for (Map.Entry<String, Double> salesEntry : salesMap.entrySet()) {
String sellerId = salesEntry.getKey();
double totalAmount = salesEntry.getValue();
System.out.println(" Seller ID: " + sellerId + ", Total Amount: " + totalAmount);
}
}
対照的に、対応する SQL ははるかに単純です。計算を終了するには、1 つの GROUP BY 句で十分です。
注文 GROUP BY 年 (注文日)、販売者 ID から年 (注文日)、販売者 ID、合計 (金額) を選択します
確かに、初期のアプリケーションは Java と SQL を連携して動作していました。ビジネス プロセスはアプリケーション側で Java で実装され、データはバックエンド データベースの SQL で処理されました。データベースの制限により、フレームワークの拡張と移行が困難でした。これは現代のアプリケーションにとって非常に不親切でした。さらに、多くの場合、データベースが存在しないか、データベース間の計算が関与している場合、SQL は利用できませんでした。
これを考慮して、その後、多くのアプリケーションが完全に Java ベースのフレームワークを採用し始めました。このフレームワークでは、データベースは単純な読み取りおよび書き込み操作のみを実行し、ビジネス プロセスとデータ処理はアプリケーション側で Java で実装されます (特にマイクロサービスが出現したとき)。このようにして、アプリケーションはデータベースから切り離され、優れたスケーラビリティと移行性が得られます。これにより、前述の Java 開発の複雑さに直面しながらも、フレームワークの利点を得ることができます。
開発かフレームワークという 1 つの側面にのみ焦点を当てることができるようです。 Java フレームワークの利点を享受するには、困難な開発に耐えなければなりません。 SQL を使用するには、フレームワークの欠点を許容する必要があります。これによりジレンマが生じます。
それでは何ができるでしょうか?
Java のデータ処理機能を強化するのはどうでしょうか?これにより、SQL の問題が回避されるだけでなく、Java の欠点も克服されます。
実際、Java Stream/Kotlin/Scala はすべてそうしようとしています。
ストリーム
Java 8 で導入されたストリームには、多くのデータ処理メソッドが追加されました。上記の計算を実装するためのストリーム コードは次のとおりです:
Map<Integer, Map<String, Double>> summary = orders.stream()
.collect(Collectors.groupingBy(
order -> order.orderDate.getYear(),
Collectors.groupingBy(
order -> order.sellerId,
Collectors.summingDouble(order -> order.amount)
)
));
summary.forEach((year, salesMap) -> {
System.out.println("Year: " + year);
salesMap.forEach((sellerId, totalAmount) -> {
System.out.println(" Seller ID: " + sellerId + ", Total Amount: " + totalAmount);
});
});
ストリームは確かにコードをある程度簡素化します。しかし全体としては、依然として煩雑であり、SQL よりもはるかに簡潔ではありません。
Kotlin
より強力であると主張していた Kotlin は、さらに改良されました:
val summary = orders
.groupBy { it.orderDate.year }
.mapValues { yearGroup ->
yearGroup.value
.groupBy { it.sellerId }
.mapValues { sellerGroup ->
sellerGroup.value.sumOf { it.amount }
}
}
summary.forEach { (year, salesMap) ->
println("Year: $year")
salesMap.forEach { (sellerId, totalAmount) ->
println(" Seller ID: $sellerId, Total Amount: $totalAmount")
}
}
Kotlin コードはより単純ですが、改善は限られています。 SQL と比較すると、まだ大きなギャップがあります。
スカラ
次に Scala がありました:
val summary = orders
.groupBy(order => order.orderDate.getYear)
.mapValues(yearGroup =>
yearGroup
.groupBy(_.sellerId)
.mapValues(sellerGroup => sellerGroup.map(_.amount).sum)
)
summary.foreach { case (year, salesMap) =>
println(s"Year: $year")
salesMap.foreach { case (sellerId, totalAmount) =>
println(s" Seller ID: $sellerId, Total Amount: $totalAmount")
}
}
Scala は Kotlin より少し単純ですが、それでも SQL と比較することはできません。さらに、Scala は重すぎて使いにくいです。
実際、これらのテクノロジーは完璧ではありませんが、正しい道を進んでいます。
コンパイル言語はホットスワップ非対応です
さらに、Java はコンパイル言語であるため、ホット スワップをサポートしていません。コードを変更するには再コンパイルと再デプロイが必要になり、多くの場合サービスの再起動が必要になります。そのため、要件の頻繁な変更に直面した場合、最適なエクスペリエンスが得られません。対照的に、SQL ではこの点に関して問題はありません。

