

LLM的工作方式:培训前训练,神经网络,幻觉和推理

揭示大语模型(LLMS)背后的魔力:两部分探索
大型语言模型(LLM)通常看起来很神奇,但它们的内部运作令人惊讶地系统性。这个两部分的系列揭示了LLM,并将其构建,培训和精炼解释为我们今天使用的AI系统。 受Andrej Karpathy的洞察力(和冗长!)YouTube视频的启发,该冷凝版以更容易访问的格式提供了核心概念。强烈建议您使用Karpathy的视频(仅10天内观看800,000次!),但此10分钟的读取蒸发是最初1.5小时的关键要点。>
第1部分:从原始数据到基本模型> LLM发育涉及两个关键阶段:训练前和训练后。
1。预训练:教语言> 在生成文本之前,LLM必须学习语言结构。这个计算密集的预训练过程涉及多个步骤:
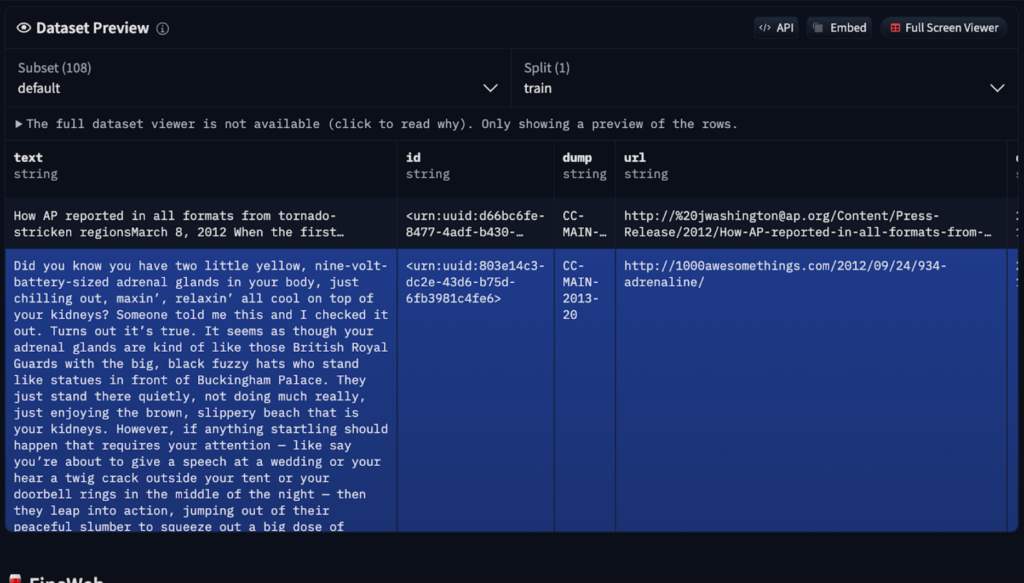
数据采集和预处理:
- 大量,多样化的数据集,通常包括诸如Common Crawl(2500亿个网页)之类的来源。 但是,原始数据需要清洁以删除垃圾邮件,重复和低质量的内容。 诸如FineWeb之类的服务提供了拥抱脸上可用的预处理版本。
- >
> 神经网络培训:
神经网络培训:
- 最终的基本模型 了解单词关系和统计模式,但缺乏现实世界的任务优化。 它的功能像高级自动完成,根据概率进行预测,但具有有限的指令跟随功能。可以采用提示中的示例中的文章学习,但需要进一步的培训。
2。训练后:用于实际用途的精炼通过使用较小的专业数据集进行培训,可以完善基础模型。 这不是明确的编程,而是通过结构化的示例进行隐式指令。
>
训练后方法包括:
- >
- 指导/对话微调:>教会模型遵循说明,进行对话,遵守安全指南并拒绝有害要求(例如,指令gpt)。 >
- >>域特异性微调:
适应特定领域的模型(医学,法律,编程)。 特殊令牌被引入以划定用户输入和AI响应。
在任何阶段执行的推论,评估模型学习。 该模型将概率分配给潜在的代币和此分布的样本,从而在培训数据中明确地创建文本,但在统计学上与之一致。此随机过程允许从同一输入中产生各种输出。>
>幻觉:解决虚假信息
> LLMS产生虚假信息的幻觉源于其概率性质。 他们不“知道”事实,而是预测可能的单词序列。 缓解策略包括:
“我不知道”培训:
- 明确训练模型,以通过自我介入和自动化问题产生来识别知识差距。
- Web搜索集成:通过访问外部搜索工具来扩展知识,将结果纳入模型的上下文窗口。
- 通过模糊的回忆(来自预训练的模式)和工作记忆(上下文窗口中的信息),llms访问知识。 系统提示可以建立一致的模型身份。
>本部分探索了LLM开发的基本方面。第2部分将深入研究并检查尖端模型。 欢迎您的问题和建议!
