AI驱动的推理模型在2025年席卷世界!随着DeepSeek-R1和O3-Mini的推出,我们在AI聊天机器人中看到了前所未有的逻辑推理能力。在本文中,我们将通过其API访问这些模型,并评估其逻辑推理技能,以找出O3-Mini是否可以替换DeepSeek-R1。我们将比较它们在标准基准和现实世界中的性能,例如解决逻辑难题,甚至建立俄罗斯方块游戏!因此,搭扣并加入骑行。
目录的
>
- deepseek-r1 vs o3-mini:逻辑推理基准
- >
- deepSeek-r1 vs o3-mini:api定价比较
-
任务1:构建俄罗斯四角
- 任务2:分析关系不等式
- 任务3:数学
逻辑推理比较比较摘要
deepseek-r1 vs o3-mini:逻辑推理基准
DeepSeek-R1和O3-Mini为结构化思维和推论提供了独特的方法,使它们适合各种复杂的解决问题的任务。在我们谈论他们的基准性能之前,让我们首先偷偷窥视这些模型的架构。
O3米尼是Openai最先进的推理模型。它使用密集的变压器体系结构,使用所有模型参数处理每个令牌,以实现强大的性能,但资源很高。相比之下,DeepSeek最合乎逻辑的模型R1采用了Experts(MOE)框架的混合物,仅激活每个输入的参数子集,以提高效率。这使DeepSeek-R1在保持稳定的性能的同时更具可扩展性和计算优化。
 了解更多:Openai的O3米尼比DeepSeek-R1更好?
了解更多:Openai的O3米尼比DeepSeek-R1更好?
现在,我们需要看到的是这些模型在逻辑推理任务中的表现如何。首先,让我们看一下他们在LiveBench基准测试中的表现。>
来源:livebench.ai
>基准结果表明,除了数学外,Openai的O3-Mini几乎在几乎所有方面都优于DeepSeek-R1。与DeepSeek的71.38相比,全球平均得分为73.94,O3-Mini的总体表现稍强。它在推理方面尤其出色,与DeepSeek的83.17相比,达到89.58,反映了出色的分析和解决问题的能力。
也阅读:Google Gemini 2.0 Pro vs DeepSeek-R1:编码更好?
deepSeek-r1 vs o3-mini:API定价比较
>由于我们正在通过其API测试这些模型,让我们看看这些模型的成本。>
| Model |
Context length |
Input Price |
Cached Input Price |
Output Price |
| o3-mini |
200k |
.10/M tokens |
.55/M tokens |
.40/M tokens |
| deepseek-chat |
64k |
.27/M tokens |
.07/M tokens |
.10/M tokens |
| deepseek-reasoner |
64k |
.55/M tokens |
.14/M tokens |
.19/M tokens |
在桌子上可以看出,Openai的O3-Mini在API成本方面几乎是DeepSeek R1的两倍。它收费为每百万个代币,输入为每百万个代币,产出$ 4.40,而DeepSeek R1的投入率更高的价格为每百万个代币的成本效益更高,输入为2.19美元,而产出的价格为2.19美元,使其成为大型应用程序的预算友好选择。
来源:DeepSeek-r1 | O3-Mini
如何通过API 访问DeepSeek-R1和O3-Mini
>在进行动手绩效比较之前,让我们学习如何使用API访问DeepSeek-R1和O3-Mini。
您为此所要做的就是导入必要的库和API键:>
from openai import OpenAI
from IPython.display import display, Markdown
import time
登录后复制
登录后复制
登录后复制
with open("path_of_api_key") as file:
openai_api_key = file.read().strip()登录后复制
登录后复制
with open("path_of_api_key") as file:
deepseek_api = file.read().strip()登录后复制
>现在我们已经获得了API访问权限,让我们根据其逻辑推理能力比较DeepSeek-R1和O3-Mini。为此,我们将在模型中给出相同的提示,并根据这些指标评估它们的响应:
模型花费的时间生成响应的时间
生成的响应的质量,
- 产生响应的成本。
>
-
然后,我们将根据其性能为每个任务的模型0或1分为0或1。因此,让我们尝试一下任务,看看谁在DeepSeek-R1与O3-Mini推理之战中成为赢家!
