

Gosync.WaitGroup 和对齐问题

This post is part of a series about handling concurrency in Go:
- Go sync.Mutex: Normal and Starvation Mode
- Go sync.WaitGroup and The Alignment Problem (We're here)
- Go sync.Pool and the Mechanics Behind It
- Go sync.Cond, the Most Overlooked Sync Mechanism
- Go sync.Map: The Right Tool for the Right Job
- Go Singleflight Melts in Your Code, Not in Your DB
WaitGroup is basically a way to wait for several goroutines to finish their work.
Each of sync primitives has its own set of problems, and this one's no different. We're going to focus on the alignment issues with WaitGroup, which is why its internal structure has changed across different versions.
This article is based on Go 1.23. If anything changes down the line, feel free to let me know through X(@func25).
What is sync.WaitGroup?
If you're already familiar with sync.WaitGroup, feel free to skip ahead.
Let's dive into the problem first, imagine you've got a big job on your hands, so you decide to break it down into smaller tasks that can run simultaneously, without depending on each other.
To handle this, we use goroutines because they let these smaller tasks run concurrently:
func main() {
for i := 0; i < 10; i++ {
go func(i int) {
fmt.Println("Task", i)
}(i)
}
fmt.Println("Done")
}
// Output:
// Done
But here's the thing, there's a good chance that the main goroutine finishes up and exits before the other goroutines are done with their work.
When we're spinning off many goroutines to do their thing, we want to keep track of them so that the main goroutine doesn't just finish up and exit before everyone else is done. That's where the WaitGroup comes in. Each time one of our goroutines wraps up its task, it lets the WaitGroup know.
Once all the goroutines have checked in as ‘done,' the main goroutine knows it's safe to finish, and everything wraps up neatly.
func main() {
var wg sync.WaitGroup
wg.Add(10)
for i := 0; i < 10; i++ {
go func(i int) {
defer wg.Done()
fmt.Println("Task", i)
}(i)
}
wg.Wait()
fmt.Println("Done")
}
// Output:
// Task 0
// Task 1
// Task 2
// Task 3
// Task 4
// Task 5
// Task 6
// Task 7
// Task 8
// Task 9
// Done
So, here's how it typically goes:
- Adding goroutines: Before starting your goroutines, you tell the WaitGroup how many to expect. You do this with WaitGroup.Add(n), where n is the number of goroutines you're planning to run.
- Goroutines running: Each goroutine goes off and does its thing. When it's done, it should let the WaitGroup know by calling WaitGroup.Done() to reduce the counter by one.
- Waiting for all goroutines: In the main goroutine, the one not doing the heavy lifting, you call WaitGroup.Wait(). This pauses the main goroutine until that counter in the WaitGroup reaches zero. In plain terms, it waits until all the other goroutines have finished and signaled they're done.
Usually, you'll see WaitGroup.Add(1) being used when firing up a goroutine:
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
defer wg.Done()
...
}()
}
Both ways are technically fine, but using wg.Add(1) has a small performance hit. Still, it's less error-prone compared to using wg.Add(n).
"Why is wg.Add(n) considered error-prone?"
The point is this, if the logic of the loop changes down the road, like if someone adds a continue statement that skips certain iterations, things can get messy:
wg.Add(10)
for i := 0; i < 10; i++ {
if someCondition(i) {
continue
}
go func() {
defer wg.Done()
...
}()
}
In this example, we're using wg.Add(n) before the loop, assuming the loop will always start exactly n goroutines.
But if that assumption doesn't hold, like if some iterations get skipped, your program might get stuck waiting for goroutines that were never started. And let's be honest, that's the kind of bug that can be a real pain to track down.
In this case, wg.Add(1) is more suitable. It might come with a tiny bit of performance overhead, but it's a lot better than dealing with the human error overhead.
There's also a pretty common mistake people make when using sync.WaitGroup:
for i := 0; i < 10; i++ {
go func() {
wg.Add(1)
defer wg.Done()
...
}()
}
Here's what it comes down to, wg.Add(1) is being called inside the goroutine. This can be an issue because the goroutine might start running after the main goroutine has already called wg.Wait().
That can cause all sorts of timing problems. Also, if you notice, all the examples above use defer with wg.Done(). It indeed should be used with defer to avoid issues with multiple return paths or panic recovery, making sure that it always gets called and doesn't block the caller indefinitely.
That should cover all the basics.
How sync.WaitGroup Looks Like?
