

微调骆驼3.1用于文本分类

>本教程展示了精神健康情感分析的Llama 3.1-8B-IT模型。 我们将自定义模型以预测文本数据中的患者心理健康状况,将适配器与基本模型合并,并在拥抱面枢纽中部署完整的模型。 至关重要的是,请记住,在医疗保健中使用AI时,道德考虑是至关重要的。此示例仅用于说明目的。 >我们将使用Kaggle,使用Transformers库进行推理以及微调过程本身来介绍访问Llama 3.1型号。 先前对LLM微调的理解(请参阅我们的“微调LLMS介绍性指南”)是有益的。
>由作者
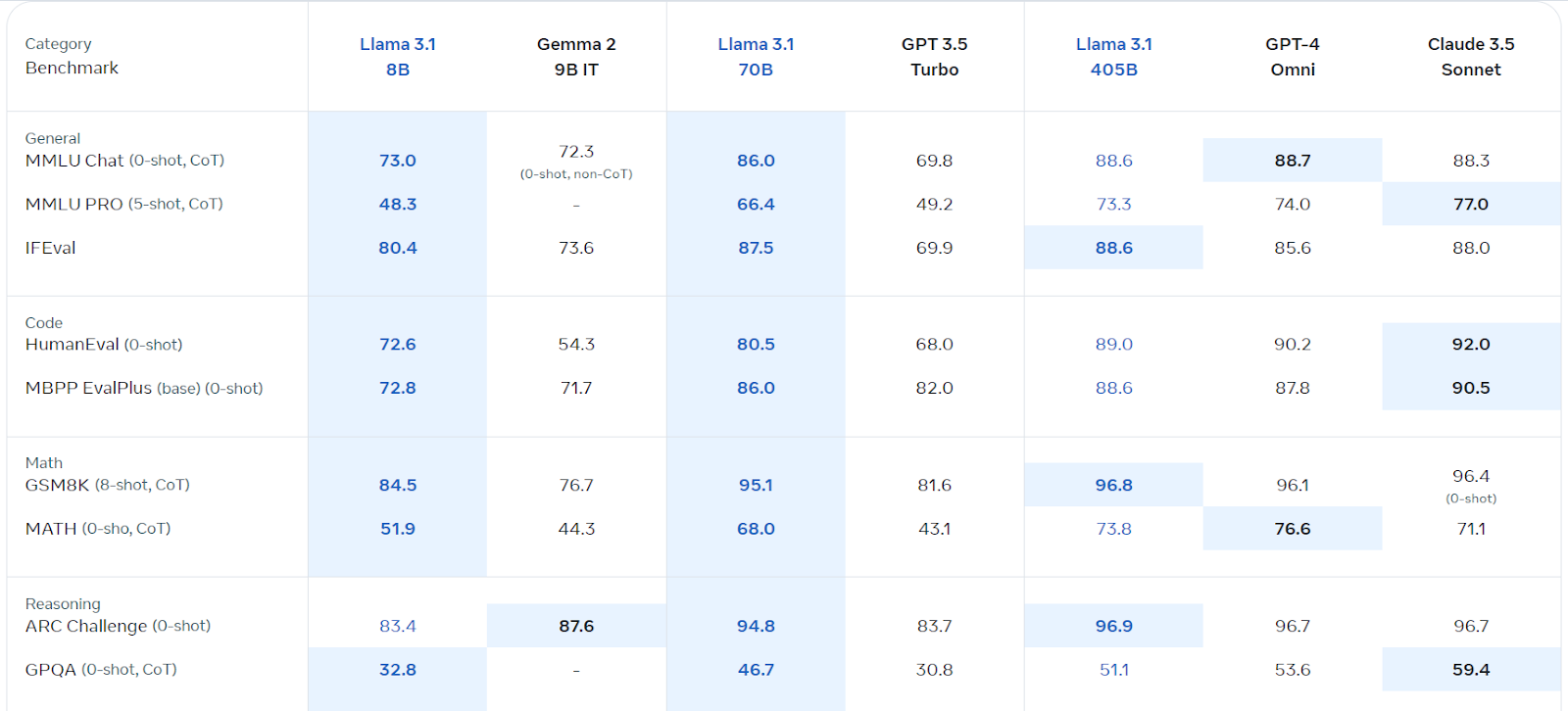
理解Llama 3.1
来源:Llama 3.1(Meta.com)
>
我们将利用Kaggle的免费GPU/TPU。 请按照以下步骤:
>在meta.com上注册(使用您的kaggle电子邮件)。>
>访问Llama 3.1 Kaggle存储库和请求模型访问。
安装必要的软件包(
)。- 加载模型和令牌:
- 创建提示并运行推断:
-
%pip install -U transformers accelerate - 精神健康分类
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
import torch
base_model = "/kaggle/input/llama-3.1/transformers/8b-instruct/1"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(base_model, return_dict=True, low_cpu_mem_usage=True, torch_dtype=torch.float16, device_map="auto", trust_remote_code=True)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, torch_dtype=torch.float16, device_map="auto")messages = [{"role": "user", "content": "What is the tallest building in the world?"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=120, do_sample=True)
print(outputs[0]["generated_text"])>使用Llama 3.1启动新的Kaggle笔记本,安装必需的软件包( ,
,
,,,
,- ),并添加“心理健康的情感分析”数据集。配置权重和偏见(使用您的API键)。
-
数据处理:加载数据集,清洁它(删除模棱两可的类别:“自杀”,“压力”,“人格障碍”),洗牌并分成培训,评估和测试集(使用3000个样本提高效率)。 创建提示并入语句和标签。
> -
模型加载:使用4位量化的记忆效率,加载Llama-3.1-8b-Insruct模型。加载令牌器并设置垫子令牌ID。
-
>>预先调整评估:创建功能以预测标签和评估模型性能(准确性,分类报告,混淆矩阵)。 在微调之前评估模型的基线性能。
-
微调:使用适当的参数配置lora。设置培训论点(根据您的环境根据需要进行调整)。使用
SFTTrainer训练模型。使用权重和偏见监控进度。 -
> 在调查后评估:
在微调后重新评估模型的性能。 -
合并并保存:
将微调适配器与基本模型合并。测试合并模型。保存并将最终型号和令牌推到拥抱的脸部集线器上。PeftModel.from_pretrained()在新的kaggle笔记本中,使用model.merge_and_unload()和 >
/kaggle/input/...记住将占位符(如