任务1:构建俄罗斯方块游戏-
此任务要求模型使用Python实现功能齐全的Tetris游戏,有效地管理游戏逻辑,零件移动,碰撞检测和渲染,而无需依赖外部游戏引擎。
提示:
>
“为此问题编写Python代码:为Tetris Game生成Python代码”
>输入到DeepSeek-R1 API>
DeepSeek-R1
>
INPUT_COST_CACHE_HIT = 0.14 / 1_000_000 # <pre class="brush:php;toolbar:false">task1_start_time = time.time()
client = OpenAI(api_key=api_key)
messages = messages=[
{
"role": "system",
"content": """You are a professional Programmer with a large experience ."""
},
{
"role": "user",
"content": """write a python code for this problem: generate a python code for Tetris game.
"""
}
]
# Use a compatible encoding (cl100k_base is the best option for new OpenAI models)
encoding = tiktoken.get_encoding("cl100k_base")
# Calculate token counts
input_tokens = sum(len(encoding.encode(msg["content"])) for msg in messages)
completion = client.chat.completions.create(
model="o3-mini-2025-01-31",
messages=messages
)
output_tokens = len(encoding.encode(completion.choices[0].message.content))
task1_end_time = time.time()
input_cost_per_1k = 0.0011 # Example: <pre class="brush:php;toolbar:false">INPUT_COST_CACHE_HIT = 0.14 / 1_000_000 # <pre class="brush:php;toolbar:false">task2_start_time = time.time()
client = OpenAI(api_key=api_key)
messages = [
{
"role": "system",
"content": """You are an expert in solving Reasoning Problems. Please solve the given problem"""
},
{
"role": "user",
"content": """In the following question, assuming the given statements to be true, find which of the conclusions among given conclusions is/are definitely true and then give your answers accordingly.
Statements: H > F ≤ O ≤ L; F ≥ V < D
Conclusions:
I. L ≥ V
II. O > D
The options are:
A. Only I is true
B. Only II is true
C. Both I and II are true
D. Either I or II is true
E. Neither I nor II is true
"""
}
]
# Use a compatible encoding (cl100k_base is the best option for new OpenAI models)
encoding = tiktoken.get_encoding("cl100k_base")
# Calculate token counts
input_tokens = sum(len(encoding.encode(msg["content"])) for msg in messages)
completion = client.chat.completions.create(
model="o3-mini-2025-01-31",
messages=messages
)
output_tokens = len(encoding.encode(completion.choices[0].message.content))
task2_end_time = time.time()
input_cost_per_1k = 0.0011 # Example: <pre class="brush:php;toolbar:false">INPUT_COST_CACHE_HIT = 0.14 / 1_000_000 # <pre class="brush:php;toolbar:false">task3_start_time = time.time()
