

构建机器学习模型时的数据集

L'une des plus grandes difficultés pour ceux qui commencent à étudier l'apprentissage automatique est peut-être de travailler, de traiter les données, de faire de petites inférences, puis d'assembler votre modèle.
Dans cet article, je vais illustrer comment analyser un ensemble de données pour mieux construire un modèle de Machine Learning en passant par :
- Brève explication de ce qu'est l'apprentissage automatique
- Types et différences d'apprentissage
- Comprendre et extraire les informations importantes de l'ensemble de données
- Traiter les données d'un ensemble de données
- Différences entre les algorithmes d'un modèle
- Construction d'un modèle de régression linéaire
Mais commençons par le début, pour pouvoir contextualiser, qu'est-ce que le Machine Learning (ML) ?
Le ML est l'une des différentes branches de l'intelligence artificielle (IA), au même titre que les réseaux de neurones ou la robotique, et autres. Le type d'apprentissage automatique dépend de la façon dont les données sont structurées, elles peuvent donc être divisées en différents types, créant ainsi un modèle. Un modèle ML est créé à l'aide d'algorithmes qui traitent les données d'entrée et apprennent à prédire ou à classer les résultats.
L'importance d'un ensemble de données
Pour créer un modèle ML, nous avons besoin d'un ensemble de données, dans l'ensemble de données il doit y avoir nos fonctionnalités d'entrée, qui sont essentiellement l'intégralité de notre ensemble de données à l'exception de la colonne cible en fonction de notre type d'apprentissage, s'il s'agit d'un apprentissage supervisé, l'ensemble de données doit contenir les cibles, ou les étiquettes, ou les réponses correctes, car ces informations seront utilisées pour entraîner et tester le modèle.
Quelques types d'apprentissage et la structure de l'ensemble de données correspondant :
- Apprentissage supervisé : Ici, le modèle apprend à travers un ensemble de données étiquetées, avec des sorties correctes déjà fournies, le modèle vise donc à apprendre à associer entrées et sorties pour pouvoir faire ses prédictions correctement pour les nouvelles données.
- Apprentissage non supervisé : La formation du modèle est effectuée avec des données non étiquetées, il n'y a pas de sortie correcte associée à l'entrée, l'objectif du modèle est donc d'identifier des modèles et des regroupements dans les données.
- Apprentissage par renforcement : En cela, le modèle apprend de l'interaction avec l'environnement. Il prendra des mesures dans l'environnement et recevra une récompense pour les actions correctes ou recevra une pénalité pour les mauvaises actions, dans le but de maximiser pleinement les récompenses à long terme en maximisant le comportement qui a conduit à l'exécution des actions correctes.
Par conséquent, l'ensemble de données définit essentiellement l'ensemble du comportement et du processus d'apprentissage du modèle généré par la machine.
Pour continuer avec les exemples, j'utiliserai un ensemble de données avec des étiquettes, illustrant un modèle avec Supervised Learning, où l'objectif sera de définir la valeur mensuelle de l'assurance-vie pour un public spécifique.
Commençons par charger notre ensemble de données et voyons ses premières lignes.
import pandas as pd
data = pd.read_csv('../dataset_seguro_vida.csv')
data.head()
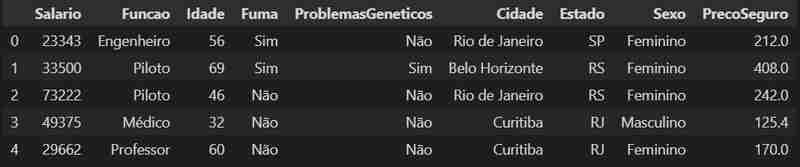
Détaillons un peu plus nos données, nous pouvons voir son format, et découvrir le nombre de lignes et de colonnes dans l'ensemble de données.
data.shape

