

PyPI 的 BigQuery 数据令人惊讶的事情

您可以从 Google BigQuery 数据集中获取 PyPI 包(或项目)的下载数量。您需要一个 Google 帐户和凭据,Google 每月提供 1 TiB 的免费配额。
每个月,我都会自动获取过去 30 天内 8,000 个最受欢迎的软件包的下载数量,并将其作为更易于访问的 JSON 和 CSV 文件在 Top PyPI Packages 中提供。这些数据被广泛用于学术界和工业界的研究。
但是,随着越来越多的软件包和版本上传到 PyPI,并且记录的下载量越来越多,计费数据量也会增加。
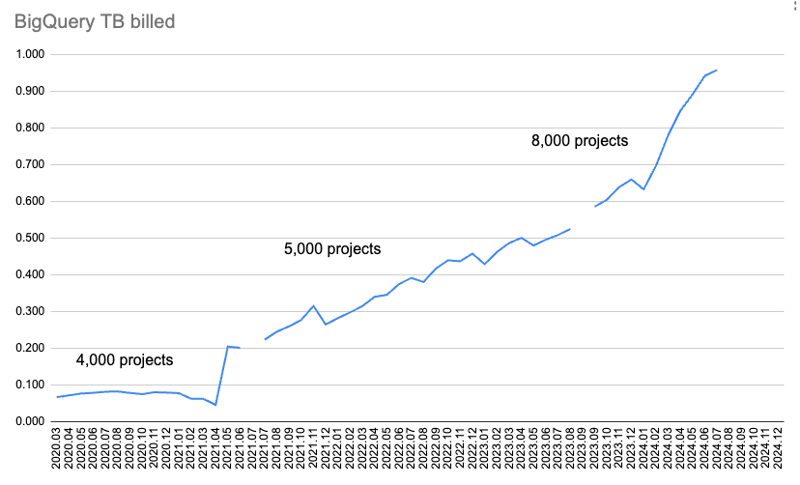
此图表显示每月计费的数据量。
一开始,我只收集了 4,000 个软件包的下载数据,并通过两个查询获取:超过 365 天和超过 30 天的下载。但随着时间的推移,它开始用完太多的配额来下载 365 天的数据。
所以我放弃了 365 天的数据,并将 30 天的数据从 4,000 个包裹增加到 5,000 个。后来我查了一下配额用了多少,从5000包增加到8000包。
但后来我超出了 BigQuery 2024 年 7 月获取数据的每月 1 TiB 配额。
为了获取丢失的数据并调查发生了什么,我开始了 Google Cloud 的 90 天、300 美元(277.46 欧元)免费试用?
这是我发现的!
发现:仅从 pip 获取下载数据比从所有安装程序获取下载数据的成本更高
我使用 pypinfo 客户端来帮助查询 BigQuery。默认情况下,它仅获取 pip 的下载。
仅点
此命令获取前 10 个软件包的一天下载数据,仅适用于 pip:
$ pypinfo --limit 10 --days 1 "" project Served from cache: False Data processed: 58.21 GiB Data billed: 58.21 GiB Estimated cost: <pre class="brush:php;toolbar:false">$ pypinfo --all --limit 10 --days 1 "" project Served from cache: False Data processed: 46.63 GiB Data billed: 46.63 GiB Estimated cost: <pre class="brush:php;toolbar:false">SELECT file.project as project, COUNT(*) as download_count, FROM `bigquery-public-data.pypi.file_downloads` WHERE timestamp BETWEEN TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -2 DAY) AND TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -1 DAY) AND details.installer.name = "pip" GROUP BY project ORDER BY download_count DESC LIMIT 10
结果:
| project | download count |
|---|---|
| boto3 | 37,251,744 |
| aiobotocore | 16,252,824 |
| urllib3 | 16,243,278 |
| botocore | 15,687,125 |
| requests | 13,271,314 |
| s3fs | 12,865,055 |
| s3transfer | 12,014,278 |
| fsspec | 11,982,305 |
| charset-normalizer | 11,684,740 |
| certifi | 11,639,584 |
| Total | 158,892,247 |
所有安装人员
添加 --all 标志可获取前 10 个软件包的一天下载数据,所有安装程序:
$ pypinfo --limit 10 --days 1 "" project Served from cache: False Data processed: 58.21 GiB Data billed: 58.21 GiB Estimated cost: <pre class="brush:php;toolbar:false">$ pypinfo --all --limit 10 --days 1 "" project Served from cache: False Data processed: 46.63 GiB Data billed: 46.63 GiB Estimated cost: <pre class="brush:php;toolbar:false">SELECT file.project as project, COUNT(*) as download_count, FROM `bigquery-public-data.pypi.file_downloads` WHERE timestamp BETWEEN TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -2 DAY) AND TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -1 DAY) AND details.installer.name = "pip" GROUP BY project ORDER BY download_count DESC LIMIT 10
