>本文探讨了AI中检索型发电(RAG)的承诺和现实。 我们将研究抹布的功能,潜在的优势以及实施过程中遇到的现实挑战,以及开发的解决方案和剩余的问题。这提供了对抹布的能力及其在AI中不断发展的作用的全面理解。
>
>传统的生成AI通常遭受依靠过时的信息和“幻觉”事实的困扰。 RAG通过为AI提供实时数据访问,提高准确性和相关性来解决这一问题。但是,这不是通用的解决方案,需要基于特定应用程序进行适应。>

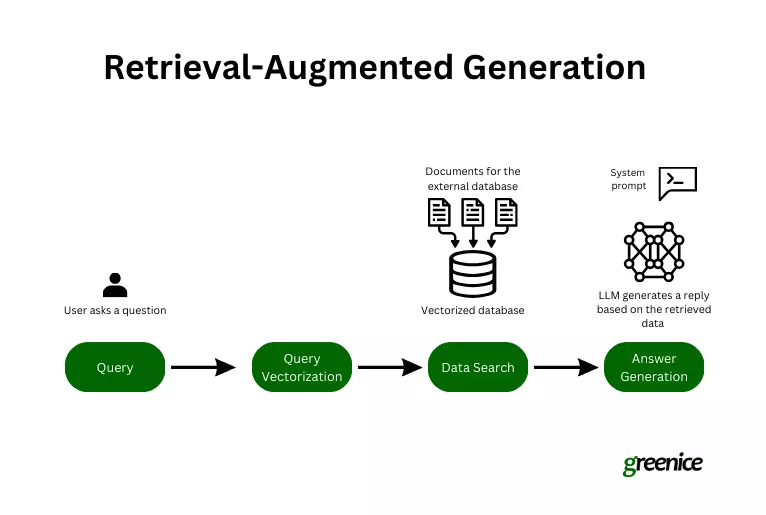
>抹布的工作方式:
通过在响应生成过程中纳入外部,当前信息, RAG通过合并当前信息来增强生成模型。 该过程涉及:
查询启动:- >用户提出问题。>
编码检索:- 查询转换为文本嵌入(数字表示)。
>相关的数据检索:>
>- 答案生成:抹布系统将AI的知识与检索到的数据相结合以创建上下文相关的响应。>
-
图像源
抹布开发:
构建抹布系统涉及:
>>数据集合:
>收集相关的外部数据(教科书,手册等)。
数据块和格式化:
将大型数据集分解为较小的,易于管理的零件。-
>数据嵌入:
>将数据块转换为数值向量以进行有效分析。-
数据搜索开发:
实现语义搜索以了解查询意图。-
>提示准备:
制作提示,以指导LLM检索到的数据的使用。- >
但是,这个过程通常需要调整以克服特定于项目的挑战。
抹布的承诺:-
>抹布旨在通过提供更准确和相关的响应,改善用户体验来简化信息检索。 它还允许企业利用他们的数据来更好地决策。 关键好处包括:
-
准确性提升:降低虚假信息,过时的响应以及对不可靠来源的依赖。
- 对话搜索:启用自然的,类人类的相互作用以找到信息。
现实世界挑战:
>虽然有希望,但抹布并不是一个完美的解决方案。 我们的经验突出了一些挑战:
不能保证准确性-
:> AI可能会误解或错误地检索信息。
>
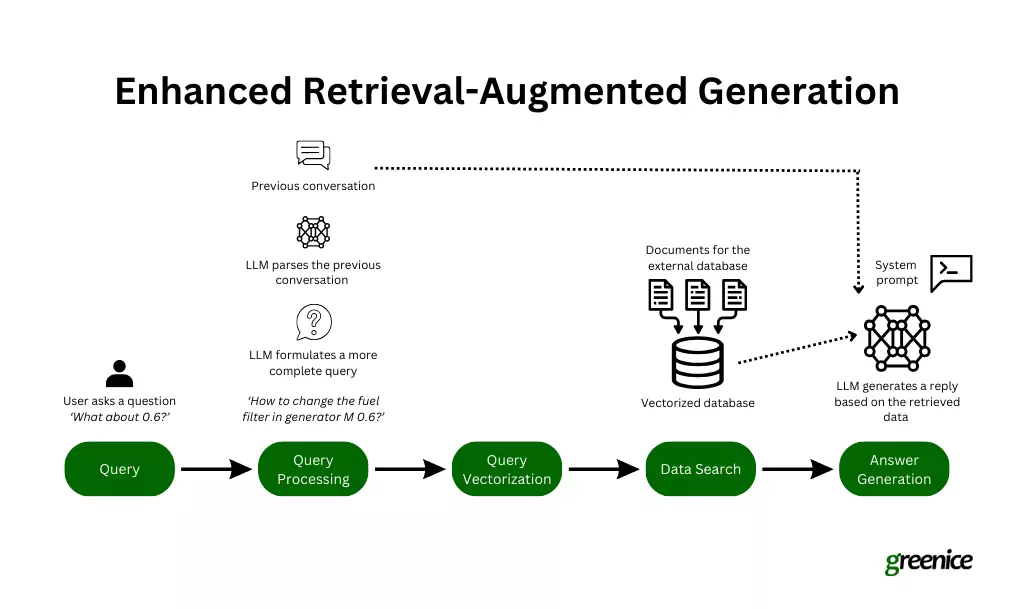
- 对话搜索的细微差别:处理不完整或上下文切换查询很困难。
>
-
数据库导航:有效地通过大型数据库进行搜索至关重要。
- >幻觉:当数据不可用时,AI可能会发明信息。>
>找到“正确”方法:单个抹布方法可能无法在不同的项目和数据集中起作用。
>
-
钥匙要点和抹布的未来:>
关键要点包括需要适应性,持续改进和有效的数据管理。 RAG的未来可能涉及:
增强的上下文理解:
改进的NLP可以更好地处理对话差异。
- >更广泛的实施:在各个行业中采用更广泛的采用。
针对现有挑战的创新解决方案:
解决诸如幻觉之类的问题。-
总之,RAG提供了巨大的潜力,但需要持续的发展和适应才能充分实现其收益。
以上是检索演出的一代:革命还是过度宣传?的详细内容。更多信息请关注PHP中文网其他相关文章!


 >
>





