Nous avons ici une structure de données de 500 lignes et 9 colonnes.
Voyons maintenant de quels types de données nous disposons et s'il nous manque des données.
data.info()
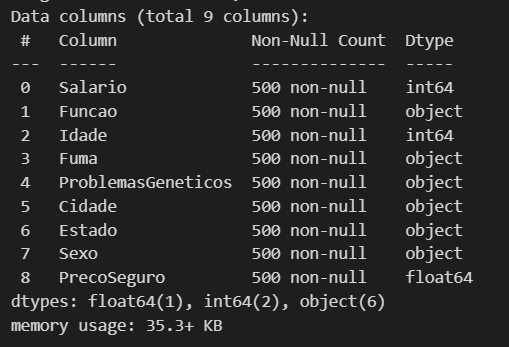
Nous avons ici 3 colonnes numériques, dont 2 int (nombres entiers) et 1 float (nombres avec décimales), et les 6 autres sont des objets. On peut donc passer un peu à l'étape suivante du traitement des données.
Travailler l'ensemble de données
Une bonne étape vers l'amélioration de notre ensemble de données est de comprendre que certains types de données sont traités et même compris plus facilement par le modèle que d'autres. Par exemple, les données de type objet sont plus lourdes et même limitées à travailler, il est donc préférable de les transformer en catégorie, car cela nous permet d'avoir plusieurs gains depuis les performances jusqu'à l'efficacité dans l'utilisation de la mémoire (dans Dans le fin, on peut même améliorer cela en faisant une autre transformation, mais le moment venu j'expliquerai mieux).
object_columns = data.select_dtypes(include='object').columns
for col in object_columns:
data[col] = data[col].astype('category')
data.dtypes

Como o nosso objetivo é conseguir estipular o valor da mensalidade de um seguro de vida, vamos dar uma olhada melhor nas nossas variáveis numéricas usando a transposição.
data.describe().T

Podemos aqui ver alguns detalhes e valores dos nossos inputs numéricos, como a média aritmética, o valor mínimo e máximo. Através desses dados podemos fazer a separação desses valores em grupos baseados em algum input de categoria, por gênero, se fuma ou não, entre outros, como demonstração vamos fazer a separação por sexo, para visualizar a media aritmética das colunas divididas por sexo.
value_based_on_sex = data.groupby("Sexo").mean("PrecoSeguro")
value_based_on_sex

Como podemos ver que no nosso dataset os homens acabam pagando um preço maior de seguro (lembrando que esse dataset é fictício).
Podemos ter uma melhor visualização dos dados através do seaborn, é uma biblioteca construída com base no matplotlib usada especificamente para plotar gráficos estatísticos.
