
谁不想从他们的文档中得到即时答案?这正是 RAG 聊天机器人所做的——将检索与人工智能生成相结合,以实现快速、准确的响应!
在本指南中,我将向您展示如何使用 检索增强生成 (RAG) 以及 LangChain 和 Streamlit 创建聊天机器人。该聊天机器人将从知识库中提取相关信息并使用语言模型生成响应。
我将引导您完成每个步骤,提供多种响应生成选项,无论您使用 OpenAI、Gemini 还是 Fireworks — 确保灵活和具有成本效益的解决方案。
RAG 是一种结合了检索和生成的方法,以提供更准确和上下文感知的聊天机器人响应。检索过程从知识库中提取相关文档,而生成过程则使用语言模型根据检索到的内容创建连贯的响应。这确保您的聊天机器人可以使用最新数据回答问题,即使语言模型本身尚未针对该信息进行专门训练。
想象一下您有一位私人助理,但他并不总是知道您问题的答案。因此,当你提出问题时,他们会翻阅书籍并找到相关信息(检索),然后他们总结这些信息并用自己的话告诉你(生成)。这本质上就是 RAG 的工作原理,结合了两全其美的优点。
在流程图中,RAG 流程有点像这样:
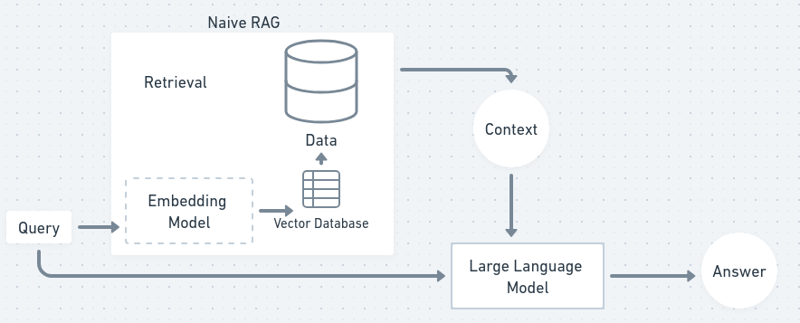
现在,让我们开始吧,建立我们自己的聊天机器人!
本教程中我们将主要使用 Python,如果您是 JS 头,您可以按照说明并浏览 langchain js 的文档。
首先,我们需要设置项目环境。这包括创建项目目录、安装依赖项以及为不同语言模型设置 API 密钥。
首先创建项目文件夹和虚拟环境:
mkdir rag-chatbot cd rag-chatbot python -m venv venv source venv/bin/activate
接下来,创建一个requirements.txt 文件来列出所有必需的依赖项:
langchain==0.0.329 streamlit==1.27.2 faiss-cpu==1.7.4 python-dotenv==1.0.0 tiktoken==0.5.1 openai==0.27.10 gemini==0.3.1 fireworks==0.4.0 sentence_transformers==2.2.2
现在,安装这些依赖项:
pip install -r requirements.txt
我们将使用 OpenAI、Gemini 或 Fireworks 来生成聊天机器人的响应。您可以根据自己的喜好选择其中任何一个。
如果您正在尝试,请不要担心,Fireworks 免费提供价值 1 美元的 API 密钥,gemini-1.5-flash 模型在一定程度上也是免费的!
设置 .env 文件来存储您首选模型的 API 密钥:
mkdir rag-chatbot cd rag-chatbot python -m venv venv source venv/bin/activate
请务必注册这些服务并获取您的 API 密钥。 Gemini 和 Fireworks 均提供免费套餐,而 OpenAI 根据使用情况收费。
为了给聊天机器人提供上下文,我们需要处理文档并将它们分成可管理的块。这很重要,因为需要分解大文本以进行嵌入和索引。
创建一个名为 document_processor.py 的新 Python 脚本来处理文档处理:
langchain==0.0.329 streamlit==1.27.2 faiss-cpu==1.7.4 python-dotenv==1.0.0 tiktoken==0.5.1 openai==0.27.10 gemini==0.3.1 fireworks==0.4.0 sentence_transformers==2.2.2
此脚本加载一个文本文件,并将其分割成约 1000 个字符的较小块,并有少量重叠,以确保块之间不会丢失上下文。处理完成后,文档就可以嵌入并建立索引了。
现在我们已经对文档进行了分块,下一步是将它们转换为嵌入(文本的数字表示)并为它们建立索引以便快速检索。 (因为机器理解数字比理解单词更容易)
创建另一个名为 embedding_indexer.py 的脚本:
pip install -r requirements.txt
在此脚本中,嵌入是使用 Hugging Face 模型(all-MiniLM-L6-v2)创建的。然后,我们将这些嵌入存储在 FAISS 矢量存储中,这使我们能够根据查询快速检索相似的文本块。
令人兴奋的部分来了:将检索与语言生成相结合!现在,您将创建一个 RAG 链 ,它从向量存储中获取相关块并使用语言模型生成响应。 (向量存储是一个数据库,我们存储转换为数字作为向量的数据)
让我们创建文件 rag_chain.py:
# Uncomment your API key # OPENAI_API_KEY=your_openai_api_key_here # GEMINI_API_KEY=your_gemini_api_key_here # FIREWORKS_API_KEY=your_fireworks_api_key_here
在这里,我们根据您提供的 API 密钥在 OpenAI、Gemini 或 Fireworks 之间进行选择。 RAG 链将检索前 3 个最相关的文档,并使用语言模型生成响应。
您可以根据自己的预算或使用偏好在模型之间切换 - Gemini 和 Fireworks 是免费的,而 OpenAI 根据使用情况收费。
现在,我们将构建一个简单的聊天机器人界面,以使用我们的 RAG 链获取用户输入并生成响应。
创建一个名为chatbot.py的新文件:
mkdir rag-chatbot cd rag-chatbot python -m venv venv source venv/bin/activate
此脚本创建一个命令行聊天机器人界面,持续侦听用户输入,通过 RAG 链对其进行处理,并返回生成的响应。
是时候使用 Streamlit 构建 Web 界面,让您的聊天机器人更加用户友好。这将允许用户通过浏览器与您的聊天机器人交互。
创建app.py:
langchain==0.0.329 streamlit==1.27.2 faiss-cpu==1.7.4 python-dotenv==1.0.0 tiktoken==0.5.1 openai==0.27.10 gemini==0.3.1 fireworks==0.4.0 sentence_transformers==2.2.2
要运行您的 Streamlit 应用程序,只需使用:
pip install -r requirements.txt
这将启动一个网络界面,您可以在其中上传文本文件、提出问题并从聊天机器人接收答案。
为了获得更好的性能,您可以在分割文本时尝试块大小和重叠。较大的块提供更多上下文,但较小的块可能使检索速度更快。您还可以使用 Streamlit 缓存 来避免重复生成嵌入等昂贵的操作。
如果您想优化成本,可以根据查询复杂度在 OpenAI、Gemini 或 Fireworks 之间切换 — 使用 OpenAI 对于复杂的问题,Gemini 或 Fireworks 对于更简单的问题以降低成本。
恭喜!您已成功创建自己的基于 RAG 的聊天机器人。现在,可能性是无限的:
旅程从这里开始,潜力无限!
您可以在 GitHub 上关注我的工作。请随时与我联系 - 我的 DM 在 X 和 LinkedIn 上始终开放。
以上是创建您自己的 AI RAG 聊天机器人:LangChain 的 Python 指南的详细内容。更多信息请关注PHP中文网其他相关文章!






















