

(本文最初由 Ampere Computing 发布)
您的应用程序运行在新的云实例或服务器(或 SUT,被测系统)上,您发现存在性能问题,或者您希望确保在可用的系统资源前提下获得最佳性能。本文讨论了一些您应该提出的基本问题以及解答这些问题的方法。
前提条件:了解您的虚拟机或服务器
在开始故障排除或进行性能分析练习之前,您需要了解可用的系统资源。系统级性能通常归结为四个组件及其相互作用方式——CPU、内存、网络、磁盘。另请参阅 Brendan Gregg 的优秀文章《Linux 性能分析:60000 毫秒速成指南》,这篇文章是快速评估性能问题的绝佳起点。
本文解释了如何更深入地了解性能问题。
确定 CPU 类型
运行 $lscpu 命令,它将显示 CPU 类型、CPU 频率、核心数量和其他 CPU 相关信息:
<code>ampere@colo1:~$ lscpu
Architecture: aarch64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 160
On-line CPU(s) list: 0-159
Thread(s) per core: 1
Core(s) per socket: 80
Socket(s): 2
NUMA node(s): 2
Vendor ID: ARM
Model: 1
Model name: Neoverse-N1
Stepping: r3p1
CPU max MHz: 3000.0000
CPU min MHz: 1000.0000
BogoMIPS: 50.00
L1d cache: 10 MiB
L1i cache: 10 MiB
L2 cache: 160 MiB
NUMA node0 CPU(s): 0-79
NUMA node1 CPU(s): 80-159
Vulnerability Itlb multibit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; __user pointer sanitization
Vulnerability Spectre v2: Mitigation; CSV2, BHB
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid
asimdrdm lrcpc dcpop asimddp ssbs </code>确定内存配置
运行 $free 命令,它将提供有关物理内存和交换内存总量的信息(包括内存利用率的细分)。运行 Multichase 基准测试以确定实例/SUT 的延迟、内存带宽和负载延迟:
<code>ampere@colo1:~$ free
total used free shared buff/cache available
Mem: 130256992 3422844 120742736 4208 6091412 125852984
Swap: 8388604 0 8388604
</code>评估网络能力
运行 $ethtool 命令,它将提供有关 NIC 卡硬件设置的信息。它还用于控制网络设备驱动程序和硬件设置。如果您正在客户端-服务器模型中运行工作负载,则最好了解客户端和服务器之间的带宽和延迟。为了确定带宽,简单的 iperf3 测试就足够了,而对于延迟,简单的 ping 测试就能提供该值。在客户端-服务器设置中,还建议将网络跳数保持在最低限度。traceroute 是一个网络诊断命令,用于显示路由并测量数据包跨网络的传输延迟:
<code>ampere@colo1:~$ ethtool -i enp1s0np0 driver: mlx5_core version: 5.7-1.0.2 firmware-version: 16.32.1010 (RCP0000000001) expansion-rom-version: bus-info: 0000:01:00.0 supports-statistics: yes supports-test: yes supports-eeprom-access: no supports-register-dump: no supports-priv-flags: yes> </code>
了解存储基础架构
在开始运行工作负载之前,了解磁盘功能至关重要。了解磁盘和文件系统的吞吐量和延迟将有助于您有效地规划和设计工作负载。灵活 I/O(或“fio”)是确定这些值的理想工具。
现在进入十大问题
总拥有成本的主要组成部分之一是 CPU。因此,值得了解 CPU 的使用效率。空闲的 CPU 通常意味着存在外部依赖项,例如等待磁盘或网络访问。始终建议监控 CPU 利用率并检查核心使用情况是否均匀。
下图显示了 $top -1 命令的一个示例输出。

