


NVIDIA 的 Llama 3.1-Nemotron-51B 以卓越的准确性和效率树立了 AI 的新基准,可在单个 GPU 上实现高工作负载。

NVIDIA 的最新语言模型 Llama 3.1-Nemotron-51B 以卓越的准确性和效率树立了 AI 性能的新标准。该模型标志着在扩展 LLM 以适应单个 GPU 上的进步,即使在高工作负载下也是如此。
NVIDIA 推出了一种名为 Llama 3.1-Nemotron-51B 的新语言模型,有望以卓越的准确性和效率实现 AI 性能的飞跃。该模型源自 Meta 的 Llama-3.1-70B,并利用新颖的神经架构搜索 (NAS) 方法来优化准确性和效率。值得注意的是,即使在高工作负载下,该模型也可以安装在单个 NVIDIA H100 GPU 上,从而使其更易于访问且更具成本效益。
与前代产品相比,Llama 3.1-Nemotron-51B 模型的推理速度提高了 2.2 倍,同时保持了几乎相同的精度水平。由于其减少的内存占用和优化的架构,这种效率使得推理期间单个 GPU 上的工作负载增加了 4 倍。
采用大型语言模型 (LLM) 的挑战之一是其推理成本较高。 Llama 3.1-Nemotron-51B 模型通过在准确性和效率之间提供平衡权衡来解决这个问题,使其成为从边缘系统到云数据中心等各种应用的经济高效的解决方案。此功能对于通过 Kubernetes 和 NIM 蓝图部署多个模型特别有用。
Nemotron 模型使用 TensorRT-LLM 引擎进行了优化,以实现更高的推理性能,并打包为 NVIDIA NIM 推理微服务。此设置简化并加速了生成式 AI 模型在 NVIDIA 加速基础设施(包括云、数据中心和工作站)上的部署。
Llama 3.1-Nemotron-51B-Instruct 模型是使用高效的 NAS 技术和训练方法构建的,可以创建针对特定 GPU 优化的非标准 Transformer 模型。该方法包括一个块蒸馏框架,用于并行训练各种块变体,确保高效且准确的推理。
NVIDIA 的 NAS 方法允许用户在准确性和效率之间选择最佳平衡。例如,Llama-3.1-Nemotron-40B-Instruct 变体的创建是为了优先考虑速度和成本,与父模型相比,速度提高了 3.2 倍,但精度略有下降。
Llama 3.1-Nemotron-51B-Instruct模型已针对多项行业标准进行了对标,展示了其在各种场景下的卓越性能。它使参考模型的吞吐量翻倍,使其在多个用例中具有成本效益。
Llama 3.1-Nemotron-51B-Instruct 模型为用户和公司提供了一系列新的可能性,以经济高效地利用高精度基础模型。其准确性和效率之间的平衡使其成为对构建者有吸引力的选择,并突显了 NAS 方法的有效性,NVIDIA 旨在将其扩展到其他模型。
以上是的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 NVIDIA显卡录屏快捷键使用不了怎么解决?
Mar 13, 2024 pm 03:52 PM
NVIDIA显卡录屏快捷键使用不了怎么解决?
Mar 13, 2024 pm 03:52 PM
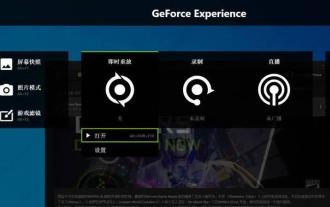
NVIDIA显卡是有自带的录屏功能的,用户们可以直接的利用快捷键录制桌面或者是游戏画面,不过也有用户们反应快捷键使用不了,那么这是怎么回事?下面就让本站来为用户们来仔细的介绍一下n卡录屏快捷键没反应问题解析吧。 n卡录屏快捷键没反应问题解析 方法一、自动录制 1、自动录制即时重放模式,玩家可以将其视为自动录制模式,首先打开NVIDIAGeForceExperience。 2、Alt+Z键呼出软件菜单之后,点击即时重放下方的打开按钮即可开始录制,或通过Alt+Shift+F10快捷键开
 Win11右键没有nvidia控制面板解决方法?
Feb 20, 2024 am 10:20 AM
Win11右键没有nvidia控制面板解决方法?