Let's start by checking out the source code of sync.WaitGroup. You'll notice a similar pattern in sync.Mutex.
Again, if you're not familiar with how a mutex works, I strongly suggest you check out this article first: Go Sync Mutex: Normal & Starvation Mode.
type WaitGroup struct {
noCopy noCopy
state atomic.Uint64
sema uint32
}
type noCopy struct{}
func (*noCopy) Lock() {}
func (*noCopy) Unlock() {}
In Go, it's easy to copy a struct by just assigning it to another variable. But some structs, like WaitGroup, really shouldn't be copied.
Copying a WaitGroup can mess things up because the internal state that tracks the goroutines and their synchronization can get out of sync between the copies. If you've read the mutex post, you'll get the idea, imagine what could go wrong if we copied the internal state of a mutex.
The same kind of issues can happen with WaitGroup.
noCopy
The noCopy struct is included in WaitGroup as a way to help prevent copying mistakes, not by throwing errors, but by serving as a warning. It was contributed by Aliaksandr Valialkin, CTO of VictoriaMetrics, and was introduced in change #22015.
The noCopy struct doesn't actually affect how your program runs. Instead, it acts as a marker that tools like go vet can pick up on to detect when a struct has been copied in a way that it shouldn't be.
type noCopy struct{}
func (*noCopy) Lock() {}
func (*noCopy) Unlock() {}
Its structure is super simple:
- It has no fields, so it doesn't take up any meaningful space in memory.
- It has two methods, Lock and Unlock, which do nothing (no-op). These methods are there just to work with the -copylocks checker in the go vet tool.
When you run go vet on your code, it checks to see if any structs with a noCopy field, like WaitGroup, have been copied in a way that could cause issues.
It will throw an error to let you know there might be a problem. This gives you a heads-up to fix it before it turns into a bug:
func main() {
var a sync.WaitGroup
b := a
fmt.Println(a, b)
}
// go vet:
// assignment copies lock value to b: sync.WaitGroup contains sync.noCopy
// call of fmt.Println copies lock value: sync.WaitGroup contains sync.noCopy
// call of fmt.Println copies lock value: sync.WaitGroup contains sync.noCopy
In this case, go vet will warn you about 3 different spots where the copying happens. You can try it yourself at: Go Playground.
Note that it's purely a safeguard for when we're writing and testing our code, we can still run it like normal.
Internal State
The state of a WaitGroup is stored in an atomic.Uint64 variable. You might have guessed this if you've read the mutex post, there are several things packed into this single value.

Here's how it breaks down:
- Counter (high 32 bits): This part keeps track of the number of goroutines the WaitGroup is waiting for. When you call wg.Add() with a positive value, it bumps up this counter, and when you call wg.Done(), it decreases the counter by one.
- Waiter (low 32 bits): This tracks the number of goroutines currently waiting for that counter (the high 32 bits) to hit zero. Every time you call wg.Wait(), it increases this "waiter" count. Once the counter reaches zero, it releases all the goroutines that were waiting.
Then there's the final field, sema uint32, which is an internal semaphore managed by the Go runtime.
when a goroutine calls wg.Wait() and the counter isn't zero, it increases the waiter count and then blocks by calling runtime_Semacquire(&wg.sema). This function call puts the goroutine to sleep until it gets woken up by a corresponding runtime_Semrelease(&wg.sema) call.
We'll dive deeper into this in another article, but for now, I want to focus on the alignment issues.
Alignment Problem
I know, talking about history might seem dull, especially when you just want to get to the point. But trust me, knowing the past is the best way to understand where we are now.