Java 開発は複雑であり、フレームワークにも欠点があります。 SQL はフレームワークの要件を満たすことが困難です。そのジレンマを解決するのは難しい。他に方法はありますか?
究極のソリューション – esProc SPL
esProc SPL は、純粋に Java で開発されたデータ処理言語です。シンプルな開発と柔軟なフレームワークを備えています。
簡潔な構文
上記のグループ化および集計操作の Java 実装を確認してみましょう:

Java コードと比較すると、SPL コードははるかに簡潔です:
Orders.groups(year(orderdate),sellerid;sum(amount))
SQL 実装と同じくらい簡単です:
SELECT year(orderdate),sellerid,sum(amount) FROM orders GROUP BY year(orderDate),sellerid
実際、SPL コードは、対応する SQL コードよりも単純であることがよくあります。 SPL は、順序ベースの手続き型計算をサポートしているため、複雑な計算の実行に優れています。次の例を考えてみましょう。株式の連続上昇日数の最大値を計算します。 SQL には次のような 3 層のネストされたステートメントが必要ですが、記述することはもちろん、理解することも困難です。
select max(continuousDays)-1
from (select count(*) continuousDays
from (select sum(changeSign) over(order by tradeDate) unRiseDays
from (select tradeDate,
case when closePrice>lag(closePrice) over(order by tradeDate)
then 0 else 1 end changeSign
from stock) )
group by unRiseDays)
SPL は、わずか 1 行のコードで計算を実装します。これは、Java コードは言うまでもなく、SQL コードよりもはるかに単純です。
stock.sort(tradeDate).group@i(price<price[-1]).max(~.len())
Comprehensive, independent computing capability
SPL has table sequence – the specialized structured data object, and offers a rich computing class library based on table sequences to handle a variety of computations, including the commonly seen filtering, grouping, sorting, distinct and join, as shown below:
Orders.sort(Amount) // Sorting Orders.select(Amount*Quantity>3000 && like(Client,"*S*")) // Filtering Orders.groups(Client; sum(Amount)) // Grouping Orders.id(Client) // Distinct join(Orders:o,SellerId ; Employees:e,EId) // Join ……
More importantly, the SPL computing capability is independent of databases; it can function even without a database, which is unlike the ORM technology that requires translation into SQL for execution.
Efficient and easy to use IDE
Besides concise syntax, SPL also has a comprehensive development environment offering debugging functionalities, such as “Step over” and “Set breakpoint”, and very debugging-friendly WYSIWYG result viewing panel that lets users check result for each step in real time.
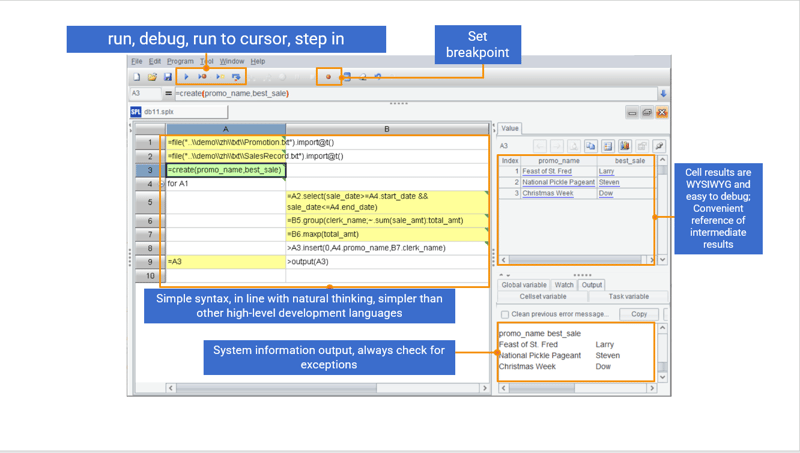
Support for large-scale data computing
SPL supports processing large-scale data that can or cannot fit into the memory.
In-memory computation:

External memory computation:

We can see that the SPL code of implementing an external memory computation and that of implementing an in-memory computation is basically the same, without extra computational load.
It is easy to implement parallelism in SPL. We just need to add @m option to the serial computing code. This is far simpler than the corresponding Java method.