| project | download count |
|---|---|
| boto3 | 39,495,624 |
| botocore | 17,281,187 |
| urllib3 | 17,225,121 |
| aiobotocore | 16,430,826 |
| requests | 14,287,965 |
| s3fs | 12,958,516 |
| charset-normalizer | 12,781,405 |
| certifi | 12,647,098 |
| setuptools | 12,608,120 |
| idna | 12,510,335 |
| Total | 168,226,197 |
因此我们可以看到,默认的仅 pip 需要额外花费 25% 的数据处理和数据计费,并额外花费 25% 的美元费用。
毫不奇怪,所有安装程序的实际下载次数都更高。排名发生了一些变化,但我预计我们在前数千个结果中仍然会得到或多或少相同的软件包。
查询
它向 BigQuery 发送这样的查询,仅获取 pip:
SELECT file.project as project, COUNT(*) as download_count, FROM `bigquery-public-data.pypi.file_downloads` WHERE timestamp BETWEEN TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -2 DAY) AND TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -1 DAY) GROUP BY project ORDER BY download_count DESC LIMIT 10
对于所有安装者:
$ pypinfo --all --limit 100 --days 1 "" installer Served from cache: False Data processed: 29.49 GiB Data billed: 29.49 GiB Estimated cost: <pre class="brush:php;toolbar:false">SELECT file.project as project, COUNT(*) as download_count, FROM `bigquery-public-data.pypi.file_downloads` WHERE timestamp BETWEEN TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -2 DAY) AND TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -1 DAY) GROUP BY project ORDER BY download_count DESC LIMIT 8000
这些查询是相同的,只是默认有一个额外的 ANDdetails.installer.name = "pip" 条件。做额外的过滤工作会花费更多,这似乎是合理的。
安装人员
让我们看看安装程序:
| installer name | download count |
|---|---|
| pip | 1,121,198,711 |
| uv | 117,194,833 |
| requests | 29,828,272 |
| poetry | 23,009,454 |
| None | 8,916,745 |
| bandersnatch | 6,171,555 |
| setuptools | 1,362,797 |
| Bazel | 1,280,271 |
| Browser | 1,096,328 |
| Nexus | 593,230 |
| Homebrew | 510,247 |
| Artifactory | 69,063 |
| pdm | 62,904 |
| OS | 13,108 |
| devpi | 9,530 |
| conda | 2,272 |
| pex | 194 |
| Total | 1,311,319,514 |
pip 仍然是迄今为止最受欢迎的,不出所料,uv 也位居榜首,约占 pip 下载量的 10%。
其他的大约是紫外线的25%或更少。其中很多是我们之前想要排除的镜像服务。
我认为,考虑到 uv 的重要性,以及我期望它将继续占据更大份额,再加上仅通过 pip 进行过滤的额外成本,意味着我们应该转而为所有下载者获取数据。另外,其他的并没有占那么多份额。
发现:包裹数量不影响成本
这是最大的惊喜。早些时候,我一直在增加或减少数量,以尽量保持在配额以内。但事实证明,查询多少个包裹并没有什么区别!
