为清晰度和准确性编辑,该数据扫描社区教程探讨了图像文本基础模型,重点介绍了创新的对比字幕(COCA)模型。 可口可乐独特地结合了对比和生成性学习目标,将诸如剪辑和simvlm之类的模型的优势整合到单个体系结构中。

基础模型:深水潜水
>
在大规模数据集上预先训练的基础模型适用于各种下游任务。 尽管NLP的基础模型(GPT,BERT)激增,但视觉和视觉模型仍在不断发展。研究探索了三种主要方法:单名模型,具有对比损失的图像文本编码器以及具有生成目标的编码器模型。 每种方法都有局限性。
密钥术语:
-
基础模型:预先训练的模型适用于各种应用。
- 对比损失:比较相似和不同输入对的损失函数。
- >交叉模式相互作用:不同数据类型之间的相互作用(例如,图像和文本)。
- > encoder-decoder体系结构: 神经网络处理输入和生成输出。
零射击学习:- 在看不见的数据类别上预测。
在
> simvlm:- 一个简单的视觉语言模型。
- 模型比较:
单个编码器模型:
在视觉任务上出色,但由于依赖人类注释而与视力语言任务斗争。>
image-Text双编码模型(剪辑,对齐):
非常适合零摄像分类和图像检索,但在需要融合的image-text表示的任务中有限(例如,视觉询问)。
- 生成模型(SIMVLM):使用跨模式相互作用进行关节图像文本表示,适用于VQA和图像字幕。
- 可口可乐:桥接gap
- 可口架构:
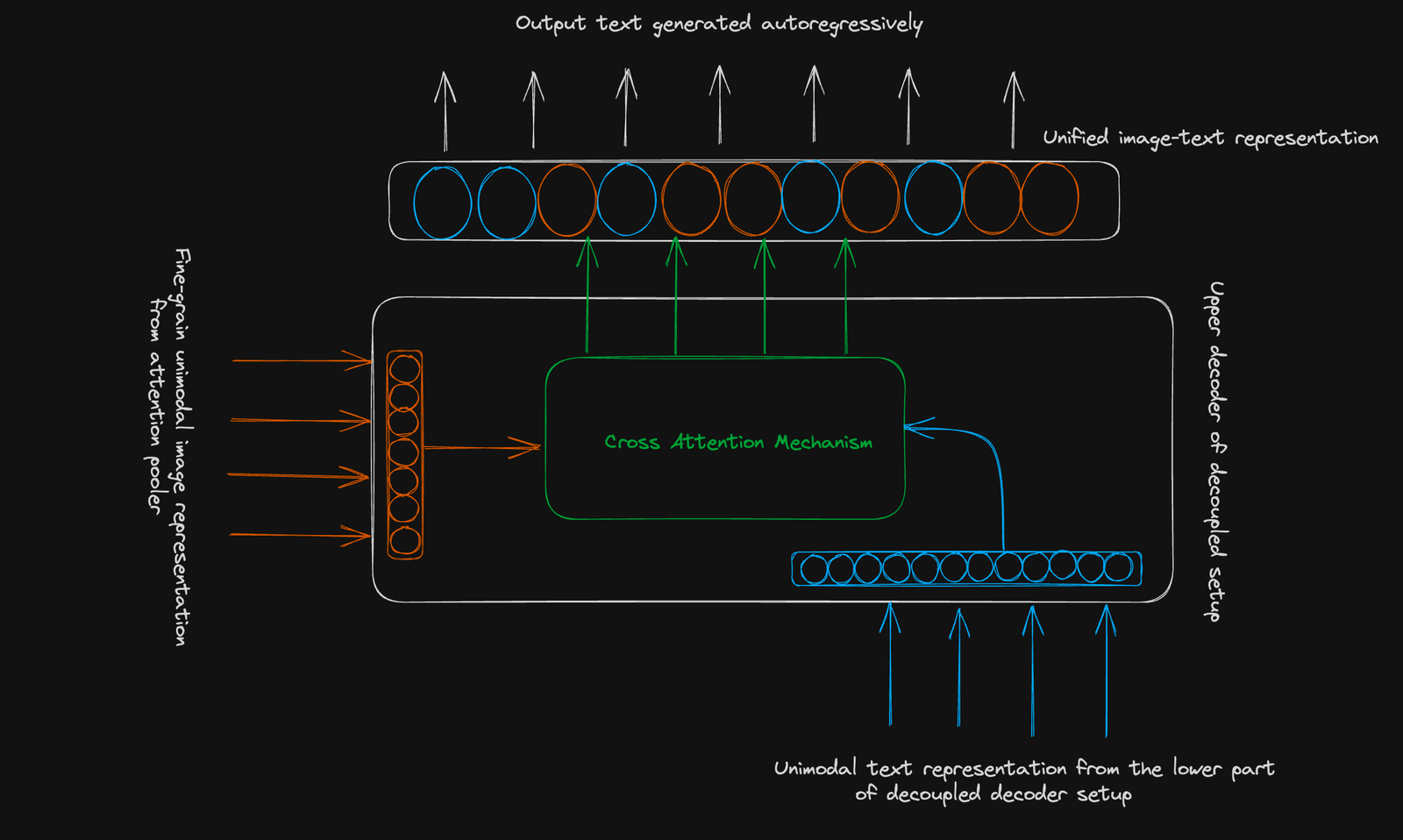
可口可使用的是标准的编码器解码器结构。 它的创新在于A
脱钩的解码器:>
-
较低解码器:生成一个单峰文本表示对比度学习(使用[cls]令牌)。
- 上的解码器:生成用于生成学习的多模式图像文本表示。 两个解码器都使用因果掩蔽。
对比目标:学会在共享向量空间中群集相关的图像文本对并分开无关的图像对。 使用单个合并的图像嵌入。
生成目标:使用细颗粒的图像表示(256维序列)和交叉模式的注意来预测文本自动加注。
结论:
>可可代表图像文本基础模型中的显着进步。其组合方法可以增强各种任务的性能,为下游应用程序提供多功能工具。 为了进一步了解先进的深度学习概念,请考虑Datacamp使用KERAS课程的高级深度学习。
进一步读取:
>从自然语言监督中学习可转移的视觉模型
>图像文本预训练与对比字幕
-
以上是可口可乐:对比字幕是图像文本基础模型在视觉上解释的详细内容。更多信息请关注PHP中文网其他相关文章!