
>在此博客中,我们将构建一个多语言代码说明应用程序,以展示Llama 3.3的功能,尤其是其在推理,按照说明,编码和多语言支持方面的优势。
>此应用程序将允许用户:
llama 3.3从拥抱脸上进行处理。
设置Llama 3.3
>在拥抱脸上访问骆驼3.3>
>访问美洲驼3.3的一种方法是通过拥抱面孔,这是托管机器学习模型最受欢迎的平台之一。要通过拥抱Face的推理API使用Llama 3.3,您将需要:
>现在已经准备好了,让我们安装必要的库。确保您正在运行Python 3.8。在终端中,运行以下命令以安装简化,请求和拥抱面部库:
mkdir multilingual-code-explanation cd multilingual-code-explanation
到现在,您应该有:
写后端
>导入所需库
设置API Access
mkdir multilingual-code-explanation cd multilingual-code-explanation
api端点(托管模型的URL)。
>python3 -m venv venv source venv/bin/activate’
>用您之前生成的令牌替换“ hf_your_api_key_here”。
>构建一个提示,告诉模型该怎么做。
pip install streamlit requests transformers huggingface-hub
接下来,定义了有效载荷。对于输入,我们指定提示发送到模型。在参数中,max_new_tokens控制响应长度,而温度调整了输出的创造力级别。
> requests.post()函数将数据发送到拥抱面。如果响应成功(status_code == 200),则提取生成的文本。如果有错误,则返回描述性消息。>
>最后,有一些步骤可以正确清洁和格式化输出。这样可以确保它整齐地展示,从而大大改善了用户体验。构建精简前端
前端是用户与应用程序进行交互的地方。简化是一个仅使用Python代码创建交互式Web应用程序的库,并使此过程变得简单而直观。这就是我们将用来构建应用程序前端的方法。我真的很喜欢简化来构建演示和POC!
>>导入流lit
mkdir multilingual-code-explanation cd multilingual-code-explanation
>我们将使用set_page_config()来定义应用标题和布局。在下面的代码中:
python3 -m venv venv source venv/bin/activate’
> st.sidebar.title():为侧边栏创建标题。
pip install streamlit requests transformers huggingface-hub
> text_area():为粘贴代码创建一个大盒子。
import requests
text_input():允许用户输入语言。
HUGGINGFACE_API_KEY = "hf_your_api_key_here" # Replace with your actual API key
API_URL = "https://api-inference.huggingface.co/models/meta-llama/Llama-3.3-70B-Instruct"
HEADERS = {"Authorization": f"Bearer {HUGGINGFACE_API_KEY}"}在查询API时显示旋转器。
def query_llama3(input_text, language):
# Create the prompt
prompt = (
f"Provide a simple explanation of this code in {language}:\n\n{input_text}\n"
f"Only output the explanation and nothing else. Make sure that the output is written in {language} and only in {language}"
)
# Payload for the API
payload = {
"inputs": prompt,
"parameters": {"max_new_tokens": 500, "temperature": 0.3},
}
# Make the API request
response = requests.post(API_URL, headers=HEADERS, json=payload)
if response.status_code == 200:
result = response.json()
