

2024年编码的LLM:价格,性能和争取最佳的战斗

用于编码的大语言模型(LLM)的快速发展的景观
提供了丰富的选择的开发人员。 该分析比较了可以通过公共API访问的顶级LLM,重点是通过HumaneVal和Real-Word Elo Scores等基准测量的编码实力。 无论您是构建个人项目还是将AI集成到工作流程中,了解这些模型的优势和劣势对于明智的决策至关重要。
> LLM比较的挑战> 由于频繁的模型更新(即使是次要的表现),LLMS的固有随机性导致结果不一致以及基准设计和报告的潜在偏见,因此很难进行直接比较。 该分析代表了基于当前可用数据的最佳及时比较。
>
评估指标:HumaneVal和Elo分数:
- HumaneVal:
-
ELO分数(Chatbot Arena-仅编码):
来自人类所判断的头对头LLM比较。 较高的ELO分数表明相对性能出色。 100分的差异表明高评分模型的获胜率约为64%。 - 性能概述:
OpenAI的模型始终在人道主义和ELO排名中均始终如一,展示了出色的编码功能。 o1-mini模型令人惊讶地超过了两个指标中较大的
o1模型。 其他公司的最佳模型表现出可比的性能,尽管落后于Openai。

>基准与现实世界的性能差异:

Mistral大型,在人类事件上的表现要比现实世界中的使用情况更好(潜在的过度拟合),而其他模型(例如Google的 平衡性能和价格: > Pareto Front(最佳性能和价格平衡)主要具有OpenAI(高性能)和Google(货币价值)模型。 META的开源美洲驼模型,基于云提供商平均价格,也显示出竞争价值。 其他洞察力:
编码LLM景观是动态的。 开发人员应定期评估最新模型,考虑性能和成本。 了解基准的局限性和优先考虑多样化的评估指标对于做出明智的选择至关重要。 该分析提供了当前状态的快照,并且连续监测对于在这个快速发展的领域保持领先地位至关重要。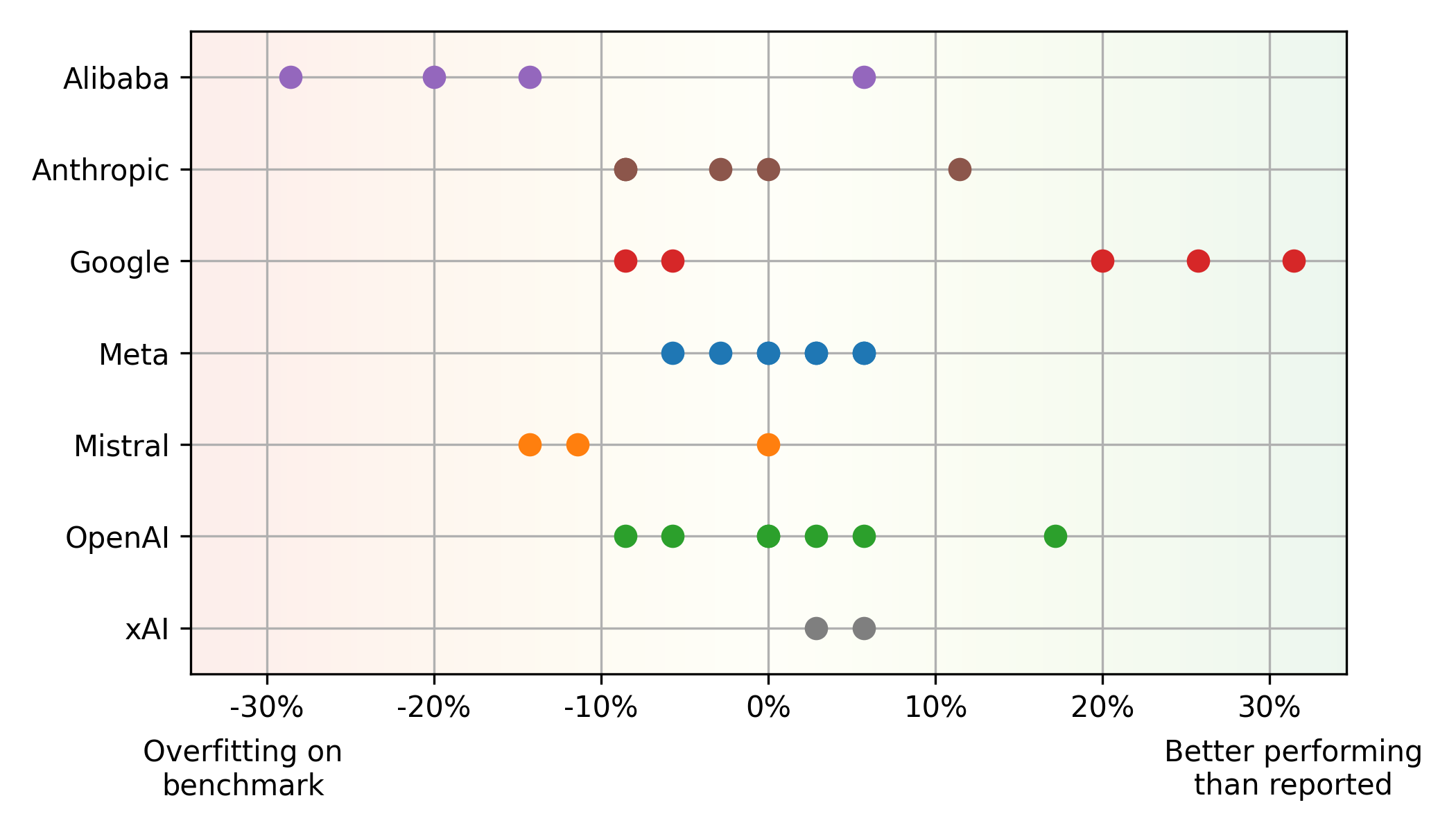