client = OpenAI(api_key=api_key)
messages = [
{
"role": "system",
"content": """You are a Expert in solving Reasoning Problems. Please solve the given problem"""
},
{
"role": "user",
"content": """
Study the given matrix carefully and select the number from among the given options that can replace the question mark (?) in it.
__________________
| 7 | 13 | 174|
| 9 | 25 | 104|
| 11 | 30 | ? |
|_____|_____|____|
The options are:
A 335
B 129
C 431
D 100
Please mention your approch that you have taken at each step
"""
}
]
# Use a compatible encoding (cl100k_base is the best option for new OpenAI models)
encoding = tiktoken.get_encoding("cl100k_base")
# Calculate token counts
input_tokens = sum(len(encoding.encode(msg["content"])) for msg in messages)
completion = client.chat.completions.create(
model="o3-mini-2025-01-31",
messages=messages
)
output_tokens = len(encoding.encode(completion.choices[0].message.content))
task3_end_time = time.time()
input_cost_per_1k = 0.0011 # Example: .005 per 1,000 input tokens
output_cost_per_1k = 0.0044 # Example: .015 per 1,000 output tokens
# Calculate cost
input_cost = (input_tokens / 1000) * input_cost_per_1k
output_cost = (output_tokens / 1000) * output_cost_per_1k
total_cost = input_cost + output_cost
# Print results
print(completion.choices[0].message)
print("----------------=Total Time Taken for task 3:----------------- ", task3_end_time - task3_start_time)
print(f"Input Tokens: {input_tokens}, Output Tokens: {output_tokens}")
print(f"Estimated Cost: ${total_cost:.6f}")
# Display result
from IPython.display import Markdown
display(Markdown(completion.choices[0].message.content))登录后复制
>
>输出令牌成本:
>输入令牌:28 |输出令牌:3323 |估计成本:$ 0.0073
>代码输出
>输入到O3-Mini API
>
O3-Mini >
>您可以在这里找到O3-Mini的完整响应。
>
>输出令牌成本:
>输入令牌:28 |输出令牌:3235 |估计成本:$ 0.014265
>代码输出
比较分析
在此任务中,需要模型来生成允许实际游戏玩法的功能性俄罗斯代码。如代码输出视频所示,DeepSeek-R1成功地产生了完全有效的实现。相比之下,尽管O3-Mini的代码看起来良好,但在执行过程中遇到了错误。结果,在这种情况下,DeepSeek-R1在这种情况下优于O3 Mini,提供了更可靠和可播放的解决方案。>
>得分:
deepSeek-r1:1 | O3-Mini:0
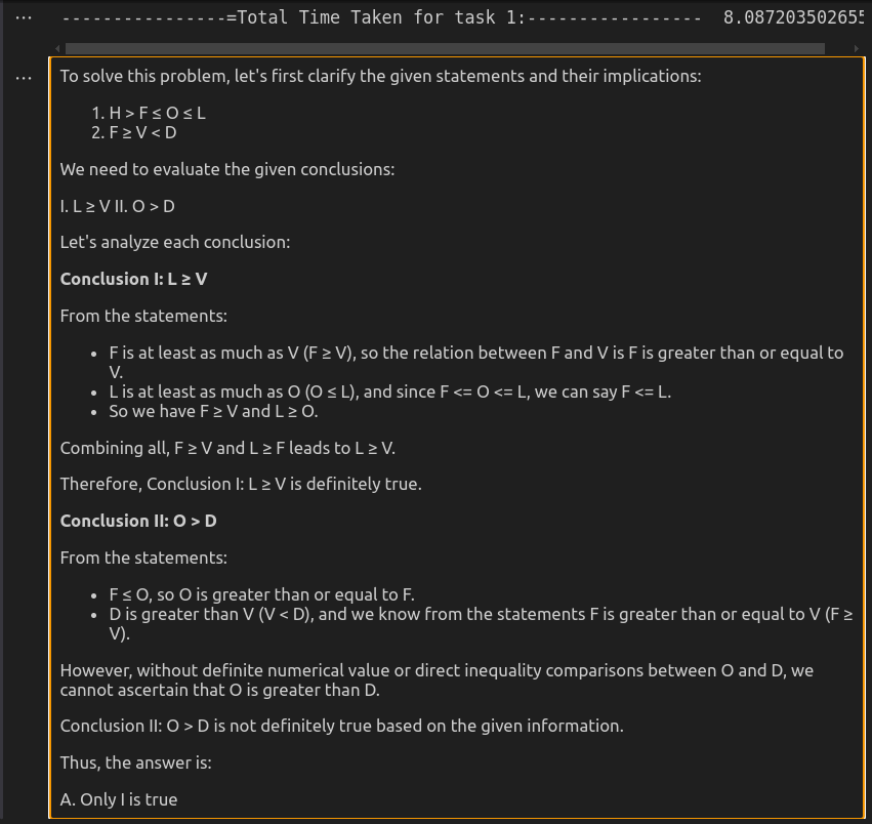
任务2:分析关系不平等
此任务要求模型有效地分析关系不平等而不是依靠基本的分类方法。
>提示:“”在以下问题中,假设给定的陈述为真,在给定的结论中找到了哪个结论是/肯定是正确的,然后相应地给出您的答案。
>>
语句:
h&gt; f≤o≤l; f≥V&lt; D
结论:I。L≥VII。 o&gt; D
选项是:
a。只有我是true
b。只有i是true
>
c。 i和ii都是true
>
d。我或ii是true
>
e。我和ii都不是真实的。
>输入到DeepSeek-R1 API>
from openai import OpenAI