我仅获取了一天的数据以及不同软件包限制的所有安装程序:1000、2000、3000、4000、5000、6000、7000、8000。示例查询:
$ pypinfo --limit 10 --days 1 "" project Served from cache: False Data processed: 58.21 GiB Data billed: 58.21 GiB Estimated cost: <pre class="brush:php;toolbar:false">$ pypinfo --all --limit 10 --days 1 "" project Served from cache: False Data processed: 46.63 GiB Data billed: 46.63 GiB Estimated cost: <pre class="brush:php;toolbar:false">SELECT file.project as project, COUNT(*) as download_count, FROM `bigquery-public-data.pypi.file_downloads` WHERE timestamp BETWEEN TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -2 DAY) AND TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -1 DAY) AND details.installer.name = "pip" GROUP BY project ORDER BY download_count DESC LIMIT 10
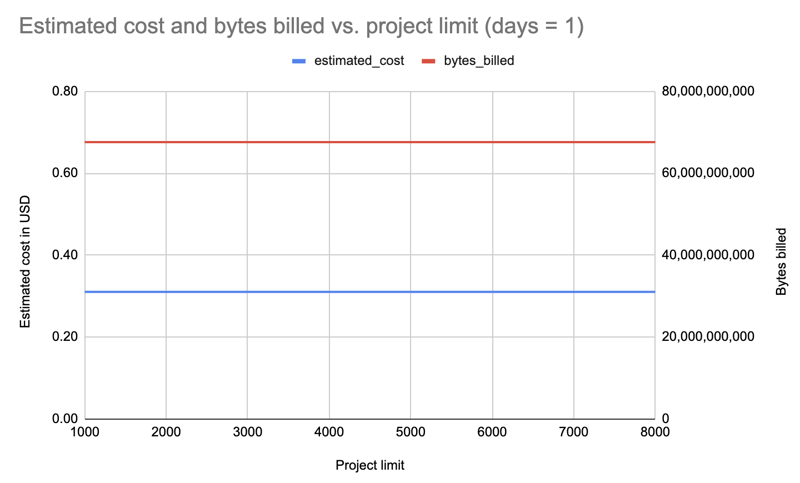
结果:有趣的是,所有限额(1000-8000)的成本都是相同的:0.31 美元。
重复一天,但仅过滤点:
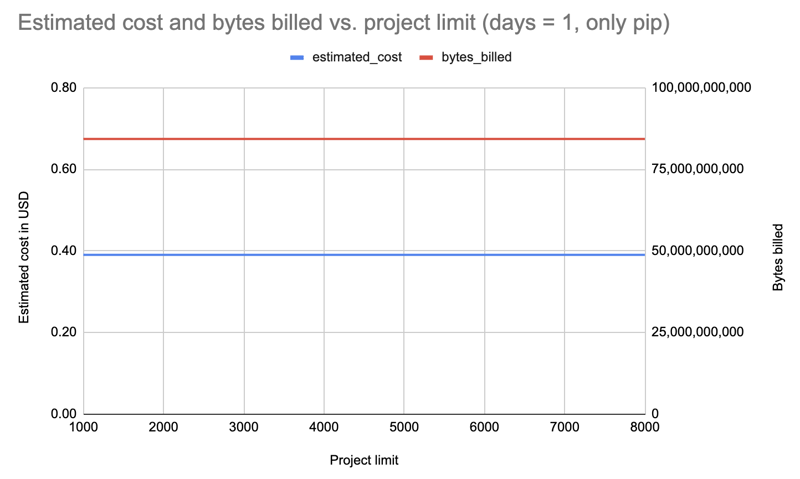
结果: 成本增加至 0.39 美元,但所有限制均相同。
让我们对所有安装程序重复一遍,但持续 30 天,这次查询的限制是递减的,以防我们只为增量更改付费:8000、7000、6000、5000、4000、3000、2000、1000:
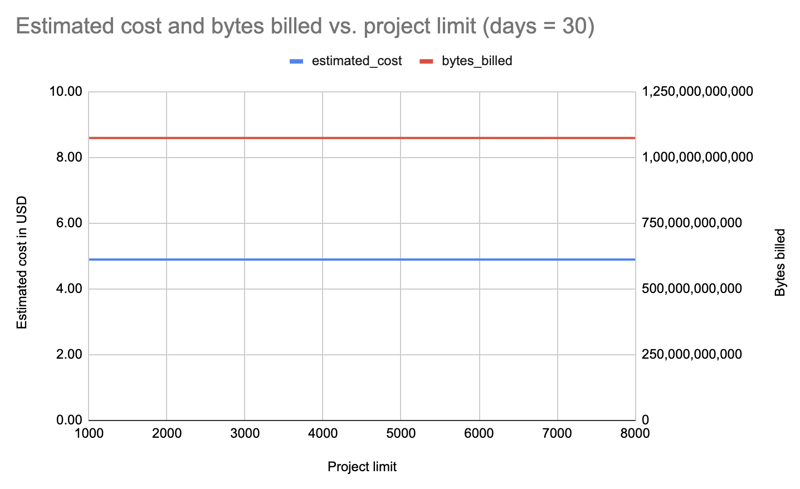
结果:同样,无论套餐限制如何,费用都是相同的:每次查询 4.89 美元。
那么,让我们重复一遍,将限制增加十次方,直到 1,000,000!最后一个获取 PyPI 上所有 531,022 个包的数据:
