
>本文深入研究大型语言模型(LLMS)的实际方面,重点介绍了Codex和Constractgpt作为主要示例。 这是探索GPT模型的系列中的第三个,基于先前关于预训练和缩放的讨论。
。
>微调至关重要,因为虽然预训练的LLM是用途广泛,但它们通常不属于针对特定任务的专业模型。 此外,即使像GPT-3这样的强大模型也可能在复杂的说明中挣扎,并保持安全和道德标准。 这需要进行微调策略。
>本文重点介绍了两个关键的微调挑战:适应新的模式(例如Codex对代码生成的改编),并将模型与人类偏好相结合(如《指南》所示)。 两者都需要仔细考虑数据收集,模型体系结构,目标功能和评估指标。
>codex:代码生成的微调
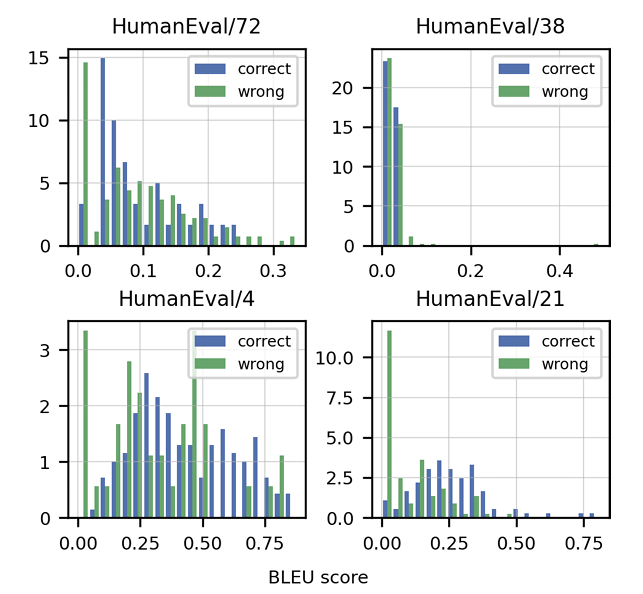
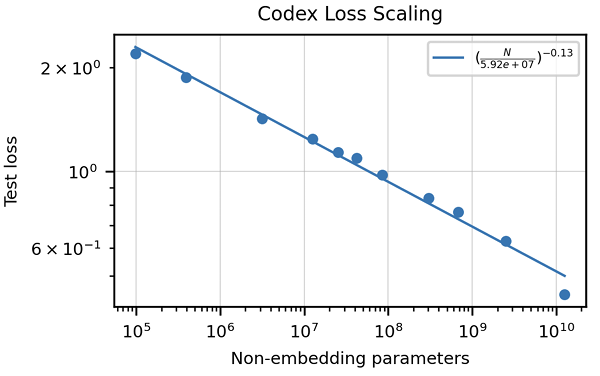
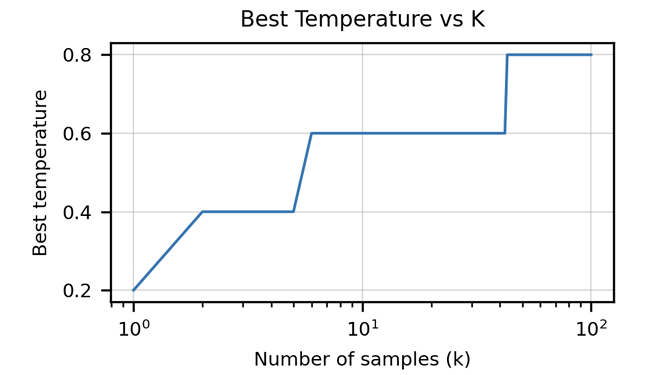
>>该文章强调了传统指标(例如BLEU得分)的不足来评估代码生成。 它引入了“功能正确性”和pass@k 公制,提供了更强大的评估方法。 还突出显示了由单位测试组成手写编程问题的人道数据集的创建。 讨论了特定代码的数据清洁策略,以及适应代币器以处理编程语言的独特特征(例如Whitespace编码)的重要性。 本文介绍了与HOMANEVAL的GPT-3相比,Codex表现出色的结果,并探讨了模型大小和温度对性能的影响。