Let's take a quick look at how WaitGroup has evolved over several Go versions:
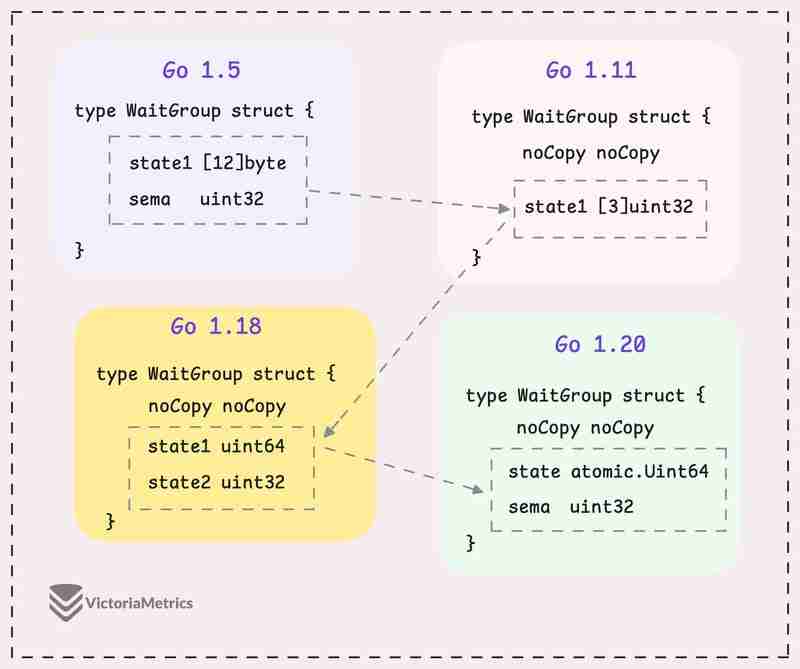
I can tell you, the core of WaitGroup (the counter, waiter, and semaphore) hasn't really changed across different Go versions. However, the way these elements are structured has been modified many times.
When we talk about alignment, we're referring to the need for data types to be stored at specific memory addresses to allow for efficient access.
For example, on a 64-bit system, a 64-bit value like uint64 should ideally be stored at a memory address that's a multiple of 8 bytes. The reason is, the CPU can grab aligned data in one go, but if the data isn't aligned, it might take multiple operations to access it.
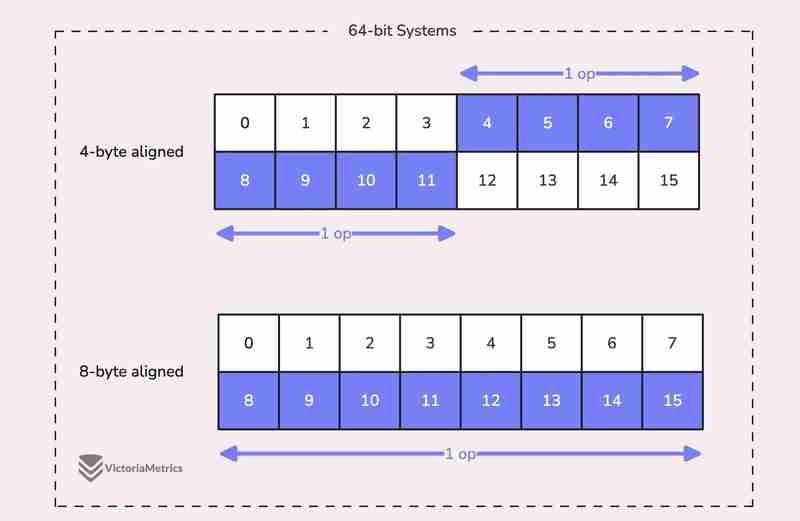
Now, here's where things get tricky:
On 32-bit architectures, the compiler doesn't guarantee that 64-bit values will be aligned on an 8-byte boundary. Instead, they might only be aligned on a 4-byte boundary.
This becomes a problem when we use the atomic package to perform operations on the state variable. The atomic package specifically notes:
"On ARM, 386, and 32-bit MIPS, it is the caller's responsibility to arrange for 64-bit alignment of 64-bit words accessed atomically via the primitive atomic functions." - atomic package note
What this means is that if we don't align the state uint64 variable to an 8-byte boundary on these 32-bit architectures, it could cause the program to crash.
So, what's the fix? Let's take a look at how this has been handled across different versions.
Go 1.5: state1 [12]byte
I'd recommend taking a moment to guess the underlying logic of this solution as you read the code below, then we'll walk through it together.
type WaitGroup struct {
state1 [12]byte
sema uint32
}
func (wg *WaitGroup) state() *uint64 {
if uintptr(unsafe.Pointer(&wg.state1))%8 == 0 {
return (*uint64)(unsafe.Pointer(&wg.state1))
} else {
return (*uint64)(unsafe.Pointer(&wg.state1[4]))
}
}
Instead of directly using a uint64 for state, WaitGroup sets aside 12 bytes in an array (state1 [12]byte). This might seem like more than you'd need, but there's a reason behind it.