import seaborn as sns
sns.set_style("whitegrid")
sns.pairplot(
data[["Idade", "Salario", "PrecoSeguro", "Sexo"]],
hue = "Sexo",
height = 3,
palette = "Set1")
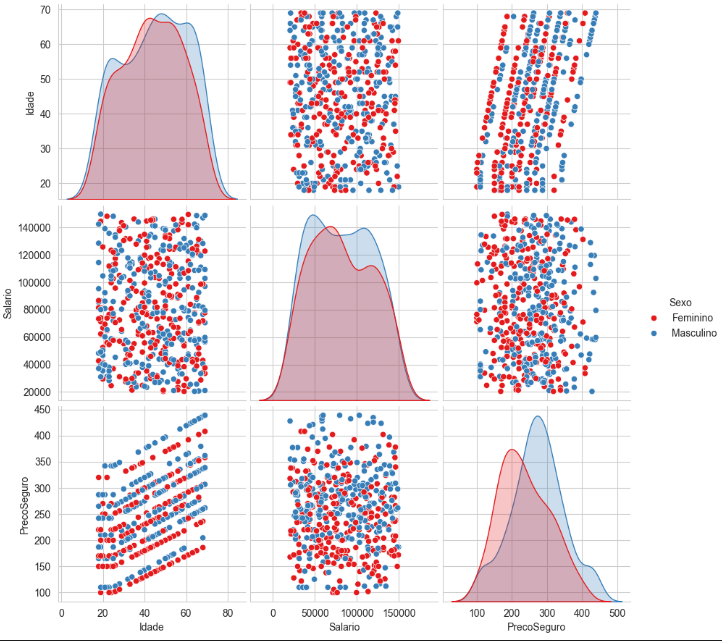
Aqui podemos visualizar a distribuição desses valores através dos gráficos ficando mais claro a separação do conjunto, com base no grupo que escolhemos, como um teste você pode tentar fazer um agrupamento diferente e ver como os gráficos vão ficar.
Vamos criar uma matriz de correlação, sendo essa uma outra forma de visualizar a relação das variáveis numéricas do dataset, com o auxilio visual de um heatmap.
numeric_data = data.select_dtypes(include=['float64', 'int64']) corr_matrix = numeric_data.corr() sns.heatmap(corr_matrix, annot= True)
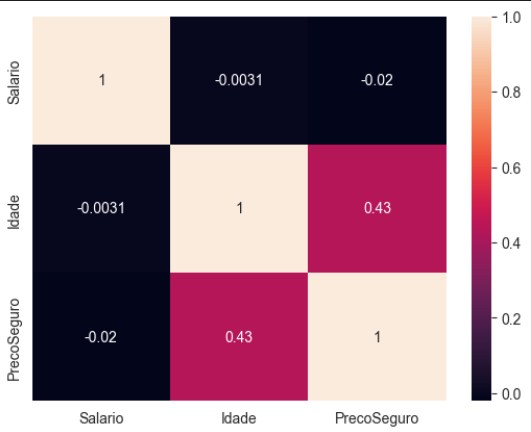
Essa matriz transposta nos mostra quais variáveis numéricas influenciam mais no nosso modelo, é um pouco intuitivo quando você olha para a imagem, podemos observar que a idade é a que mais vai interferir no preço do seguro.
Basicamente essa matriz funciona assim:
Os valores variam entre -1 e 1:
1: Correlação perfeita positiva - Quando uma variável aumenta, a outra também aumenta proporcionalmente.
0: Nenhuma correlação - Não há relação linear entre as variáveis.
-1: Correlação perfeita negativa - Quando uma variável aumenta, a outra diminui proporcionalmente.
Lembra da transformada que fizemos de object para category nos dados, agora vem a outra melhoria comentada, com os dados que viraram category faremos mais uma transformada, dessa vez a ideia é transformar essa variáveis categóricas em representações numéricas, isso nos permitirá ter um ganho incrível com o desempenho do modelo já que ele entende muito melhor essas variáveis numéricas.
Conseguimos fazer isso facilmente com a lib do pandas, o que ele faz é criar nova colunas binarias para valores distintos, o pandas é uma biblioteca voltada principalmente para analise de dados e estrutura de dados, então ela já possui diversas funcionalidades que nos auxiliam nos processo de tratamento do dataset.
data = pd.get_dummies(data)