> consendgpt and chatgpt:与人类偏好对齐>
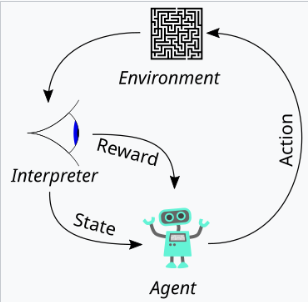
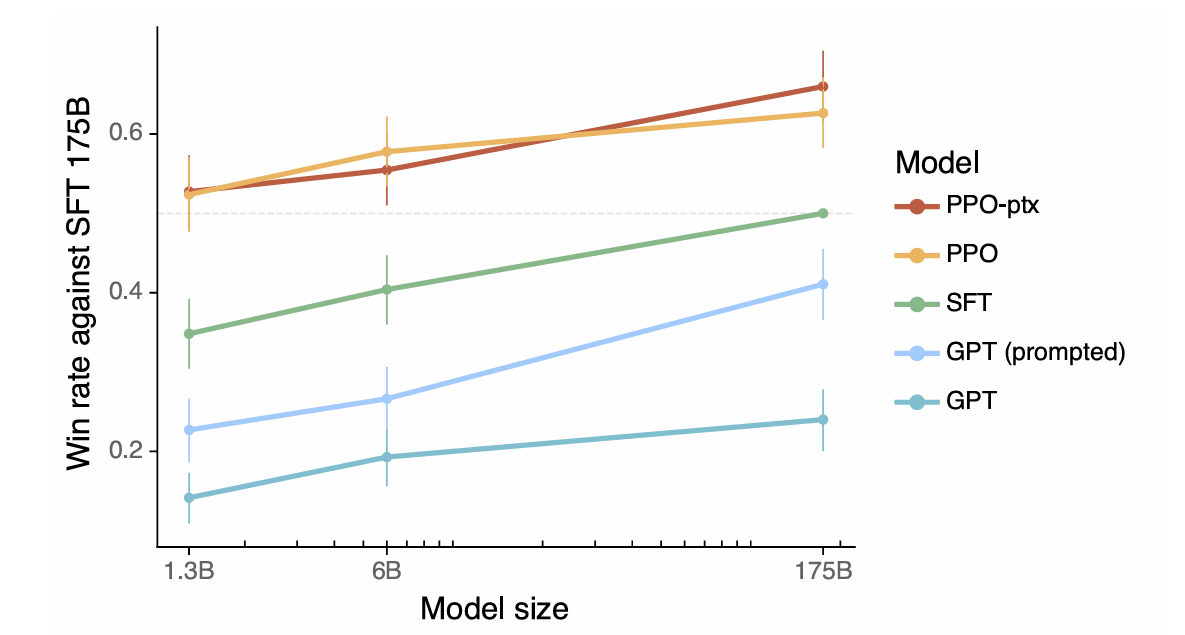
>本文将一致性定义为表现出乐于助人,诚实和无害性的模型。 它解释了如何将这些品质转化为可测量的方面,例如以下教学,幻觉率和偏见/毒性。 从人类反馈(RLHF)中使用强化学习的使用是详细的,概述了这三个阶段:收集人类反馈,培训奖励模型,并使用近端政策优化(PPO)优化政策。 文章强调了数据质量控制在人类反馈收集过程中的重要性。 结果展示了指令示威的改进对齐,减少幻觉和缓解性能回归的措施。
>

摘要和最佳实践
>>通过总结微调LLM的关键注意事项,包括定义所需的行为,评估绩效,收集和清洁数据,调整模型体系结构以及减轻潜在的负面后果。 它鼓励仔细考虑过度参数调整,并强调微调过程的迭代性质。
以上是了解chatgpt的演变:第3部分 - Codex和Consendgpt的见解的详细内容。更多信息请关注PHP中文网其他相关文章!





