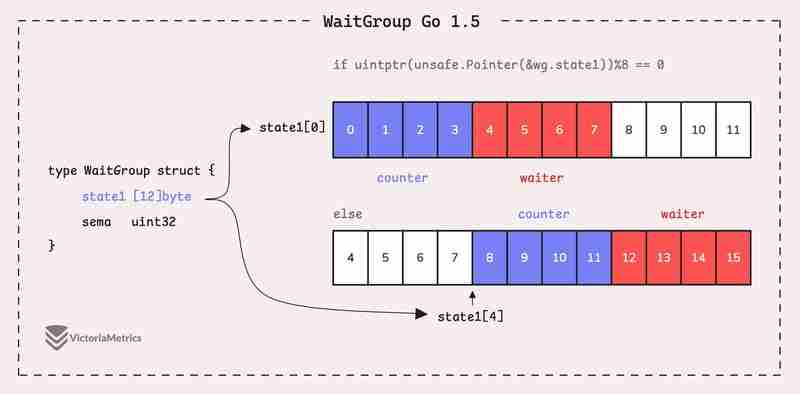
The purpose of using 12 bytes is to ensure there's enough room to find an 8-byte segment that's properly aligned.
The full post is available here: https://victoriametrics.com/blog/go-sync-waitgroup/
以上是Gosync.WaitGroup 和对齐问题的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 Golang vs. Python:性能和可伸缩性
Apr 19, 2025 am 12:18 AM
Golang vs. Python:性能和可伸缩性
Apr 19, 2025 am 12:18 AM
Golang在性能和可扩展性方面优于Python。1)Golang的编译型特性和高效并发模型使其在高并发场景下表现出色。2)Python作为解释型语言,执行速度较慢,但通过工具如Cython可优化性能。
 Golang和C:并发与原始速度
Apr 21, 2025 am 12:16 AM
Golang和C:并发与原始速度
Apr 21, 2025 am 12:16 AM
Golang在并发性上优于C ,而C 在原始速度上优于Golang。1)Golang通过goroutine和channel实现高效并发,适合处理大量并发任务。2)C 通过编译器优化和标准库,提供接近硬件的高性能,适合需要极致优化的应用。
 开始GO:初学者指南
Apr 26, 2025 am 12:21 AM
开始GO:初学者指南
Apr 26, 2025 am 12:21 AM
goisidealforbeginnersandsubableforforcloudnetworkservicesduetoitssimplicity,效率和concurrencyFeatures.1)installgromtheofficialwebsitealwebsiteandverifywith'.2)
 Golang vs.C:性能和速度比较
Apr 21, 2025 am 12:13 AM
Golang vs.C:性能和速度比较
Apr 21, 2025 am 12:13 AM
Golang适合快速开发和并发场景,C 适用于需要极致性能和低级控制的场景。1)Golang通过垃圾回收和并发机制提升性能,适合高并发Web服务开发。2)C 通过手动内存管理和编译器优化达到极致性能,适用于嵌入式系统开发。
 Golang vs. Python:主要差异和相似之处
Apr 17, 2025 am 12:15 AM
Golang vs. Python:主要差异和相似之处
Apr 17, 2025 am 12:15 AM
Golang和Python各有优势:Golang适合高性能和并发编程,Python适用于数据科学和Web开发。 Golang以其并发模型和高效性能着称,Python则以简洁语法和丰富库生态系统着称。
 Golang和C:性能的权衡
Apr 17, 2025 am 12:18 AM
Golang和C:性能的权衡
Apr 17, 2025 am 12:18 AM
Golang和C 在性能上的差异主要体现在内存管理、编译优化和运行时效率等方面。1)Golang的垃圾回收机制方便但可能影响性能,2)C 的手动内存管理和编译器优化在递归计算中表现更为高效。
 表演竞赛:Golang vs.C
Apr 16, 2025 am 12:07 AM
表演竞赛:Golang vs.C
Apr 16, 2025 am 12:07 AM
Golang和C 在性能竞赛中的表现各有优势:1)Golang适合高并发和快速开发,2)C 提供更高性能和细粒度控制。选择应基于项目需求和团队技术栈。
 Golang vs. Python:利弊
Apr 21, 2025 am 12:17 AM
Golang vs. Python:利弊
Apr 21, 2025 am 12:17 AM
Golangisidealforbuildingscalablesystemsduetoitsefficiencyandconcurrency,whilePythonexcelsinquickscriptinganddataanalysisduetoitssimplicityandvastecosystem.Golang'sdesignencouragesclean,readablecodeanditsgoroutinesenableefficientconcurrentoperations,t