Pronto agora temos nossas novas colunas para as categorias.
Decidindo o Algoritmo
Para a construção do melhor modelo, devemos saber qual o algoritmo ideal para o propósito da ML, na tabela seguinte vou deixar um resumo simplificado de como analisar seu problema e fazer a melhor escolha.

Olhando a tabela podemos ver que o problema que temos que resolver é o de regressão. Aqui vai mais uma dica, sempre comesse simples e vá incrementando seu e fazendo os ajustes necessários até os valores de previsibilidade do modelo ser satisfatório.
Para o nosso exemplo vamos montar um modelo de Regressão Linear, já que temos uma linearidade entre os nossos inputs e temos como target uma variável numérica.
Sabemos que a nossa variável target é a coluna PrecoSeguro , as outras são nossos inputs. Os inputs em estatísticas são chamadas de variável independente e o target de variável dependente, pelos nomes fica claro que a ideia é que o nosso target é uma variável que depende dos nosso inputs, se os inputs variam nosso target tem que vai variar também.
Vamos definir nosso y com o target
y = data["PrecoSeguro"]
E para x vamos remover a coluna target e inserir todas as outras
X = data.drop("PrecoSeguro", axis = 1)
Antes de montarmos o modelo, nosso dataset precisa ser dividido uma parte para teste e outra para o treino, para fazer isso vamos usar do scikit-learn o método train_test_split.
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(
X,y,
train_size = 0.80,
random_state = 1)
Aqui dividimos o nosso dataset em 80% para treino e 20% para testes. Agora podemos montar o nosso modelo.
from sklearn.linear_model import LinearRegression lr = LinearRegression() lr.fit(X_train,y_train)
Modelo montado agora podemos avaliar seu desempenho
lr.score(X_test, y_test). lr.score(X_train, y_train)
Aqui podemos analisar a o coeficiente de determinação do nosso modelo para testes e para o treinamento.
Podemos usar um outro método para poder descobrir o desvio padrão do nosso modelo, e entender a estabilidade e a confiabilidade do desempenho do modelo para a amostra
<p>from sklearn.metrics import mean_squared_error<br> import math</p> <p>y_pred = lr.predict(X_test)<br> math.sqrt(mean_squared_error(y_test, y_pred))</p>
Considerações
O valor perfeito do coeficiente de determinação é 1, quanto mais próximo desse valor, teoricamente melhor seria o nosso modelo, mas um ponto de atenção é basicamente impossível você conseguir um modelo perfeito, até mesmo algo acima de 0.95 é de se desconfiar.
Se você tiver trabalhando com dados reais e conseguir um valor desse é bom analisar o seu modelo, testar outras abordagens e até mesmo revisar seu dataset, pois seu modelo pode estar sofrendo um overfitting e por isso apresenta esse resultado quase que perfeitos.
Aqui como montamos um dataset com valores irreais e sem nenhum embasamento é normal termos esses valores quase que perfeitos.
Deixarei aqui um link para o github do código e dataset usados nesse post
- GitHub
以上是构建机器学习模型时的数据集的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 Python:游戏,Guis等
Apr 13, 2025 am 12:14 AM
Python:游戏,Guis等
Apr 13, 2025 am 12:14 AM
Python在游戏和GUI开发中表现出色。1)游戏开发使用Pygame,提供绘图、音频等功能,适合创建2D游戏。2)GUI开发可选择Tkinter或PyQt,Tkinter简单易用,PyQt功能丰富,适合专业开发。
 Python与C:学习曲线和易用性
Apr 19, 2025 am 12:20 AM
Python与C:学习曲线和易用性
Apr 19, 2025 am 12:20 AM
Python更易学且易用,C 则更强大但复杂。1.Python语法简洁,适合初学者,动态类型和自动内存管理使其易用,但可能导致运行时错误。2.C 提供低级控制和高级特性,适合高性能应用,但学习门槛高,需手动管理内存和类型安全。
 Python和时间:充分利用您的学习时间
Apr 14, 2025 am 12:02 AM
Python和时间:充分利用您的学习时间
Apr 14, 2025 am 12:02 AM
要在有限的时间内最大化学习Python的效率,可以使用Python的datetime、time和schedule模块。1.datetime模块用于记录和规划学习时间。2.time模块帮助设置学习和休息时间。3.schedule模块自动化安排每周学习任务。
 Python vs.C:探索性能和效率
Apr 18, 2025 am 12:20 AM
Python vs.C:探索性能和效率
Apr 18, 2025 am 12:20 AM
Python在开发效率上优于C ,但C 在执行性能上更高。1.Python的简洁语法和丰富库提高开发效率。2.C 的编译型特性和硬件控制提升执行性能。选择时需根据项目需求权衡开发速度与执行效率。
 Python标准库的哪一部分是:列表或数组?
Apr 27, 2025 am 12:03 AM
Python标准库的哪一部分是:列表或数组?
Apr 27, 2025 am 12:03 AM
pythonlistsarepartofthestAndArdLibrary,herilearRaysarenot.listsarebuilt-In,多功能,和Rused ForStoringCollections,而EasaraySaraySaraySaraysaraySaraySaraysaraySaraysarrayModuleandleandleandlesscommonlyusedDduetolimitedFunctionalityFunctionalityFunctionality。
 Python:自动化,脚本和任务管理
Apr 16, 2025 am 12:14 AM
Python:自动化,脚本和任务管理
Apr 16, 2025 am 12:14 AM
Python在自动化、脚本编写和任务管理中表现出色。1)自动化:通过标准库如os、shutil实现文件备份。2)脚本编写:使用psutil库监控系统资源。3)任务管理:利用schedule库调度任务。Python的易用性和丰富库支持使其在这些领域中成为首选工具。
 学习Python:2小时的每日学习是否足够?
Apr 18, 2025 am 12:22 AM
学习Python:2小时的每日学习是否足够?
Apr 18, 2025 am 12:22 AM
每天学习Python两个小时是否足够?这取决于你的目标和学习方法。1)制定清晰的学习计划,2)选择合适的学习资源和方法,3)动手实践和复习巩固,可以在这段时间内逐步掌握Python的基本知识和高级功能。
 Python vs. C:了解关键差异
Apr 21, 2025 am 12:18 AM
Python vs. C:了解关键差异
Apr 21, 2025 am 12:18 AM
Python和C 各有优势,选择应基于项目需求。1)Python适合快速开发和数据处理,因其简洁语法和动态类型。2)C 适用于高性能和系统编程,因其静态类型和手动内存管理。
