

IRIS-RAG-Gen:由 IRIS 矢量搜索提供支持的个性化 ChatGPT RAG 应用程序

社区大家好,
在本文中,我将介绍我的应用程序 iris-RAG-Gen 。
Iris-RAG-Gen 是一款生成式 AI 检索增强生成 (RAG) 应用程序,它利用 IRIS 矢量搜索的功能,在 Streamlit Web 框架、LangChain 和 OpenAI 的帮助下个性化 ChatGPT。该应用程序使用 IRIS 作为矢量存储。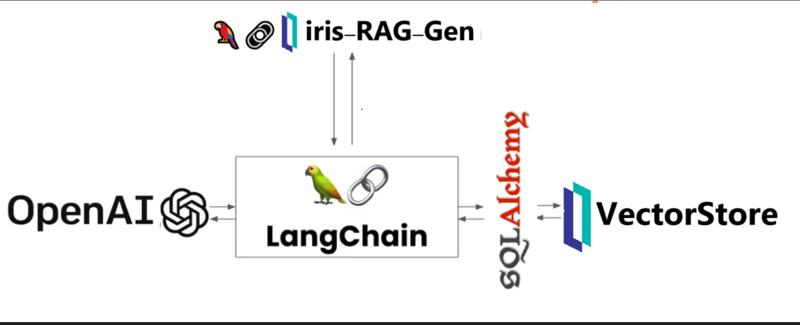
应用功能
- 将文档(PDF 或 TXT)提取到 IRIS
- 与选定的摄取文档聊天
- 删除摄取的文档
- OpenAI ChatGPT
将文档(PDF 或 TXT)提取到 IRIS
按照以下步骤提取文档:
- 输入 OpenAI 密钥
- 选择文档(PDF 或 TXT)
- 输入文档说明
- 单击“摄取文档”按钮
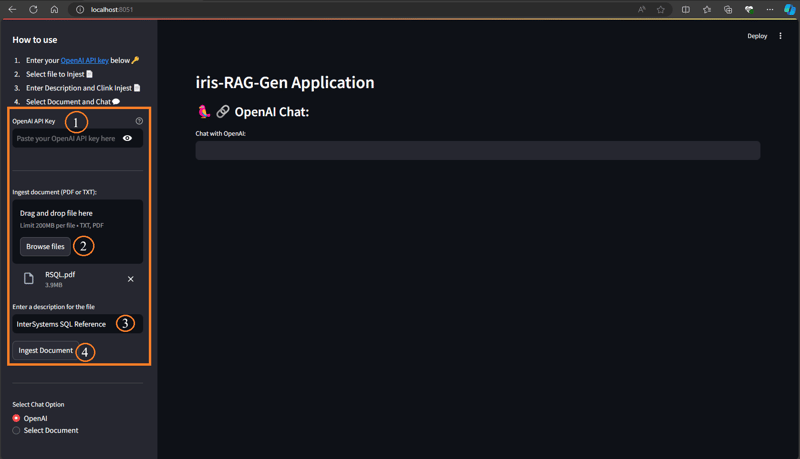
摄取文档功能将文档详细信息插入到 rag_documents 表中,并创建“rag_document id”(rag_documents 的 ID)表来保存矢量数据。

下面的 Python 代码会将所选文档保存到向量中:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFLoader, TextLoader
from langchain_iris import IRISVector
from langchain_openai import OpenAIEmbeddings
from sqlalchemy import create_engine,text
<span>class RagOpr:</span>
#Ingest document. Parametres contains file path, description and file type
<span>def ingestDoc(self,filePath,fileDesc,fileType):</span>
embeddings = OpenAIEmbeddings()
#Load the document based on the file type
if fileType == "text/plain":
loader = TextLoader(filePath)
elif fileType == "application/pdf":
loader = PyPDFLoader(filePath)
#load data into documents
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=400, chunk_overlap=0)
#Split text into chunks
texts = text_splitter.split_documents(documents)
#Get collection Name from rag_doucments table.
