

使用 vev、litellm 和 Agenta 构建 AI 代码审查助手

本教程演示使用 LLMOps 最佳实践构建可用于生产的 AI 拉取请求审核器。 最终应用程序可在此处访问,接受公共 PR URL 并返回人工智能生成的评论。
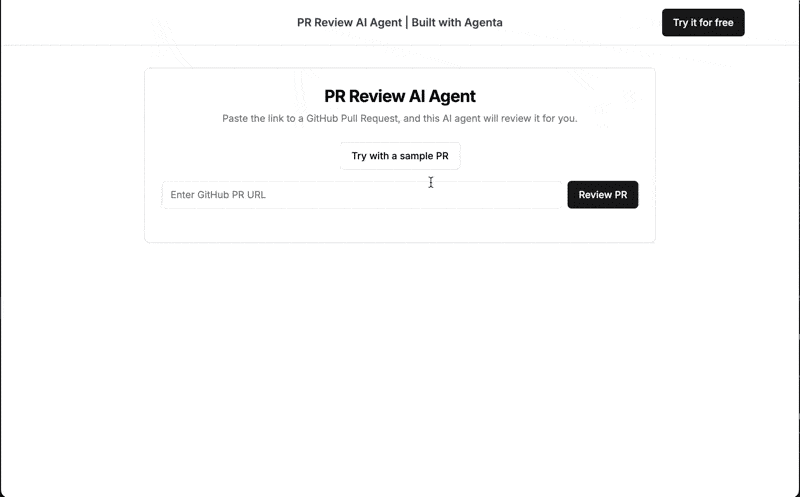
应用概述
本教程涵盖:
- 代码开发:从 GitHub 检索 PR 差异并利用 LiteLLM 进行 LLM 交互。
- 可观察性: 实现 Agenta 以进行应用程序监控和调试。
- 提示工程:使用 Agenta 的游乐场迭代提示和模型选择。
- 法学硕士评估:聘请法学硕士作为法官进行及时和模型评估。
- 部署:将应用程序部署为 API 并使用 v0.dev 创建简单的 UI。
核心逻辑
AI 助手的工作流程很简单:给定 PR URL,它从 GitHub 检索差异并将其提交给 LLM 进行审核。
GitHub 差异可通过以下方式访问:
<code>https://patch-diff.githubusercontent.com/raw/{owner}/{repo}/pull/{pr_number}.diff</code>这个 Python 函数获取差异:
def get_pr_diff(pr_url):
# ... (Code remains the same)
return response.textLiteLLM 促进了 LLM 交互,在不同提供商之间提供一致的界面。
prompt_system = """
You are an expert Python developer performing a file-by-file review of a pull request. You have access to the full diff of the file to understand the overall context and structure. However, focus on reviewing only the specific hunk provided.
"""
prompt_user = """
Here is the diff for the file:
{diff}
Please provide a critique of the changes made in this file.
"""
def generate_critique(pr_url: str):
diff = get_pr_diff(pr_url)
response = litellm.completion(
model=config.model,
messages=[
{"content": config.system_prompt, "role": "system"},
{"content": config.user_prompt.format(diff=diff), "role": "user"},
],
)
return response.choices[0].message.content使用 Agenta 实现可观察性
Agenta 增强了可观察性,跟踪输入、输出和数据流,以便于调试。
初始化 Agenta 并配置 LiteLLM 回调:
import agenta as ag ag.init() litellm.callbacks = [ag.callbacks.litellm_handler()]
带有 Agenta 装饰器的仪器函数:
@ag.instrument()
def generate_critique(pr_url: str):
# ... (Code remains the same)
return response.choices[0].message.content设置AGENTA_API_KEY环境变量(从Agenta获得)和可选的AGENTA_HOST用于自托管。

创建法学硕士游乐场
Agenta 的自定义工作流程功能为迭代开发提供了类似 IDE 的游乐场。 以下代码片段演示了与 Agenta 的配置和集成:
from pydantic import BaseModel, Field
from typing import Annotated
import agenta as ag
import litellm
from agenta.sdk.assets import supported_llm_models
# ... (previous code)
class Config(BaseModel):
system_prompt: str = prompt_system
user_prompt: str = prompt_user
model: Annotated[str, ag.MultipleChoice(choices=supported_llm_models)] = Field(default="gpt-3.5-turbo")
@ag.route("/", config_schema=Config)
@ag.instrument()
def generate_critique(pr_url:str):
diff = get_pr_diff(pr_url)
config = ag.ConfigManager.get_from_route(schema=Config)
response = litellm.completion(
model=config.model,
messages=[
{"content": config.system_prompt, "role": "system"},
{"content": config.user_prompt.format(diff=diff), "role": "user"},
],
)
return response.choices[0].message.content使用 Agenta 进行服务和评估
- 运行
agenta init并指定应用程序名称和 API 密钥。 - 运行
agenta variant serve app.py。
这使得应用程序可以通过 Agenta 的游乐场进行访问以进行端到端测试。 LLM-as-a-judge用于评估。 评估者提示是:
<code>You are an evaluator grading the quality of a PR review. CRITERIA: ... (criteria remain the same) ANSWER ONLY THE SCORE. DO NOT USE MARKDOWN. DO NOT PROVIDE ANYTHING OTHER THAN THE NUMBER</code>
评估器的用户提示:
<code>https://patch-diff.githubusercontent.com/raw/{owner}/{repo}/pull/{pr_number}.diff</code>
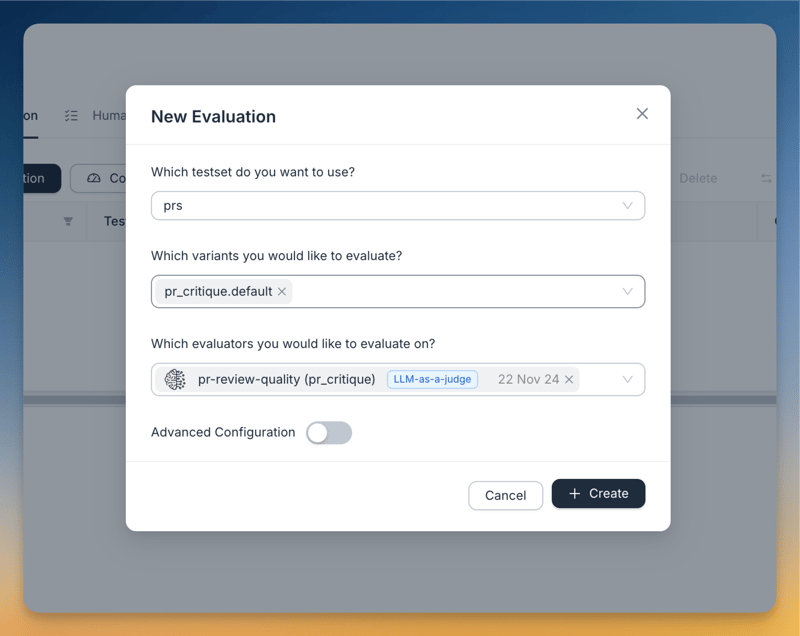
部署和前端
部署是通过 Agenta 的 UI 完成的:
- 导航到概述页面。
- 单击所选变体旁边的三个点。
- 选择“部署到生产”。