from IPython.display import display, Markdown
import time
登录后复制
登录后复制
登录后复制
>输出令牌成本:
>输入令牌:136 |输出令牌:352 |估计成本:$ 0.000004
DeepSeek-R1
>
>输入到O3-Mini API>
with open("path_of_api_key") as file:
openai_api_key = file.read().strip()登录后复制
登录后复制
>输入令牌:135 |输出令牌:423 |估计成本:$ 0.002010
O3-Mini >
比较分析
O3米尼提供了最有效的解决方案,提供了明显而准确的响应,在大得多的时间内提供了响应。它在确保逻辑健全的同时保持清晰度,使其非常适合快速推理任务。 DeepSeek-r1虽然同样正确,但要慢得多且详细。它详细的逻辑关系分解增强了解释性,但对于直接评估可能会感到过分。尽管这两种模型得出了同样的结论,但O3-Mini的速度和直接方法使其成为实际使用的更好选择。
分数: deepseek-r1:0 | O3-Mini:1
>任务3:数学中的逻辑推理
此任务挑战模型识别数值模式,这可能涉及算术操作,乘法或数学规则的组合。该模型必须采用结构化的方法来有效地推断出隐藏的逻辑。
提示:>“>仔细研究给定的矩阵,然后从给定选项中选择可以替换问号(?)的数字。
>
____________
| 7 | 13 | 174 |
| 9 | 25 | 104 |
| 11 | 30 | ? |
| _____ | ____ | ___ |
选项是:
a 335
b 129
c 431
d 100
请提及您在每个步骤中采取的方法。
>输入到DeepSeek-R1 API>
>输出令牌成本:
>输入令牌:134 |输出令牌:274 |估计成本:$ 0.000003from openai import OpenAI
from IPython.display import display, Markdown
import time
登录后复制
登录后复制
登录后复制
>
>输入到O3-Mini API
>
>输出令牌成本:
>输入令牌:134 |输出令牌:736 |估计成本:$ 0.003386
O3-Mini with open("path_of_api_key") as file:
openai_api_key = file.read().strip() 输出>>>
比较分析
在这里,每一行遵循的模式为:
(第一个数字)^3-(第二个数字)^2 = 3rd number
应用此模式:
第1:7^3 - 13^2 = 343 - 169 = 174
第2行2:9^3 - 25^2 = 729 - 625 = 104
>
第3行:11^3 - 30^2 = 1331 - 900 = 431
因此,正确的答案是431。
> DeepSeek-R1正确识别并应用了此模式,从而导致正确的答案。它的结构化方法可确保准确性,尽管计算结果需要大大时间。另一方面,O3-Mini无法建立一致的模式。它尝试了多个操作,例如乘法,加法和指示,但没有得出确定的答案。这会导致不清楚的响应。总体而言,DeepSeek-R1在逻辑推理和准确性方面优于O3-Mini,而O3米尼由于其不一致和无效的方法而挣扎。
- 得分:
deepseek-r1:1 | O3-Mini:0 -
最终分数:DeepSeek-r1:2 | O3-Mini:1
逻辑推理比较摘要
| Task No. |
Task Type |
Model |
Performance |
Time Taken (seconds) |
Cost |
| 1 |
Code Generation |
DeepSeek-R1 |
✅ Working Code |
606.45 |
.0073 |
|
|
o3-mini |
❌ Non-working Code |
99.73 |
.014265 |
| 2 |
Alphabetical Reasoning |
DeepSeek-R1 |
✅ Correct |
74.28 |
.000004 |
|
|
o3-mini |
✅ Correct |
8.08 |
.002010 |
| 3 |
Mathematical Reasoning |
DeepSeek-R1 |
✅ Correct |
450.53 |
.000003 |
|
|
o3-mini |
❌ Wrong Answer |
12.37 |
.003386 |
结论
正如我们在此比较中看到的那样,DeepSeek-R1和O3-Mini都表现出满足不同需求的独特优势。 DeepSeek-R1在精确驱动的任务中擅长,尤其是在数学推理和复杂的代码生成中,使其成为需要逻辑深度和正确性的应用程序的有力候选者。但是,一个重要的缺点是其响应时间较慢,部分原因是持续的服务器维护问题影响了其可访问性。另一方面,O3-Mini提供的响应时间明显更快,但是其产生不正确结果的趋势限制了其对高风险推理任务的可靠性。
该分析强调了语言模型中速度和准确性之间的权衡。虽然O3-Mini可能对快速,低风险的应用程序有用,但DeepSeek-R1是解决推理密集型任务的优越选择,只要解决了其潜伏期问题。随着AI模型的不断发展,在性能效率和正确性之间达到平衡将是优化各个领域的AI驱动工作流程的关键。
也请阅读:Openai的O3-Mini可以在编码中击败Claude Sonnet 3.5?