现代 CPU 使用 p 状态来调整其运行的频率和电压,以便在不需要更高频率时降低 CPU 的功耗。这称为动态电压和频率缩放 (DVFS),由操作系统管理。在 Linux 中,p 状态由 CPUFreq 子系统管理,该子系统使用不同的算法(称为调控器)来确定 CPU 的运行频率。通常,对于对性能敏感的应用程序,最好确保使用性能调控器,以下命令使用 cpupower 实用程序来实现这一点。请记住,CPU 应运行的频率利用率取决于工作负载:
<code>ampere@colo1:~$ lscpu
Architecture: aarch64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 160
On-line CPU(s) list: 0-159
Thread(s) per core: 1
Core(s) per socket: 80
Socket(s): 2
NUMA node(s): 2
Vendor ID: ARM
Model: 1
Model name: Neoverse-N1
Stepping: r3p1
CPU max MHz: 3000.0000
CPU min MHz: 1000.0000
BogoMIPS: 50.00
L1d cache: 10 MiB
L1i cache: 10 MiB
L2 cache: 160 MiB
NUMA node0 CPU(s): 0-79
NUMA node1 CPU(s): 80-159
Vulnerability Itlb multibit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; __user pointer sanitization
Vulnerability Spectre v2: Mitigation; CSV2, BHB
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid
asimdrdm lrcpc dcpop asimddp ssbs </code>要检查运行应用程序时 CPU 的频率,请运行以下命令:
<code>ampere@colo1:~$ free
total used free shared buff/cache available
Mem: 130256992 3422844 120742736 4208 6091412 125852984
Swap: 8388604 0 8388604
</code>有时需要找出 CPU 时间的百分比是在用户空间消耗的还是在特权时间(即内核空间)消耗的。对于某些类别的工作负载(例如网络绑定工作负载),较高的内核时间可能是合理的,但也可能表明存在问题。
Linux 应用程序 top 可用于找出用户与内核时间的消耗情况,如下所示。
mpstat——检查每个 CPU 的统计信息,并检查各个热点/繁忙的 CPU。这是一个多处理器统计工具,可以报告每个 CPU 的统计信息(-P 选项)

要识别每个 CPU 的 CPU 使用情况并显示用户时间/内核时间的比率,%usr、%sys 和 %idle 是关键值。这些关键值还可以帮助识别可能由单线程应用程序或中断映射引起的“热点”CPU。
当您管理服务器时,您可能必须安装新的应用程序,或者您可能注意到应用程序已开始变慢。为了管理系统资源并了解系统已安装的系统内存和系统内存利用率,$free 命令是一个有价值的工具。$vmstat 也是监控内存利用率的有价值的工具,如果您正在主动将内存与虚拟内存交换,则尤其如此。
free。Linux free 命令显示内存和交换统计信息。

输出显示系统的总内存、已用内存和可用内存。一个重要的列是可用值,它显示应用程序可用的内存,需要交换。它还考虑了无法立即回收的内存。
vmstat。此命令提供系统内存、运行状况的高级视图,包括当前可用内存和分页统计信息。
$vmstat 命令显示正在交换的活动内存(分页)。

这些命令打印当前状态的摘要。列默认为千字节,分别是:
如果 si 和 so 非零,则系统处于内存压力下,并且正在将内存交换到交换设备。
要了解足够的内存带宽,首先获取系统的“最大内存带宽”值。“最大内存带宽”值可以通过以下方式找到:
此值表示系统的理论最大带宽,也称为“突发速率”。您现在可以对系统运行 Multichase 或带宽基准测试并验证这些值。
注意:已经发现突发速率可能无法维持,并且实现的值可能略小于计算值。
在服务器上运行工作负载时,作为性能调整或故障排除的一部分,您可能想知道特定进程当前在哪个 CPU 核心上调度,以及在该 CPU 核心上运行的进程的资源利用情况。第一步是找到在 CPU 核心上运行的进程。这可以使用 htop 来完成。CPU 值不会反映在 htop 的默认显示中。要获取 CPU 核心值,请从命令行启动 $htop,按 F2 键,转到“列”,然后在“可用列”下添加“处理器”。每个进程当前使用的“CPU ID”将出现在“CPU”列下。
如何配置 $htop 以显示 CPU/核心:

显示核心 4-6 达到最大值的 $htop 命令(htop 核心计数从“1”而不是“0”开始):

用于检查统计信息的选定核心的 $mpstat 命令:

一旦您确定了 CPU 核心,就可以运行 $mpstat 命令来检查每个 CPU 的统计信息并检查各个热点/繁忙的 CPU。这是一个多处理器统计工具,可以报告每个 CPU(或核心)的统计信息。有关 $mpstat 的更多信息,请参见上面的“我在应用程序中花费的时间与内核时间相比如何?”部分。
即使在您饱和服务器上的其他资源之前,也可能发生网络瓶颈。当在客户端-服务器模型中运行工作负载时,就会发现此问题。您需要做的第一件事是确定您的网络外观。客户端和服务器之间的延迟和带宽尤其重要。像 iperf3、ping 和 traceroute 这样的工具是简单的工具,可以帮助您确定网络的限制。一旦确定了网络的限制,像 $dstat 和 $nicstat 这样的工具就可以帮助您监控网络利用率并确定由于网络而导致的任何系统瓶颈。
dstat。此命令用于监控系统资源,包括 CPU 统计信息、磁盘统计信息、网络统计信息、分页统计信息和系统统计信息。要监控网络利用率,请使用 -n 选项。