v0.dev 前端用于快速 UI 创建。
后续步骤和结论
未来的改进包括及时细化、合并完整的代码上下文以及处理大的差异。 本教程成功演示了使用 Agenta 和 LiteLLM 构建、评估和部署生产就绪的 AI 拉取请求审阅器。

以上是使用 vev、litellm 和 Agenta 构建 AI 代码审查助手的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 Python与C:学习曲线和易用性
Apr 19, 2025 am 12:20 AM
Python与C:学习曲线和易用性
Apr 19, 2025 am 12:20 AM
Python更易学且易用,C 则更强大但复杂。1.Python语法简洁,适合初学者,动态类型和自动内存管理使其易用,但可能导致运行时错误。2.C 提供低级控制和高级特性,适合高性能应用,但学习门槛高,需手动管理内存和类型安全。
 Python和时间:充分利用您的学习时间
Apr 14, 2025 am 12:02 AM
Python和时间:充分利用您的学习时间
Apr 14, 2025 am 12:02 AM
要在有限的时间内最大化学习Python的效率,可以使用Python的datetime、time和schedule模块。1.datetime模块用于记录和规划学习时间。2.time模块帮助设置学习和休息时间。3.schedule模块自动化安排每周学习任务。
 Python vs.C:探索性能和效率
Apr 18, 2025 am 12:20 AM
Python vs.C:探索性能和效率
Apr 18, 2025 am 12:20 AM
Python在开发效率上优于C ,但C 在执行性能上更高。1.Python的简洁语法和丰富库提高开发效率。2.C 的编译型特性和硬件控制提升执行性能。选择时需根据项目需求权衡开发速度与执行效率。
 学习Python:2小时的每日学习是否足够?
Apr 18, 2025 am 12:22 AM
学习Python:2小时的每日学习是否足够?
Apr 18, 2025 am 12:22 AM
每天学习Python两个小时是否足够?这取决于你的目标和学习方法。1)制定清晰的学习计划,2)选择合适的学习资源和方法,3)动手实践和复习巩固,可以在这段时间内逐步掌握Python的基本知识和高级功能。
 Python标准库的哪一部分是:列表或数组?
Apr 27, 2025 am 12:03 AM
Python标准库的哪一部分是:列表或数组?
Apr 27, 2025 am 12:03 AM
pythonlistsarepartofthestAndArdLibrary,herilearRaysarenot.listsarebuilt-In,多功能,和Rused ForStoringCollections,而EasaraySaraySaraySaraysaraySaraySaraysaraySaraysarrayModuleandleandleandlesscommonlyusedDduetolimitedFunctionalityFunctionalityFunctionality。
 Python vs. C:了解关键差异
Apr 21, 2025 am 12:18 AM
Python vs. C:了解关键差异
Apr 21, 2025 am 12:18 AM
Python和C 各有优势,选择应基于项目需求。1)Python适合快速开发和数据处理,因其简洁语法和动态类型。2)C 适用于高性能和系统编程,因其静态类型和手动内存管理。
 Python:自动化,脚本和任务管理
Apr 16, 2025 am 12:14 AM
Python:自动化,脚本和任务管理
Apr 16, 2025 am 12:14 AM
Python在自动化、脚本编写和任务管理中表现出色。1)自动化:通过标准库如os、shutil实现文件备份。2)脚本编写:使用psutil库监控系统资源。3)任务管理:利用schedule库调度任务。Python的易用性和丰富库支持使其在这些领域中成为首选工具。
 Web开发的Python:关键应用程序
Apr 18, 2025 am 12:20 AM
Web开发的Python:关键应用程序
Apr 18, 2025 am 12:20 AM
Python在Web开发中的关键应用包括使用Django和Flask框架、API开发、数据分析与可视化、机器学习与AI、以及性能优化。1.Django和Flask框架:Django适合快速开发复杂应用,Flask适用于小型或高度自定义项目。2.API开发:使用Flask或DjangoRESTFramework构建RESTfulAPI。3.数据分析与可视化:利用Python处理数据并通过Web界面展示。4.机器学习与AI:Python用于构建智能Web应用。5.性能优化:通过异步编程、缓存和代码优