常见问题
> Q1。 DeepSeek-R1和O3-Mini之间的主要区别是什么? DeepSeek-R1在数学推理和复杂的代码生成方面表现出色,非常适合需要逻辑深度和准确性的应用。另一方面,O3-Mini的速度明显更快,但通常会牺牲准确性,导致偶尔出现不正确的输出。对于编码任务,DeepSeek-R1比O3-Mini好吗? DeepSeek-r1是编码和推理密集型任务的更好选择,因为它具有出色的精度和处理复杂逻辑的能力。虽然O3-Mini提供了更快的响应,但它可能会产生错误,从而使其对高风险编程任务的可靠性降低。
Q3。 O3-Mini是否适用于现实世界应用? O3-Mini最适合低风险,速度依赖的应用程序,例如聊天机器人,休闲文本生成和交互式AI体验。但是,对于需要高精度的任务,DeepSeek-R1是首选的选项。哪种模型更适合推理和解决问题 - DeepSeek-R1或O3-Mini? DeepSeek-R1具有出色的逻辑推理和解决问题的能力,使其成为数学计算,编程援助和科学查询的强大选择。 O3-Mini在复杂的解决问题的方案中提供了快速但有时不一致的响应。>
以上是O3-Mini可以替换DeepSeek-R1进行逻辑推理吗?的详细内容。更多信息请关注PHP中文网其他相关文章!

 了解更多:Openai的O3米尼比DeepSeek-R1更好?
了解更多:Openai的O3米尼比DeepSeek-R1更好?

 >代码输出
>代码输出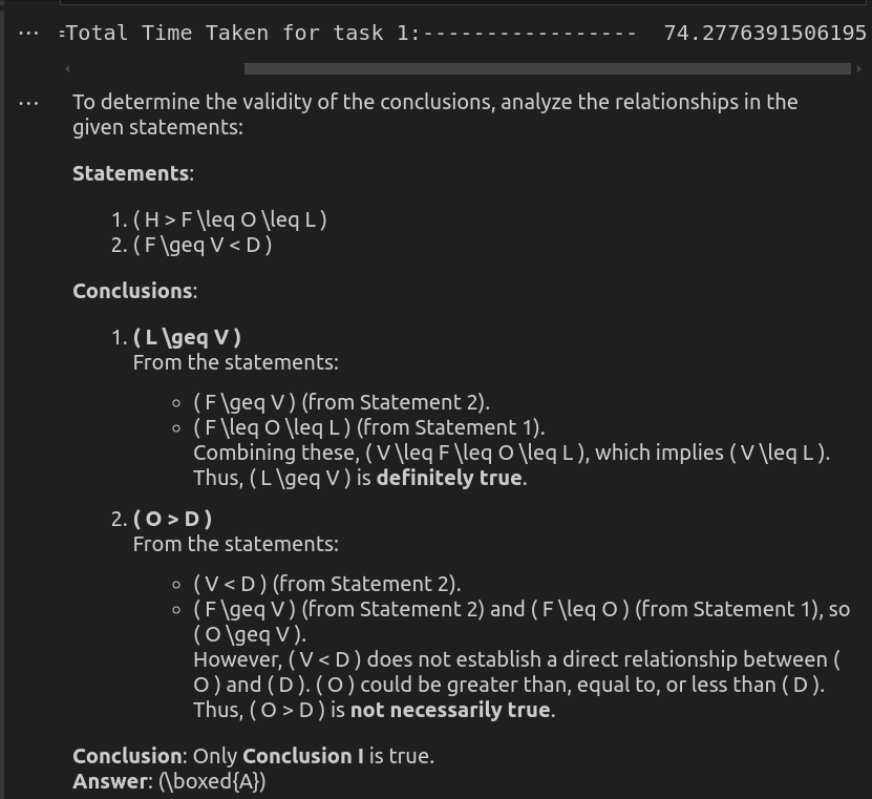




 (第一个数字)^3-(第二个数字)^2 = 3rd number
(第一个数字)^3-(第二个数字)^2 = 3rd number




