以上是微调骆驼3.1用于文本分类的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 开始使用Meta Llama 3.2 -Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
开始使用Meta Llama 3.2 -Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta的Llama 3.2:多模式和移动AI的飞跃 Meta最近公布了Llama 3.2,这是AI的重大进步,具有强大的视觉功能和针对移动设备优化的轻量级文本模型。 以成功为基础
 10个生成AI编码扩展,在VS代码中,您必须探索
Apr 13, 2025 am 01:14 AM
10个生成AI编码扩展,在VS代码中,您必须探索
Apr 13, 2025 am 01:14 AM
嘿,编码忍者!您当天计划哪些与编码有关的任务?在您进一步研究此博客之前,我希望您考虑所有与编码相关的困境,这是将其列出的。 完毕? - 让&#8217
 AV字节:Meta' llama 3.2,Google的双子座1.5等
Apr 11, 2025 pm 12:01 PM
AV字节:Meta' llama 3.2,Google的双子座1.5等
Apr 11, 2025 pm 12:01 PM
本周的AI景观:进步,道德考虑和监管辩论的旋风。 OpenAI,Google,Meta和Microsoft等主要参与者已经释放了一系列更新,从开创性的新车型到LE的关键转变
 向员工出售AI策略:Shopify首席执行官的宣言
Apr 10, 2025 am 11:19 AM
向员工出售AI策略:Shopify首席执行官的宣言
Apr 10, 2025 am 11:19 AM
Shopify首席执行官TobiLütke最近的备忘录大胆地宣布AI对每位员工的基本期望是公司内部的重大文化转变。 这不是短暂的趋势。这是整合到P中的新操作范式
 视觉语言模型(VLMS)的综合指南
Apr 12, 2025 am 11:58 AM
视觉语言模型(VLMS)的综合指南
Apr 12, 2025 am 11:58 AM
介绍 想象一下,穿过美术馆,周围是生动的绘画和雕塑。现在,如果您可以向每一部分提出一个问题并获得有意义的答案,该怎么办?您可能会问:“您在讲什么故事?
 GPT-4O vs OpenAI O1:新的Openai模型值得炒作吗?
Apr 13, 2025 am 10:18 AM
GPT-4O vs OpenAI O1:新的Openai模型值得炒作吗?
Apr 13, 2025 am 10:18 AM
介绍 Openai已根据备受期待的“草莓”建筑发布了其新模型。这种称为O1的创新模型增强了推理能力,使其可以通过问题进行思考
 阅读AI索引2025:AI是您的朋友,敌人还是副驾驶?
Apr 11, 2025 pm 12:13 PM
阅读AI索引2025:AI是您的朋友,敌人还是副驾驶?
Apr 11, 2025 pm 12:13 PM
斯坦福大学以人为本人工智能研究所发布的《2025年人工智能指数报告》对正在进行的人工智能革命进行了很好的概述。让我们用四个简单的概念来解读它:认知(了解正在发生的事情)、欣赏(看到好处)、接纳(面对挑战)和责任(弄清我们的责任)。 认知:人工智能无处不在,并且发展迅速 我们需要敏锐地意识到人工智能发展和传播的速度有多快。人工智能系统正在不断改进,在数学和复杂思维测试中取得了优异的成绩,而就在一年前,它们还在这些测试中惨败。想象一下,人工智能解决复杂的编码问题或研究生水平的科学问题——自2023年
 3种运行Llama 3.2的方法-Analytics Vidhya
Apr 11, 2025 am 11:56 AM
3种运行Llama 3.2的方法-Analytics Vidhya
Apr 11, 2025 am 11:56 AM
Meta's Llama 3.2:多式联运AI强力 Meta的最新多模式模型Llama 3.2代表了AI的重大进步,具有增强的语言理解力,提高的准确性和出色的文本生成能力。 它的能力t
