
当我们创建回归算法并想知道该模型的效率如何时,我们使用错误度量来获取代表机器学习模型错误的值。当我们想要测量数值(实数、整数)的预测模型的误差时,本文中的指标非常重要。
在本文中,我们将介绍回归算法的主要误差指标,在 Python 中手动执行计算,并在美元报价数据集上测量机器学习模型的误差。
这两个指标有点相似,我们有平均值和误差百分比的指标,以及平均和绝对误差百分比的指标,只是有区别,以便一组获得差异的实际值,另一组获得绝对值的差异。重要的是要记住,在这两个指标中,值越低,我们的预测就越好。
SE 指标是本文中最简单的指标,其公式为:
SE = εR — P
因此,它是真实值(模型的目标变量)与预测值之间的差值之和。该指标有一些缺点,例如不将值视为绝对值,这将导致错误值。
ME 指标是 SE 的“补充”,我们基本上有一个区别,即我们将在给定元素数量的情况下获得 SE 的平均值:
ME = ε(R-P)/N
与 SE 不同,我们只需将 SE 结果除以元素数量。这个指标和 SE 一样,取决于规模,也就是说,我们必须使用同一组数据,并且可以与不同的预测模型进行比较。

MAE 指标是 ME,但仅考虑绝对(非负)值。当我们计算实际值和预测值之间的差异时,我们可能会得到负结果,并且这种负差异会应用于之前的指标。在这个指标中,我们必须将差异转换为正值,然后根据元素数量取平均值。
MPE 指标是平均误差占每个差异之和的百分比。这里我们必须获取差异的百分比,将其相加,然后除以元素数量以获得平均值。因此,实际值和预测值之间的差值除以实际值,再乘以 100,我们将所有这些百分比相加,然后除以元素数量。该指标与比例 (%) 无关。
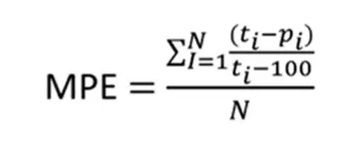
MAPAE 指标与之前的指标非常相似,但是预测 x 实际之间的差异是绝对的,也就是说,您用正值来计算它。因此,该指标是错误百分比的绝对差异。该指标也是与尺度无关的。

给出每个指标的解释,我们将根据美元汇率机器学习模型的预测,在 Python 中手动计算这两个指标。目前,大多数回归指标都存在于 Sklearn 包中的现成函数中,但是这里我们将手动计算它们,仅用于教学目的。

我们将仅使用随机森林和决策树算法来比较两个模型之间的结果。
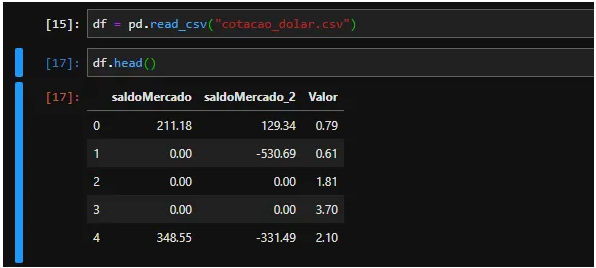
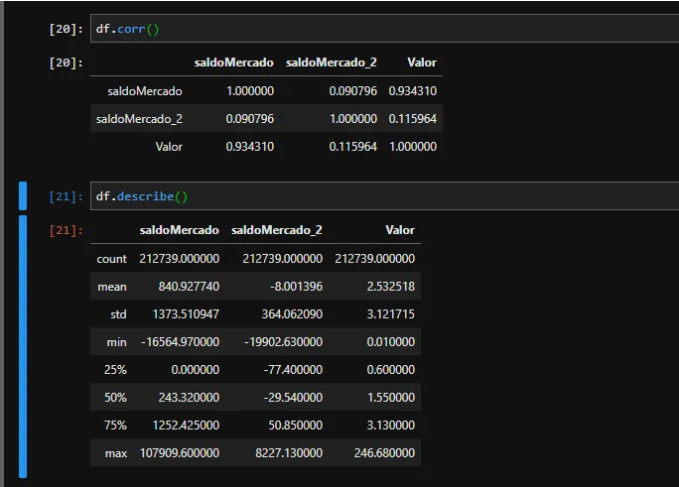
在我们的数据集中,我们有 SaldoMercado 和 saldoMercado_2 列,它们是影响 Value 列(我们的美元报价)的信息。正如我们所看到的,MercadoMercado 余额与报价的关系比 Merado_2 余额更密切。还可以观察到我们没有缺失值(无限或 Nan 值),并且balanceMercado_2 列有许多非绝对值。