COLLECTION_NAME = self.get_collection_name(fileDesc,fileType)
# function to create collection_name table and store vector data in it.
db = IRISVector.from_documents(
embedding=embeddings,
documents=texts,
collection_name = COLLECTION_NAME,
connection_string=self.CONNECTION_STRING,
)
#Get collection name
<span>def get_collection_name(self,fileDesc,fileType):</span>
# check if rag_documents table exists, if not then create it
with self.engine.connect() as conn:
with conn.begin():
sql = text("""
SELECT *
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'SQLUser'
AND TABLE_NAME = 'rag_documents';
""")
result = []
try:
result = conn.execute(sql).fetchall()
except Exception as err:
print("An exception occurred:", err)
return ''
#if table is not created, then create rag_documents table first
if len(result) == 0:
sql = text("""
CREATE TABLE rag_documents (
description VARCHAR(255),
docType VARCHAR(50) )
""")
try:
result = conn.execute(sql)
except Exception as err:
print("An exception occurred:", err)
return ''
#Insert description value
with self.engine.connect() as conn:
with conn.begin():
sql = text("""
INSERT INTO rag_documents
(description,docType)
VALUES (:desc,:ftype)
""")
try:
result = conn.execute(sql, {'desc':fileDesc,'ftype':fileType})
except Exception as err:
print("An exception occurred:", err)
return ''
#select ID of last inserted record
sql = text("""
SELECT LAST_IDENTITY()
""")
try:
result = conn.execute(sql).fetchall()
except Exception as err:
print("An exception occurred:", err)
return ''
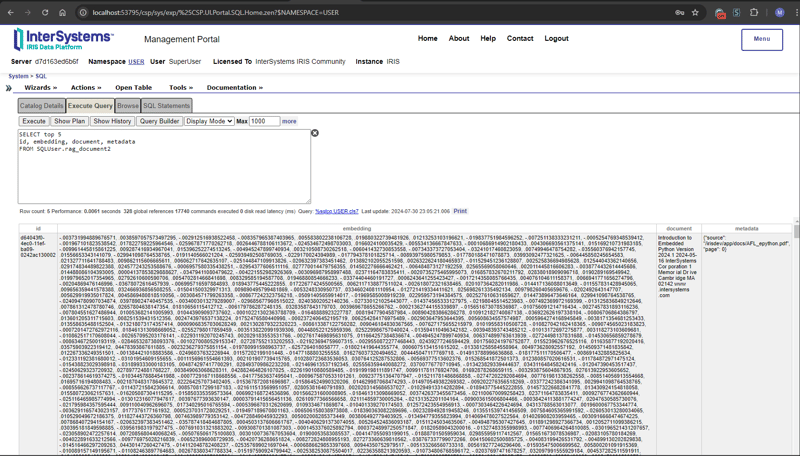
return "rag_document"+str(result[0][0])在管理门户中输入以下 SQL 命令来检索矢量数据
SELECT top 5 id, embedding, document, metadata FROM SQLUser.rag_document2
与选定的摄取文档聊天
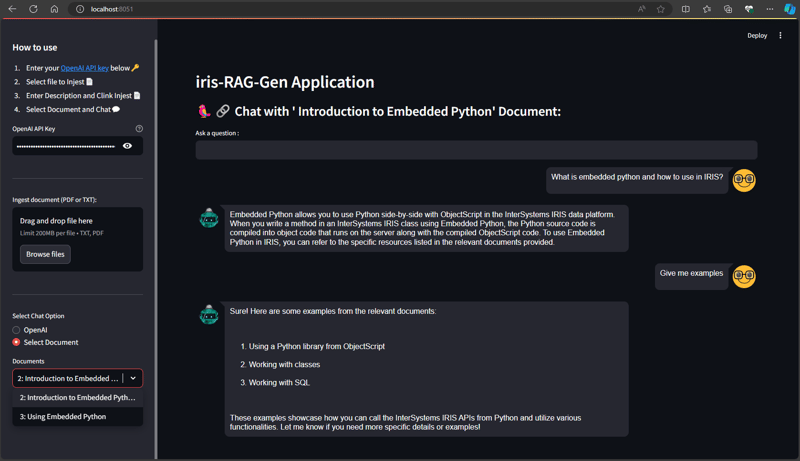
从选择聊天选项部分选择文档并输入问题。 应用程序将读取矢量数据并返回相关答案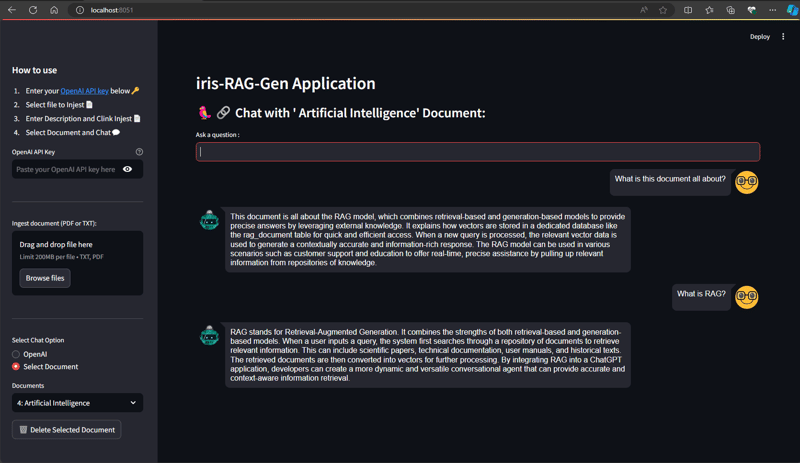
下面的 Python 代码会将所选文档保存到向量中:
from langchain_iris import IRISVector
from langchain_openai import OpenAIEmbeddings,ChatOpenAI
from langchain.chains import ConversationChain
from langchain.chains.conversation.memory import ConversationSummaryMemory
from langchain.chat_models import ChatOpenAI
<span>class RagOpr:</span>
<span>def ragSearch(self,prompt,id):</span>