 LLM始终提高性能和成本降低。尽管开源模型正在赶上,但专有模型仍保持优势。 即使是较小的更新也会显着影响性能和/或定价。
LLM始终提高性能和成本降低。尽管开源模型正在赶上,但专有模型仍保持优势。 即使是较小的更新也会显着影响性能和/或定价。
以上是2024年编码的LLM:价格,性能和争取最佳的战斗的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 如何使用AGNO框架构建多模式AI代理?
Apr 23, 2025 am 11:30 AM
如何使用AGNO框架构建多模式AI代理?
Apr 23, 2025 am 11:30 AM
在从事代理AI时,开发人员经常发现自己在速度,灵活性和资源效率之间进行权衡。我一直在探索代理AI框架,并遇到了Agno(以前是Phi-
 如何在SQL中添加列? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
如何在SQL中添加列? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
SQL的Alter表语句:动态地将列添加到数据库 在数据管理中,SQL的适应性至关重要。 需要即时调整数据库结构吗? Alter表语句是您的解决方案。本指南的详细信息添加了Colu
 OpenAI以GPT-4.1的重点转移,将编码和成本效率优先考虑
Apr 16, 2025 am 11:37 AM
OpenAI以GPT-4.1的重点转移,将编码和成本效率优先考虑
Apr 16, 2025 am 11:37 AM
该版本包括三种不同的型号,GPT-4.1,GPT-4.1 MINI和GPT-4.1 NANO,标志着向大语言模型景观内的特定任务优化迈进。这些模型并未立即替换诸如
 超越骆驼戏:大型语言模型的4个新基准
Apr 14, 2025 am 11:09 AM
超越骆驼戏:大型语言模型的4个新基准
Apr 14, 2025 am 11:09 AM
陷入困境的基准:骆驼案例研究 2025年4月上旬,梅塔(Meta)揭开了Llama 4套件的模特套件,具有令人印象深刻的性能指标,使他们对GPT-4O和Claude 3.5 Sonnet等竞争对手有利地定位。伦斯的中心
 Andrew Ng的新简短课程
Apr 15, 2025 am 11:32 AM
Andrew Ng的新简短课程
Apr 15, 2025 am 11:32 AM
解锁嵌入模型的力量:深入研究安德鲁·NG的新课程 想象一个未来,机器可以完全准确地理解和回答您的问题。 这不是科幻小说;多亏了AI的进步,它已成为R
 多动症游戏,健康工具和AI聊天机器人如何改变全球健康
Apr 14, 2025 am 11:27 AM
多动症游戏,健康工具和AI聊天机器人如何改变全球健康
Apr 14, 2025 am 11:27 AM
视频游戏可以缓解焦虑,建立焦点或支持多动症的孩子吗? 随着医疗保健在全球范围内挑战,尤其是在青年中的挑战,创新者正在转向一种不太可能的工具:视频游戏。现在是世界上最大的娱乐印度河之一
 火箭发射模拟和分析使用Rocketpy -Analytics Vidhya
Apr 19, 2025 am 11:12 AM
火箭发射模拟和分析使用Rocketpy -Analytics Vidhya
Apr 19, 2025 am 11:12 AM
模拟火箭发射的火箭发射:综合指南 本文指导您使用强大的Python库Rocketpy模拟高功率火箭发射。 我们将介绍从定义火箭组件到分析模拟的所有内容
 Google揭示了下一个2025年云上最全面的代理策略
Apr 15, 2025 am 11:14 AM
Google揭示了下一个2025年云上最全面的代理策略
Apr 15, 2025 am 11:14 AM
双子座是Google AI策略的基础 双子座是Google AI代理策略的基石,它利用其先进的多模式功能来处理和生成跨文本,图像,音频,视频和代码的响应。由DeepM开发