我们通过定义预测变量和我们想要预测的变量来准备机器学习模型的值。我们使用train_test_split将数据随机分为30%用于测试,70%用于训练。
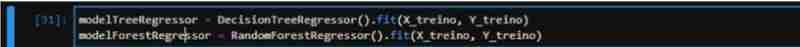

最后,我们初始化两种算法(RandomForest 和 DecisionTree),拟合数据并用测试数据测量两种算法的分数。我们获得了 TreeRegressor 83% 的分数和 ForestRegressor 90% 的分数,这在理论上表明 ForestRegressor 表现更好。
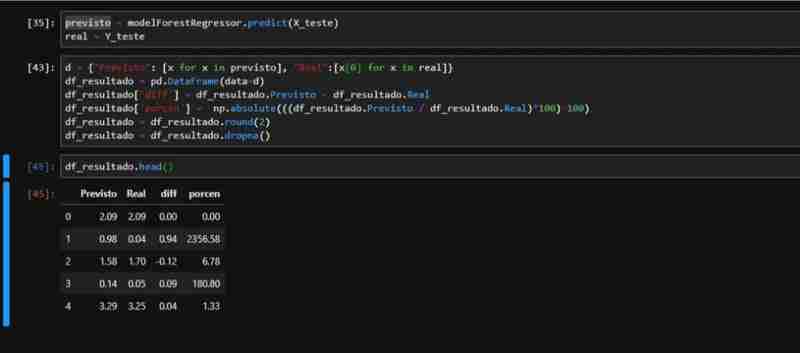
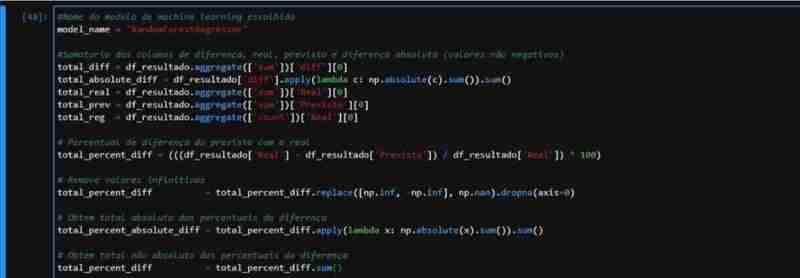
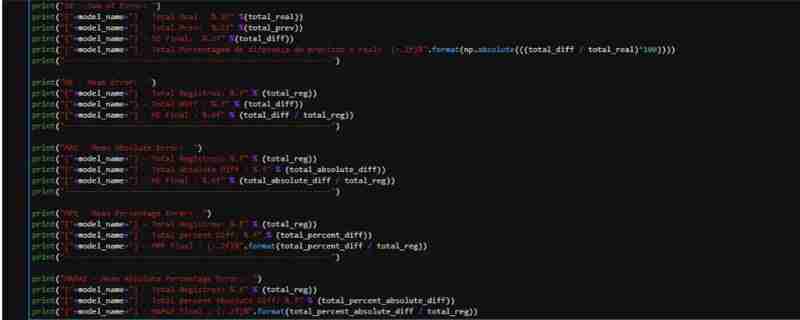
鉴于 ForestRegressor 的部分观察到的性能,我们创建了一个包含应用指标所需数据的数据集。我们对测试数据进行预测,并使用实际值和预测值创建一个 DataFrame,包括差异和百分比列。

我们可以观察到,相对于美元汇率的实际总额与我们模型预测的汇率:
我强调,这里我们出于教学目的手动执行计算。但是,建议使用 Sklearn 包中的指标函数,因为它具有更好的性能并且计算出错的可能性较低。
完整的代码可以在我的 GitHub 上找到:github.com/AirtonLira/artigo_metricasregressao
作者:Airton Lira Junior
LinkedIn:linkedin.com/in/airton-lira-junior-6b81a661/
以上是回归算法的指标的详细内容。更多信息请关注PHP中文网其他相关文章!






