| limit | projects count | estimated cost | bytes billed | bytes processed |
|---|---|---|---|---|
| 1 | 1 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 10 | 10 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 100 | 100 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 1000 | 1,000 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 8000 | 8,000 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 10000 | 10,000 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 100000 | 100,000 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 1000000 | 531,022 | 0.20 | 43,447,746,560 | 43,447,720,943 |
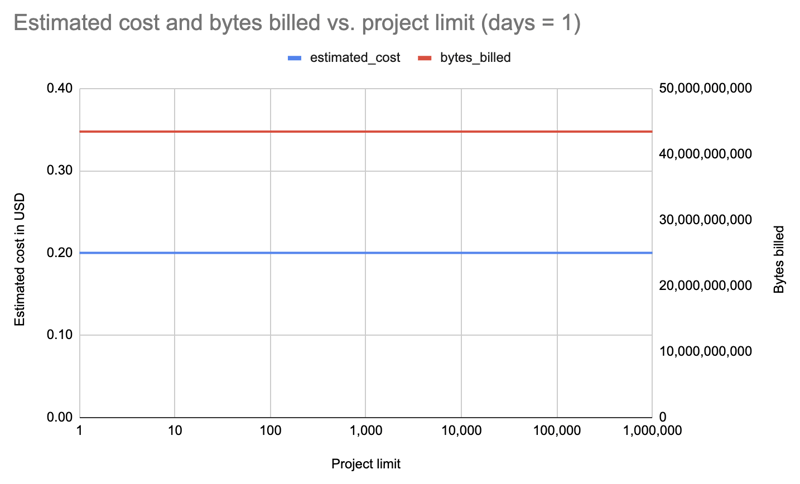
结果:同样,无论是 1 包还是 531,022 包,成本都是一样的!
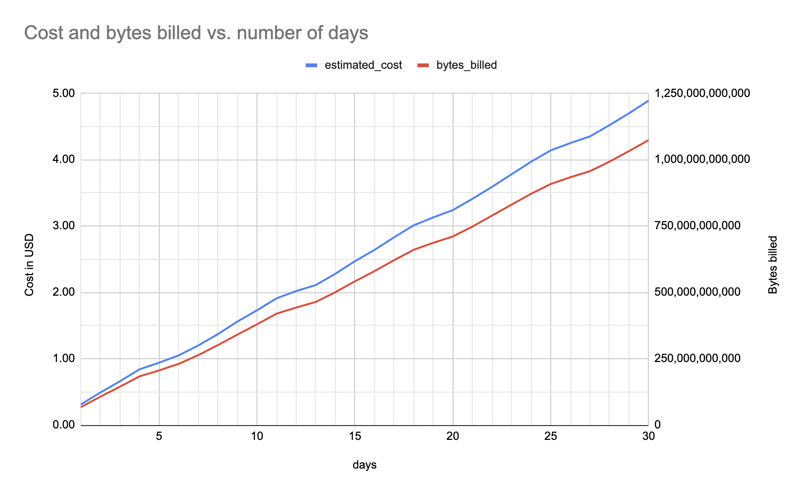
发现:天数影响成本
不足为奇。我之前就注意到 365 天占用了太多配额,我可以继续 30 天。
以下是 1 到 30 天内的估计成本和字节数(针对一个软件包、所有安装程序)(f"pypinfo --all --json --indent 0 --days {days} --limit 1 '' 项目”),呈现出大致线性的增长:
结论
无论我获取多少个包的数据,我都可以获取所有包并将其提供给每个人,具体取决于数据文件的大小。仍然提供包含 8,000 个左右包的较小文件是有意义的:通常您只需要一个较大但易于管理的数字。
仅过滤来自 pip 的下载会花费更多,因此我已转为获取所有安装程序的数据。
天数会影响成本,因此我将来需要减少天数以保持在配额之内。例如,在某些时候我可能需要从 30 天切换到 25 天,然后从 25 天切换到 20 天。
更多调查细节、脚本和数据文件可以在
找到
hugovk/top-pypi-packages#36.
