

培训大语言模型:从TRPO到GRPO

DeepSeek:深入研究LLMS的加强学习 DeepSeek最近的成功,以较低的成本取得了令人印象深刻的表现,突出了大语言模型(LLM)培训方法的重要性。本文重点介绍了增强学习(RL)方面,探索TRPO,PPO和更新的GRPO算法。 假设对机器学习,深度学习和LLM的基本熟悉,我们将最大程度地减少复杂数学以使其可访问。
>> LLM培训的三个支柱
LLM培训通常涉及三个关键阶段:
>
预训练:- >该模型学会了使用大量数据集从先前的代币中以序列进行序列预测下一个令牌。
- 监督的微调(SFT):
- 强化学习(RLHF):在本阶段,本文的重点,进一步完善了通过直接反馈对更好的人类偏好的反应。 强化学习基础
代理
与环境 的交互。代理存在于特定的
的交互。代理存在于特定的
中,采取>动作>过渡到新状态。每个动作都会从环境中产生A奖励,从而指导代理人的未来行动。 想想一个机器人在迷宫中浏览:其位置是国家,运动是行动,到达出口提供了积极的奖励。 LLMS中的rl:详细的外观
在LLM培训中,组件是:
-
代理:
llm本身。 >
>- >环境:外部因素,例如用户提示,反馈系统和上下文信息。
- 动作:令牌llm对查询的响应生成。
- state:当前查询和生成的令牌(部分响应)。
奖励:- >通常由对人类通知数据训练的单独奖励模型确定,对分配得分的响应进行排名。更高质量的回应获得了更高的奖励。 在特定情况下,例如DeepSeekmath。
策略
确定要采取的行动。 对于LLM,这是对可能令牌的概率分布,用于采样接下来的令牌。 RL培训可以调整策略的参数(型号权重),以偏爱更高的代币。 该策略通常表示为:
RL的核心是找到最佳策略。 与监督的学习不同,我们使用奖励来指导政策调整。
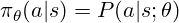 > trpo(信任区域策略优化)
> trpo(信任区域策略优化)
trpo使用优势函数,类似于监督学习中的损失函数,但从奖励中得出:

> ppo(近端策略优化) PPO,通过使用剪裁的替代目标来简化TRPO,隐含地限制了策略更新并提高了计算效率。 PPO目标函数是: grpo(组相对策略优化) >这简化了过程,非常适合LLMS生成多个响应的能力。 GRPO还包含了KL Divergence术语,将当前策略与参考策略进行了比较。最终的GRPO公式是: 增强学习,尤其是PPO和较新的GRPO,对于现代LLM培训至关重要。 每种方法都基于RL基本面,提供不同的方法,以平衡稳定性,效率和人类对齐方式。 DeepSeek的成功利用了这些进步以及其他创新。 强化学习有望在促进LLM功能方面发挥越来越重要的作用。 >参考:(参考文献保持不变,只是重新格式化以获得更好的可读性)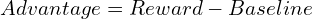
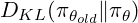

grpo的训练。对于每个查询,它都会生成一组响应,并根据其奖励计算优势作为z评分:
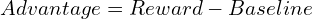

结论
以上是培训大语言模型:从TRPO到GRPO的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 如何使用AGNO框架构建多模式AI代理?
Apr 23, 2025 am 11:30 AM
如何使用AGNO框架构建多模式AI代理?
Apr 23, 2025 am 11:30 AM
在从事代理AI时,开发人员经常发现自己在速度,灵活性和资源效率之间进行权衡。我一直在探索代理AI框架,并遇到了Agno(以前是Phi-
 如何在SQL中添加列? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
如何在SQL中添加列? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
SQL的Alter表语句:动态地将列添加到数据库 在数据管理中,SQL的适应性至关重要。 需要即时调整数据库结构吗? Alter表语句是您的解决方案。本指南的详细信息添加了Colu
 OpenAI以GPT-4.1的重点转移,将编码和成本效率优先考虑
Apr 16, 2025 am 11:37 AM
OpenAI以GPT-4.1的重点转移,将编码和成本效率优先考虑
Apr 16, 2025 am 11:37 AM
该版本包括三种不同的型号,GPT-4.1,GPT-4.1 MINI和GPT-4.1 NANO,标志着向大语言模型景观内的特定任务优化迈进。这些模型并未立即替换诸如
 超越骆驼戏:大型语言模型的4个新基准
Apr 14, 2025 am 11:09 AM
超越骆驼戏:大型语言模型的4个新基准
Apr 14, 2025 am 11:09 AM
陷入困境的基准:骆驼案例研究 2025年4月上旬,梅塔(Meta)揭开了Llama 4套件的模特套件,具有令人印象深刻的性能指标,使他们对GPT-4O和Claude 3.5 Sonnet等竞争对手有利地定位。伦斯的中心
 Andrew Ng的新简短课程
Apr 15, 2025 am 11:32 AM
Andrew Ng的新简短课程
Apr 15, 2025 am 11:32 AM
解锁嵌入模型的力量:深入研究安德鲁·NG的新课程 想象一个未来,机器可以完全准确地理解和回答您的问题。 这不是科幻小说;多亏了AI的进步,它已成为R
 多动症游戏,健康工具和AI聊天机器人如何改变全球健康
Apr 14, 2025 am 11:27 AM
多动症游戏,健康工具和AI聊天机器人如何改变全球健康
Apr 14, 2025 am 11:27 AM
视频游戏可以缓解焦虑,建立焦点或支持多动症的孩子吗? 随着医疗保健在全球范围内挑战,尤其是在青年中的挑战,创新者正在转向一种不太可能的工具:视频游戏。现在是世界上最大的娱乐印度河之一
 火箭发射模拟和分析使用Rocketpy -Analytics Vidhya
Apr 19, 2025 am 11:12 AM
火箭发射模拟和分析使用Rocketpy -Analytics Vidhya
Apr 19, 2025 am 11:12 AM
模拟火箭发射的火箭发射:综合指南 本文指导您使用强大的Python库Rocketpy模拟高功率火箭发射。 我们将介绍从定义火箭组件到分析模拟的所有内容
 Google揭示了下一个2025年云上最全面的代理策略
Apr 15, 2025 am 11:14 AM
Google揭示了下一个2025年云上最全面的代理策略
Apr 15, 2025 am 11:14 AM
双子座是Google AI策略的基础 双子座是Google AI代理策略的基石,它利用其先进的多模式功能来处理和生成跨文本,图像,音频,视频和代码的响应。由DeepM开发