Feb 20, 2024 am 10:20 AM
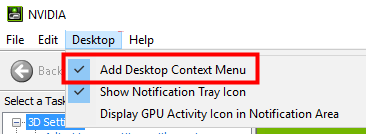
Win11右键没有nvidia控制面板解决方法?很多的用户们在使用电脑的时候都会经常需要打开nvidia控制面板,但是也有不少的用户们发现自己找不到nvidia控制面板,那么这要怎么办?下面就让本站来为用户们来仔细的介绍一下Win11右键没有nvidia控制面板的解决方法吧。Win11右键没有nvidia控制面板的解决方法1、确保它没有被隐藏按键盘上的Windows+R以打开一个新的运行框并输入control。在右上角的查看方式下:选择大图标。打开NVIDIA控制面板,将鼠标悬停在桌面选项上查看
 中国大陆和港澳市场专属版:NVIDIA即将发布RTX 4090D显卡
Dec 01, 2023 am 11:34 AM
中国大陆和港澳市场专属版:NVIDIA即将发布RTX 4090D显卡
Dec 01, 2023 am 11:34 AM
11月16日,NVIDIA正在积极研发专为中国大陆及港澳地区设计的新版本显卡RTX4090D,以应对当地的生产和销售禁令。这款特别版显卡将带来一系列独特的特性和设计调整,以适应当地市场的特殊需求和规定。该显卡以中国龙年2024年为寓意,因此在名称中加入了“D”,代表“Dragon”据业内消息透露,这款RTX4090D将采用一个与原版RTX4090不同的GPU核心,编号为AD102-250。这一编号与RTX4090上的AD102-300/301相比,在数字上显得更低,预示着可能的性能降级。根据NV
 全新优化路径追踪模组让《赛博朋克 2077》性能提升高达 40%
Aug 10, 2024 pm 09:45 PM
全新优化路径追踪模组让《赛博朋克 2077》性能提升高达 40%
Aug 10, 2024 pm 09:45 PM
《赛博朋克 2077》的突出功能之一是路径追踪,但它会对性能造成严重影响。即使系统具有相当强大的显卡,例如 RTX 4080(Gigabyte AERO OC,亚马逊上的售价为 949.99 美元),也很难提供稳定的性能。
 OneXGPU 2 中的 AMD Radeon RX 7800M 性能优于 Nvidia RTX 4070 笔记本电脑 GPU
Sep 09, 2024 am 06:35 AM
OneXGPU 2 中的 AMD Radeon RX 7800M 性能优于 Nvidia RTX 4070 笔记本电脑 GPU
Sep 09, 2024 am 06:35 AM
OneXGPU 2 是首款搭载 Radeon RX 7800M 的 eGPU,而 AMD 尚未宣布推出这款 GPU。据外置显卡方案制造商One-Netbook透露,AMD新GPU基于RDNA 3架构,拥有Navi
 详解NVIDIA显卡驱动安装失败怎么办
Mar 14, 2024 am 08:43 AM
详解NVIDIA显卡驱动安装失败怎么办
Mar 14, 2024 am 08:43 AM
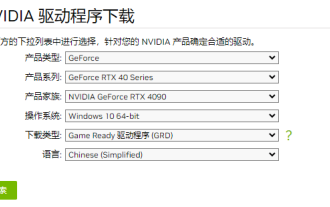
NVIDIA是目前使用人数最多的显卡厂商,很多用户都会首选给自己的电脑安装NVIDIA显卡。但是在使用过程中不免会遇到一些问题,比如NVIDIA驱动程序安装失败,这该如何解决?导致这种情况的原因有很多,下面就来看看具体的解决办法。 步骤一:下载最新的显卡驱动 您需要前往NVIDIA官网下载适用于您的显卡的最新驱动程序。进入驱动程序页面后,选择您的产品类型、产品系列、产品家族、操作系统、下载类型和语言。点击搜索后,网站将自动查询适合您的驱动程序版本。 以搭载GeForceRTX4090的
 无法连接到nvidia怎么解决
Dec 06, 2023 pm 03:18 PM
无法连接到nvidia怎么解决
Dec 06, 2023 pm 03:18 PM
无法连接到nvidia的解决办法:1、检查网络连接;2、检查防火墙设置;3、检查代理设置;4、使用其他网络连接;5、检查NVIDIA服务器状态;6、更新驱动程序;7、重新启动NVIDIA的网络服务。详细介绍:1、检查网络连接,确保计算机正常连接到互联网,可以尝试重新启动路由器或调整网络设置,以确保可以连接到NVIDIA服务;2、检查防火墙设置,防火墙可能会阻止计算机等等。
 nvidia控制面板首选图形处理器在哪-nvidia控制面板首选图形处理器位置介绍
Mar 04, 2024 pm 01:50 PM
nvidia控制面板首选图形处理器在哪-nvidia控制面板首选图形处理器位置介绍
Mar 04, 2024 pm 01:50 PM
小伙伴们知道nvidia控制面板首选图形处理器在哪吗?今天小编就来讲解nvidia控制面板首选图形处理器的位置介绍,感兴趣的快跟小编一起来看看吧,希望能够帮助到大家。1、我们需要右键桌面空白处,打开“nvidia控制面板”(如图所示)。2、然后进入左边“3D设置”下的“管理3D设置”(如图所示)。3、进入后,在右边就能找到“首选图形处理器”了(如图所示)。