Seamless integration into Java applications
SPL is developed in Java, so it can work by embedding its JARs in the Java application. And the application executes or invokes the SPL script via the standard JDBC. This makes SPL very lightweight, and it can even run on Android.
Call SPL code through JDBC:
Class.forName("com.esproc.jdbc.InternalDriver");
con= DriverManager.getConnection("jdbc:esproc:local://");
st =con.prepareCall("call SplScript(?)");
st.setObject(1, "A");
st.execute();
ResultSet rs = st.getResultSet();
ResultSetMetaData rsmd = rs.getMetaData();
As it is lightweight and integration-friendly, SPL can be seamlessly integrated into mainstream Java frameworks, especially suitable for serving as a computing engine within microservice architectures.
Highly open framework
SPL’s great openness enables it to directly connect to various types of data sources and perform real-time mixed computations, making it easy to handle computing scenarios where databases are unavailable or multiple/diverse databases are involved.

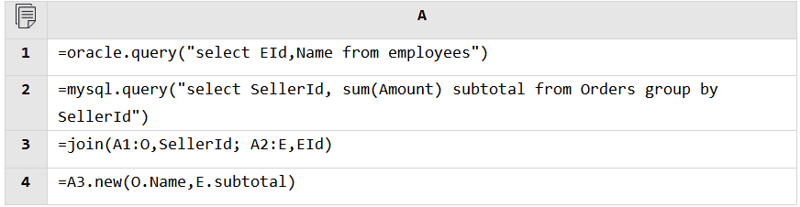
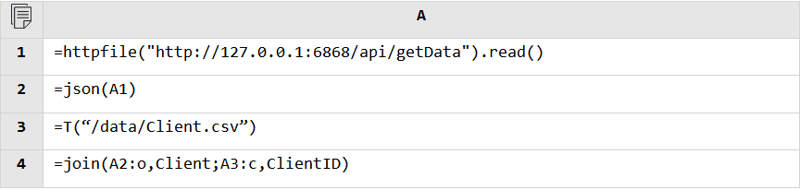
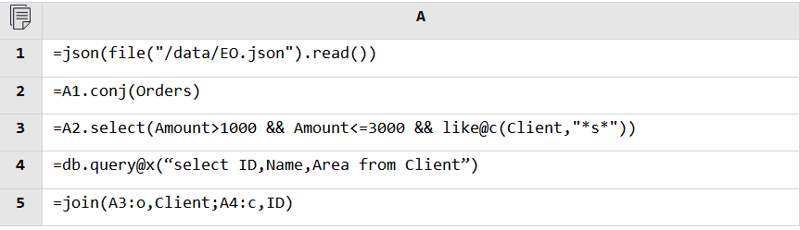
Regardless of the data source, SPL can read data from it and perform the mixed computation as long as it is accessible. Database and database, RESTful and file, JSON and database, anything is fine.
Databases:
RESTful and file:
JSON and database:
Interpreted execution and hot-swapping
SPL is an interpreted language that inherently supports hot swapping while power remains switched on. Modified code takes effect in real-time without requiring service restarts. This makes SPL well adapt to dynamic data processing requirements.

This hot—swapping capability enables independent computing modules with separate management, maintenance and operation, creating more flexible and convenient uses.
SPL can significantly increase Java programmers’ development efficiency while achieving framework advantages. It combines merits of both Java and SQL, and further simplifies code and elevates performance.
SPL open source address
以上是有些东西可以使 Java 程序员的开发效率加倍的详细内容。更多信息请关注PHP中文网其他相关文章!





