以上是LLM的工作方式:培训前训练,神经网络,幻觉和推理的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 如何使用AGNO框架构建多模式AI代理?
Apr 23, 2025 am 11:30 AM
如何使用AGNO框架构建多模式AI代理?
Apr 23, 2025 am 11:30 AM
在从事代理AI时,开发人员经常发现自己在速度,灵活性和资源效率之间进行权衡。我一直在探索代理AI框架,并遇到了Agno(以前是Phi-
 如何在SQL中添加列? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
如何在SQL中添加列? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
SQL的Alter表语句:动态地将列添加到数据库 在数据管理中,SQL的适应性至关重要。 需要即时调整数据库结构吗? Alter表语句是您的解决方案。本指南的详细信息添加了Colu
 OpenAI以GPT-4.1的重点转移,将编码和成本效率优先考虑
Apr 16, 2025 am 11:37 AM
OpenAI以GPT-4.1的重点转移,将编码和成本效率优先考虑
Apr 16, 2025 am 11:37 AM
该版本包括三种不同的型号,GPT-4.1,GPT-4.1 MINI和GPT-4.1 NANO,标志着向大语言模型景观内的特定任务优化迈进。这些模型并未立即替换诸如
 超越骆驼戏:大型语言模型的4个新基准
Apr 14, 2025 am 11:09 AM
超越骆驼戏:大型语言模型的4个新基准
Apr 14, 2025 am 11:09 AM
陷入困境的基准:骆驼案例研究 2025年4月上旬,梅塔(Meta)揭开了Llama 4套件的模特套件,具有令人印象深刻的性能指标,使他们对GPT-4O和Claude 3.5 Sonnet等竞争对手有利地定位。伦斯的中心
 Andrew Ng的新简短课程
Apr 15, 2025 am 11:32 AM
Andrew Ng的新简短课程
Apr 15, 2025 am 11:32 AM
解锁嵌入模型的力量:深入研究安德鲁·NG的新课程 想象一个未来,机器可以完全准确地理解和回答您的问题。 这不是科幻小说;多亏了AI的进步,它已成为R
 多动症游戏,健康工具和AI聊天机器人如何改变全球健康
Apr 14, 2025 am 11:27 AM
多动症游戏,健康工具和AI聊天机器人如何改变全球健康
Apr 14, 2025 am 11:27 AM
视频游戏可以缓解焦虑,建立焦点或支持多动症的孩子吗? 随着医疗保健在全球范围内挑战,尤其是在青年中的挑战,创新者正在转向一种不太可能的工具:视频游戏。现在是世界上最大的娱乐印度河之一
 火箭发射模拟和分析使用Rocketpy -Analytics Vidhya
Apr 19, 2025 am 11:12 AM
火箭发射模拟和分析使用Rocketpy -Analytics Vidhya
Apr 19, 2025 am 11:12 AM
模拟火箭发射的火箭发射:综合指南 本文指导您使用强大的Python库Rocketpy模拟高功率火箭发射。 我们将介绍从定义火箭组件到分析模拟的所有内容
 Google揭示了下一个2025年云上最全面的代理策略
Apr 15, 2025 am 11:14 AM
Google揭示了下一个2025年云上最全面的代理策略
Apr 15, 2025 am 11:14 AM
双子座是Google AI策略的基础 双子座是Google AI代理策略的基石,它利用其先进的多模式功能来处理和生成跨文本,图像,音频,视频和代码的响应。由DeepM开发