该命令将提供系统接收和发送的数据包的吞吐量。
nicstat。此命令打印网络接口统计信息,包括吞吐量和利用率。

列包括:
与网络一样,磁盘也可能是应用程序性能低下的原因。在衡量磁盘性能时,我们会查看以下指标:
一个好的规则是,当您为应用程序选择服务器/实例时,必须首先对磁盘的 I/O 性能进行基准测试,以便您可以获得磁盘性能的峰值或“上限”,并且能够确定磁盘性能是否满足应用程序的需求。灵活 I/O 是确定这些值的理想工具。
应用程序运行后,您可以使用 $iostat 和 $dstat 实时监控磁盘资源利用率。
iostat 命令显示每个磁盘的 I/O 统计信息,提供用于工作负载表征、利用率和饱和度的指标。

第一行输出显示系统的摘要,包括内核版本、主机名、数据架构和 CPU 计数。第二行显示自启动以来系统的 CPU 摘要。
对于后续行中显示的每个磁盘设备,它在列中显示基本详细信息:
dstat 命令用于监控系统资源,包括 CPU 统计信息、磁盘统计信息、网络统计信息、分页统计信息和系统统计信息。要监控磁盘利用率,请使用 -d 选项。该选项将显示磁盘上读取 (read) 和写入 (writ) 操作的总数。
下图演示了写入密集型工作负载。

非一致性内存访问 (NUMA) 是一种用于多处理的计算机内存设计,其中内存访问时间取决于相对于处理器的内存位置。在 NUMA 下,处理器可以比非本地内存(另一个处理器的本地内存或处理器之间共享的内存)更快地访问其自己的本地内存。NUMA 的好处仅限于工作负载,尤其是在服务器上,数据通常与某些任务或用户紧密相关。
在 NUMA 系统上,处理器与其内存库之间的距离越大,处理器访问该内存库的速度就越慢。对于对性能敏感的应用程序,系统操作系统应从最接近的内存库分配内存。要实时监控系统或进程的内存分配,$numastat 是一个很好的工具。
numastat 命令提供非一致性内存访问 (NUMA) 系统的统计信息。这些系统通常是具有多个 CPU 插槽的系统。

Linux 操作系统尝试在最近的 NUMA 节点上分配内存,$numastat 显示内存分配的当前统计信息。
Numa_miss 和 Numa_foreign 都显示不在首选 NUMA 节点上的内存分配。理想情况下,numa_miss 和 numa_foreign 的值应保持在最小值,因为较高的值会导致较差的内存 I/O 性能。
$numastat -p <process></process> 命令也可用于查看进程的 NUMA 分布。
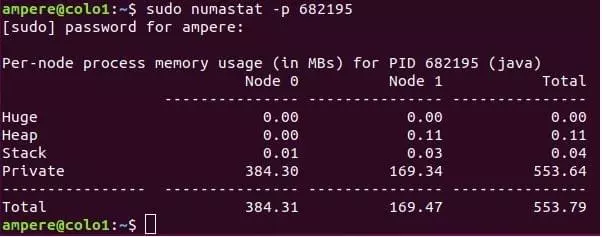
在系统/实例上运行应用程序时,您将有兴趣了解应用程序正在做什么以及应用程序在 CPU 上使用的资源。$pidstat 是一个命令行工具,可以监控系统上运行的每个单独进程。
pidstat 将把主要的 CPU 使用者分解为用户时间和系统时间。
此 Linux 工具按进程或线程细分 CPU 使用情况,包括用户时间和系统时间。此命令还可以报告进程的 IO 统计信息(-d 选项)。

$pidstat -p 也可以运行以收集有关特定进程的数据。

请与我们的专家销售团队联系,了解合作伙伴关系或通过我们的开发者访问计划了解如何访问 Ampere 系统。
以上是在基于Ampere Altra的实例上运行时的10个关键问题的详细内容。更多信息请关注PHP中文网其他相关文章!





