#Concat document id with rag_doucment to get the collection name
COLLECTION_NAME = "rag_document"+str(id)
embeddings = OpenAIEmbeddings()
#Get vector store reference
db2 = IRISVector (
embedding_function=embeddings,
collection_name=COLLECTION_NAME,
connection_string=self.CONNECTION_STRING,
)
#Similarity search
docs_with_score = db2.similarity_search_with_score(prompt)
#Prepair the retrieved documents to pass to LLM
relevant_docs = ["".join(str(doc.page_content)) + " " for doc, _ in docs_with_score]
#init LLM
llm = ChatOpenAI(
temperature=0,
model_name="gpt-3.5-turbo"
)
#manage and handle LangChain multi-turn conversations
conversation_sum = ConversationChain(
llm=llm,
memory= ConversationSummaryMemory(llm=llm),
verbose=False
)
#Create prompt
template = f"""
Prompt: <span>{prompt}
Relevant Docuemnts: {relevant_docs}
"""</span>
#Return the answer
resp = conversation_sum(template)
return resp['response']
更多详情,请访问iris-RAG-Gen打开交换申请页面。
谢谢
以上是IRIS-RAG-Gen:由 IRIS 矢量搜索提供支持的个性化 ChatGPT RAG 应用程序的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 如何解决Linux终端中查看Python版本时遇到的权限问题?
Apr 01, 2025 pm 05:09 PM
如何解决Linux终端中查看Python版本时遇到的权限问题?
Apr 01, 2025 pm 05:09 PM
Linux终端中查看Python版本时遇到权限问题的解决方法当你在Linux终端中尝试查看Python的版本时,输入python...
 如何在使用 Fiddler Everywhere 进行中间人读取时避免被浏览器检测到?
Apr 02, 2025 am 07:15 AM
如何在使用 Fiddler Everywhere 进行中间人读取时避免被浏览器检测到?
Apr 02, 2025 am 07:15 AM
使用FiddlerEverywhere进行中间人读取时如何避免被检测到当你使用FiddlerEverywhere...
 在Python中如何高效地将一个DataFrame的整列复制到另一个结构不同的DataFrame中?
Apr 01, 2025 pm 11:15 PM
在Python中如何高效地将一个DataFrame的整列复制到另一个结构不同的DataFrame中?
Apr 01, 2025 pm 11:15 PM
在使用Python的pandas库时,如何在两个结构不同的DataFrame之间进行整列复制是一个常见的问题。假设我们有两个Dat...
 如何在10小时内通过项目和问题驱动的方式教计算机小白编程基础?
Apr 02, 2025 am 07:18 AM
如何在10小时内通过项目和问题驱动的方式教计算机小白编程基础?
Apr 02, 2025 am 07:18 AM
如何在10小时内教计算机小白编程基础?如果你只有10个小时来教计算机小白一些编程知识,你会选择教些什么�...
 Uvicorn是如何在没有serve_forever()的情况下持续监听HTTP请求的?
Apr 01, 2025 pm 10:51 PM
Uvicorn是如何在没有serve_forever()的情况下持续监听HTTP请求的?
Apr 01, 2025 pm 10:51 PM
Uvicorn是如何持续监听HTTP请求的?Uvicorn是一个基于ASGI的轻量级Web服务器,其核心功能之一便是监听HTTP请求并进�...


 如何绕过Investing.com的反爬虫机制获取新闻数据?
Apr 02, 2025 am 07:03 AM
如何绕过Investing.com的反爬虫机制获取新闻数据?
Apr 02, 2025 am 07:03 AM
攻克Investing.com的反爬虫策略许多人尝试爬取Investing.com(https://cn.investing.com/news/latest-news)的新闻数据时,常常�...