如果您知道任何降低成本的技巧,请告诉我!
标题照片:“平衡石,巨石阵,新南威尔士州格伦因尼斯附近”,由澳大利亚皇家历史学会拍摄,没有已知的版权限制。
以上是PyPI 的 BigQuery 数据令人惊讶的事情的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 Python与C:学习曲线和易用性
Apr 19, 2025 am 12:20 AM
Python与C:学习曲线和易用性
Apr 19, 2025 am 12:20 AM
Python更易学且易用,C 则更强大但复杂。1.Python语法简洁,适合初学者,动态类型和自动内存管理使其易用,但可能导致运行时错误。2.C 提供低级控制和高级特性,适合高性能应用,但学习门槛高,需手动管理内存和类型安全。
 Python和时间:充分利用您的学习时间
Apr 14, 2025 am 12:02 AM
Python和时间:充分利用您的学习时间
Apr 14, 2025 am 12:02 AM
要在有限的时间内最大化学习Python的效率,可以使用Python的datetime、time和schedule模块。1.datetime模块用于记录和规划学习时间。2.time模块帮助设置学习和休息时间。3.schedule模块自动化安排每周学习任务。
 Python vs.C:探索性能和效率
Apr 18, 2025 am 12:20 AM
Python vs.C:探索性能和效率
Apr 18, 2025 am 12:20 AM
Python在开发效率上优于C ,但C 在执行性能上更高。1.Python的简洁语法和丰富库提高开发效率。2.C 的编译型特性和硬件控制提升执行性能。选择时需根据项目需求权衡开发速度与执行效率。
 Python vs. C:了解关键差异
Apr 21, 2025 am 12:18 AM
Python vs. C:了解关键差异
Apr 21, 2025 am 12:18 AM
Python和C 各有优势,选择应基于项目需求。1)Python适合快速开发和数据处理,因其简洁语法和动态类型。2)C 适用于高性能和系统编程,因其静态类型和手动内存管理。
 学习Python:2小时的每日学习是否足够?
Apr 18, 2025 am 12:22 AM
学习Python:2小时的每日学习是否足够?
Apr 18, 2025 am 12:22 AM
每天学习Python两个小时是否足够?这取决于你的目标和学习方法。1)制定清晰的学习计划,2)选择合适的学习资源和方法,3)动手实践和复习巩固,可以在这段时间内逐步掌握Python的基本知识和高级功能。
 Python标准库的哪一部分是:列表或数组?
Apr 27, 2025 am 12:03 AM
Python标准库的哪一部分是:列表或数组?
Apr 27, 2025 am 12:03 AM
pythonlistsarepartofthestAndArdLibrary,herilearRaysarenot.listsarebuilt-In,多功能,和Rused ForStoringCollections,而EasaraySaraySaraySaraysaraySaraySaraysaraySaraysarrayModuleandleandleandlesscommonlyusedDduetolimitedFunctionalityFunctionalityFunctionality。
 Python:自动化,脚本和任务管理
Apr 16, 2025 am 12:14 AM
Python:自动化,脚本和任务管理
Apr 16, 2025 am 12:14 AM
Python在自动化、脚本编写和任务管理中表现出色。1)自动化:通过标准库如os、shutil实现文件备份。2)脚本编写:使用psutil库监控系统资源。3)任务管理:利用schedule库调度任务。Python的易用性和丰富库支持使其在这些领域中成为首选工具。
 Web开发的Python:关键应用程序
Apr 18, 2025 am 12:20 AM
Web开发的Python:关键应用程序
Apr 18, 2025 am 12:20 AM
Python在Web开发中的关键应用包括使用Django和Flask框架、API开发、数据分析与可视化、机器学习与AI、以及性能优化。1.Django和Flask框架:Django适合快速开发复杂应用,Flask适用于小型或高度自定义项目。2.API开发:使用Flask或DjangoRESTFramework构建RESTfulAPI。3.数据分析与可视化:利用Python处理数据并通过Web界面展示。4.机器学习与AI:Python用于构建智能Web应用。5.性能优化:通过异步编程、缓存和代码优
