
> reft:一种革命性的微调LLMS
> 在斯坦福(Stanford)2024年5月的论文中引入的REFT(表示命名)提供了一种开创性的方法,可有效地微调大型语言模型(LLMS)。 它的潜力立即显现出来,由Oxen.AI于2024年7月的2024年7月在短短14分钟内的单个NVIDIA A10 GPU上进行了微调Llama3(8b)。 与现有的参数效率微调(PEFT)方法(如Lora)不同,lora修改模型权重或输入,REFT利用分布式互换干预(DII)方法。 DII项目将嵌入较低维的子空间嵌入,从而通过此子空间进行微调。>本文首先回顾了流行的PEFT算法(LORA,提示调整,前缀调整),然后解释DII,然后再研究REFT及其实验结果。
>参数有效的微调(PEFT)技术
 拥抱脸提供了PEFT技术的全面概述。 让我们简要总结关键方法:
拥抱脸提供了PEFT技术的全面概述。 让我们简要总结关键方法:
在2021年推出,洛拉(Lora)的简单性和概括性使其成为微调LLMS和扩散模型的领先技术。 Lora没有调整所有层重量,而是增加了低级矩阵,大大降低了可训练的参数(通常小于0.3%),加速训练并最大程度地减少GPU内存使用。
提示调整:

>
前缀调整(p-tuning v2):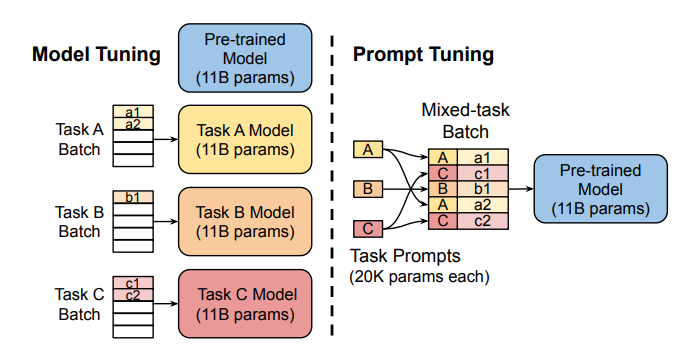 解决迅速调整的限制,前缀调整将可训练的及时嵌入到各种层中,从而允许在不同级别上进行特定于任务的学习。
解决迅速调整的限制,前缀调整将可训练的及时嵌入到各种层中,从而允许在不同级别上进行特定于任务的学习。
洛拉的鲁棒性和效率使其成为LLMS最广泛使用的PEFT方法。 可以在 >中找到详细的经验比较。
>中找到详细的经验比较。
DII植根于因果抽象中,这是一种使用高级(因果)模型和低级(神经网络)模型之间的干预框架来评估一致性的框架。 DII通过正交预测将这两个模型投入到子空间中,从而通过旋转操作创建了介入的模型。 一个详细的视觉示例>。 DII过程可以用数学表示为: 其中
Loreft(低率线性子空间REFT)引入了一个学识渊博的投影来源: 其中 编辑 )。
原始的REFT纸提出了对全面微调(FT),Lora和前缀调整的比较实验。 REFT技术始终优于现有方法,在达到卓越的性能的同时,将参数降低至少90%。 讨论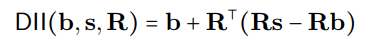
R代表正交投影,分布式对齐搜索(DAS)优化了子空间,以最大程度地提高预期后预期的反事实输出的概率。> reft - 表示finetuning
REFT在较低维空间内介入模型的隐藏表示形式。 下图显示了应用于L层和位置P的干预措施(PHI)
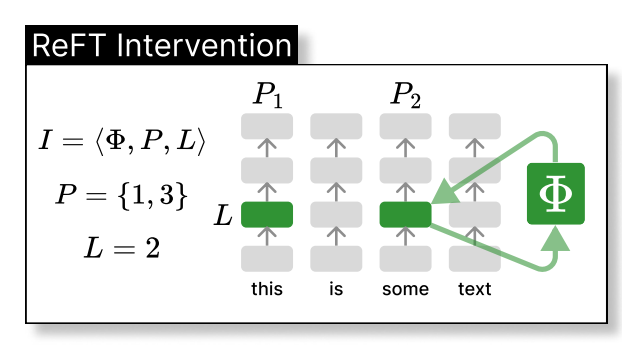
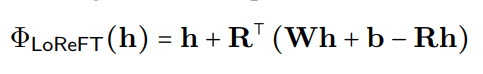 是隐藏的表示,而在由
是隐藏的表示,而在由h。 Loreft集成到神经网络层中如下所示:Rs
hR 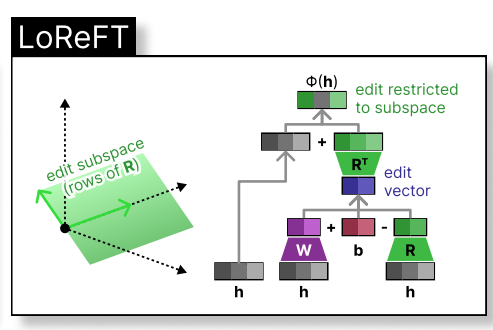 实验结果
实验结果phi={R, W, b}
参考
以上是我们需要的一切吗?的详细内容。更多信息请关注PHP中文网其他相关文章!





