# Extract the response text
full_response = result[0]["generated_text"] if isinstance(result, list) else result.get("generated_text", "")
# Clean up: Remove the prompt itself from the response
clean_response = full_response.replace(prompt, "").strip()
# Further clean any leading colons or formatting
if ":" in clean_response:
clean_response = clean_response.split(":", 1)[-1].strip()
return clean_response or "No explanation available."
else:
return f"Error: {response.status_code} - {response.text}"显示如果缺少输入,则显示生成的解释或警告。
该应用程序将在您的浏览器中打开,您可以开始使用它!
>import streamlit as st
测试Llama 3.3行动
st.set_page_config(page_title="Multilingual Code Explanation Assistant", layout="wide")
测试1:python中的阶乘功能
对于我们的第一个测试,让我们从一个Python脚本开始,该脚本可以使用递归计算数字的阶乘。这是我们将使用的代码:
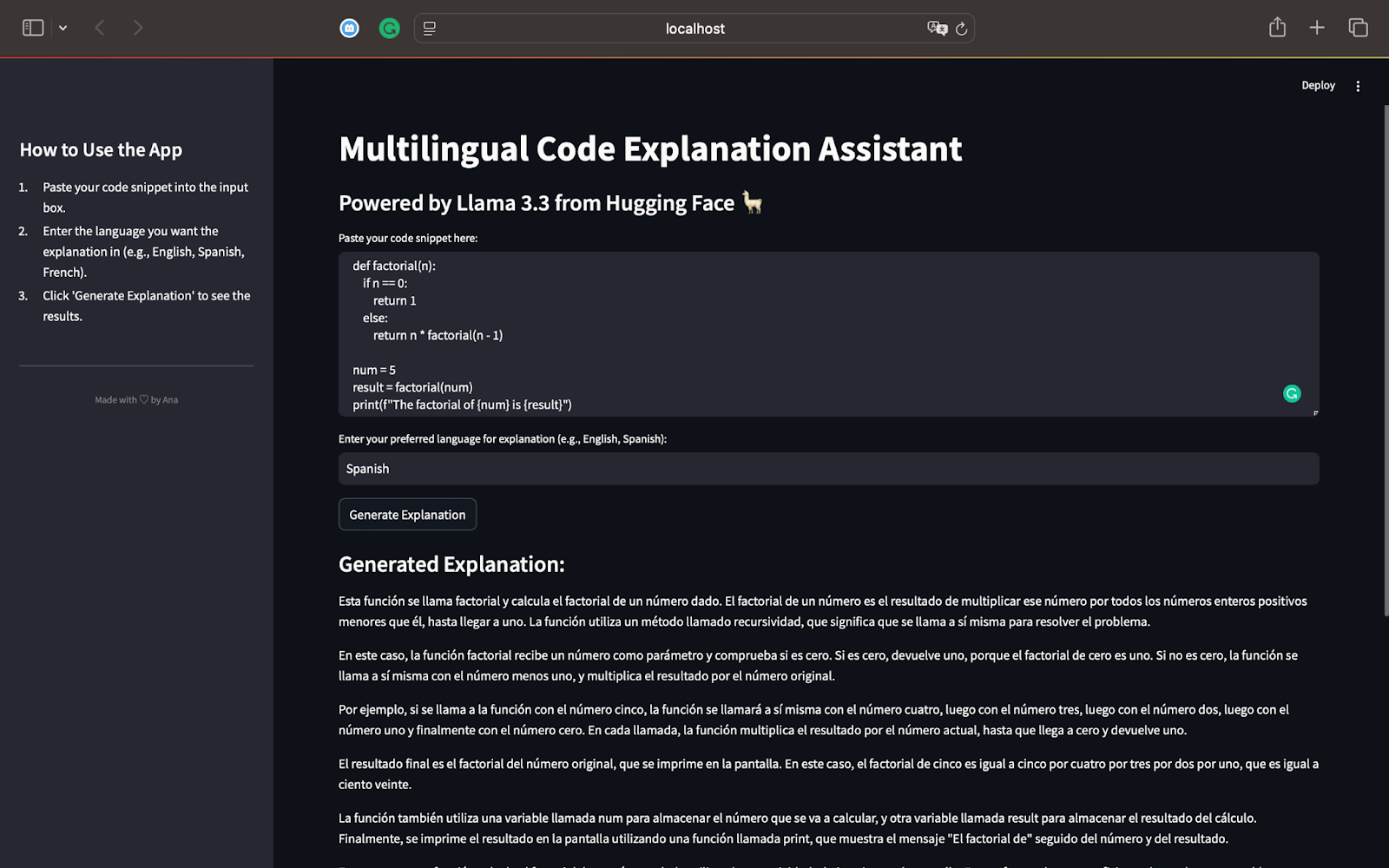

>该模型解释了递归过程,并显示了该函数如何以n值的降低为直到达到0。
的解释完全按照要求,展示了Llama 3.3的多语言能力。的使用简单短语使递归的概念易于遵循,即使对于不熟悉编程的读者也很容易遵循。
>总结并提到了递归如何适用于其他输入,以及递归作为编程中有效解决问题的概念的重要性。
>该第一次测试突出了骆驼3.3的力量:
它以逐步的方式准确地解释了代码。
>>解释适用于请求的语言(在这种情况下为西班牙语)。
此代码段定义递归函数x(a),该函数计算给定数字a的阶乘。基本条件检查是否=== 1。如果是,则返回1。否则,该函数用-1调用自身,并将结果乘以a。常数y设置为6,因此函数x计算6×5×4×3×2×1。 fnally,结果存储在变量z中,并使用console.log显示。这是英文的输出和翻译:
>注意:您可以看到它看起来像是突然裁剪了响应,但这是因为我们将输出限制为500个令牌!
>翻译此内容后,我得出的结论是,解释正确地识别了函数x(a)是递归的。它分解了递归的工作原理,解释了基本情况(a === 1)和递归情况(a * x(a -1))。该解释明确显示了该函数如何计算6的阶乘,并提及Y(输入值)和Z(结果)的作用。它还指出了console.log用于显示结果的方式。> 根据要求,
的解释完全用法语。正确使用了诸如“Récursive”(递归),“ Factorielle”(阶乘)和“ Produit”(产品)之类的技术术语。不仅如此,它还标识了此代码以递归方式计算数字的阶乘。>
>解释避免了过度技术术语并简化了递归,使得刚接触编程的读者可以访问。此测试证明了Llama 3.3:
在最后一次测试中,我们将评估多语言代码说明应用程序如何处理SQL查询并生成德语说明。这是使用的SQL摘要:
>此查询选择ID列并计算每个ID的总值(sum(b.value))。它从两个表中读取数据:table_x(Aliase为a)和table_y(将其混为为b)。然后,使用联接条件连接行,其中a.ref_id = b.ref。它过滤行,其中b.flag = 1并按A.ID分组数据。 HAVER子句将组仅包括B.Value总和大于1000的那些。最后,按deal_amount订购结果。
mkdir multilingual-code-explanation cd multilingual-code-explanation
生成的解释是简洁,准确且结构良好的。清楚地解释了每个密钥SQL子句(从,从,加入,加入,在哪里,组,拥有和订购)。此外,描述与SQL中的执行顺序匹配,该说明可以帮助读者逐步遵循查询逻辑。
>解释完全是德语的。 >
在上下文中准确使用了
>
在上下文中准确使用了
>解释避免了过于复杂的术语,并专注于每个子句的功能。这使初学者很容易理解查询的工作原理。
此测试证明了Llama 3.3:
在本教程中,您学会了:
如何将拥抱的面部模型集成到简化的应用程序中。
>如何使用Llama 3.3 API解释代码片段。
以上是Llama 3.3:演示项目的分步教程的详细内容。更多信息请关注PHP中文网其他相关文章!





















