
深度学习GPU基准测试彻底改变了我们解决复杂问题的方式,从图像识别到自然语言处理。但是,在培训这些模型时,通常依赖于高性能的GPU,将它们有效地部署在资源受限的环境中,例如边缘设备或有限的硬件系统提出了独特的挑战。 CPU,广泛可用且具有成本效益,通常是在这种情况下推断的骨干。但是,我们如何确保部署在CPU上的模型在不损害准确性的情况下提供最佳性能?
本文深入研究了对CPU的深度学习模型推断的基准测试,重点介绍了三个关键指标:延迟,CPU利用率和内存利用率。使用垃圾邮件分类示例,我们探讨了Pytorch,Tensorflow,Jax和ONNX运行时手柄推理工作负载等流行框架。最后,您将对如何衡量性能,优化部署并为资源受限环境中的基于CPU推断的推理选择正确的工具和框架有清晰的了解。
影响:最佳推理执行可以节省大量资金,并为其他工作量提供免费资源。
本文作为数据科学博客马拉松的一部分发表。
推理速度对于用户体验和机器学习应用程序的运营效率至关重要。运行时优化在通过简化执行来增强它方面起着关键作用。使用诸如ONNX运行时的硬件加速库会利用针对特定体系结构的优化,减少延迟(每次推理时间)。
此外,轻巧的模型格式,例如ONNX最小化开销,从而更快地加载和执行。优化的运行时间利用并行处理来在可用的CPU内核上分发计算并改善内存管理,从而确保更好的性能,尤其是在资源有限的系统上。这种方法使模型在保持准确性的同时更快,更有效。
为了评估模型的性能,我们专注于三个关键指标:
为了保持这项基准研究的重点和实用,我们做出了以下假设并设定了一些界限:
这些假设确保基准与使用资源受限硬件的开发人员和团队相关,或者需要可预测的性能而没有分布式系统的复杂性。
我们将探讨用于基准和优化CPU的深度学习模型推断的基本工具和框架,从而提供了对其能力的见解,以在资源受限的环境中有效执行。
我们正在利用github codespace(虚拟机),以下配置:
所使用的包装的版本如下,此主要包括五个深度学习推理库:Tensorflow,Pytorch,Onnx Runtime,Jax和OpenVino:
!pip安装numpy == 1.26.4 !pip安装火炬== 2.2.2 !PIP安装TensorFlow == 2.16.2 !pip安装onnx == 1.17.0 !pip安装onnxRuntime == 1.17.0! !pip安装jaxlib == 0.4.30 !PIP安装OpenVino == 2024.6.0 !pip安装matplotlib == 3.9.3 !pip安装matplotlib:3.4.3 !PIP安装枕头:8.3.2 !pip安装psutil:5.8.0
由于模型推断包括在网络权重和输入数据之间执行一些矩阵操作,因此它不需要模型培训或数据集。对于我们的示例,我们模拟了标准分类用例。这模拟了常见的二进制分类任务,例如垃圾邮件检测和贷款申请决策(批准或拒绝)。这些问题的二进制性质使它们是比较不同框架模型性能的理想选择。该设置反映了现实世界中的系统,但使我们能够将重点放在跨框架的推理性能上,而无需大型数据集或预训练的模型。
样本任务涉及根据一组输入功能预测给定样本是垃圾邮件(贷款批准还是拒绝)。这个二进制分类问题在计算上是有效的,可以重点分析推理性能,而没有多类分类任务的复杂性。
为了模拟现实世界电子邮件数据,我们生成了随机输入。这些嵌入模仿垃圾邮件过滤器可能处理的数据类型,但避免了对外部数据集的需求。该模拟输入数据允许在不依赖任何特定外部数据集的情况下进行基准测试,这是测试模型推理时间,内存使用情况和CPU性能的理想选择。另外,您可以使用图像分类,NLP任务或任何其他深度学习任务来执行此基准测试过程。
模型选择是基准测试的关键步骤,因为它直接影响了从分析过程中获得的推理性能和见解。如上一节所述,对于这项基准测试研究,我们选择了标准分类用例,其中涉及确定给定的电子邮件是否是垃圾邮件。此任务是一个直接的两类分类问题,它在计算上有效,但为跨框架进行比较提供了有意义的结果。
分类任务的模型是为二进制分类设计的馈电神经网络(FNN)(垃圾邮件与垃圾邮件)。它由以下层组成:
self.fc1 = torch.nn.linear(200,128)
self.fc2 = torch.nn.linear(128,64) self.fc3 = torch.nn.linear(64,32) self.fc4 = torch.nn.linear(32,16) self.fc5 = torch.nn.linear(16,8) self.fc6 = torch.nn.linear(8,1)
self.sigmoid = torch.nn.sigmoid()
该模型对于分类任务很简单,但有效。
在我们的用例中用于基准测试的模型体系结构图如下所示:
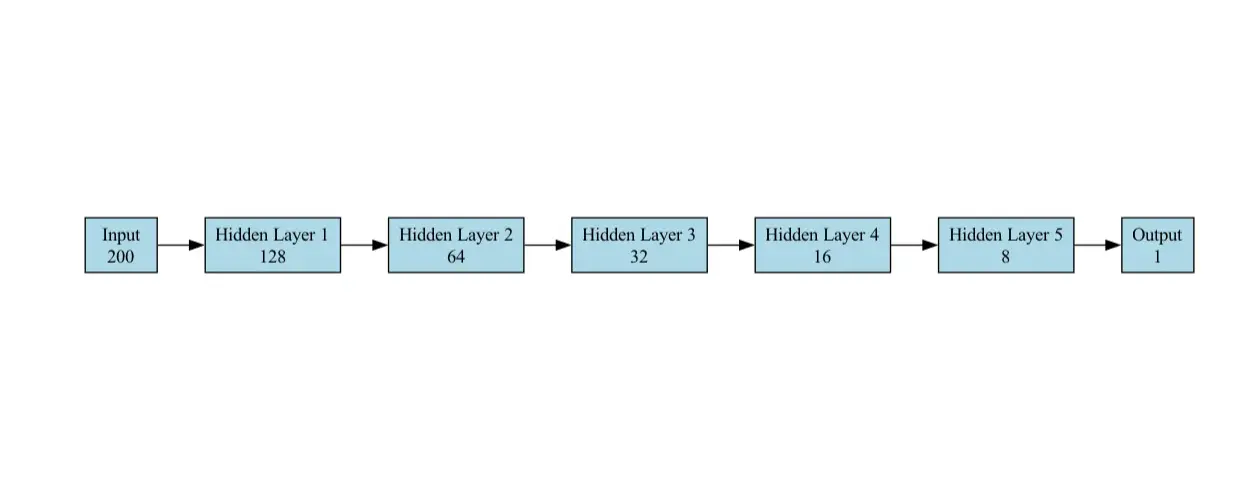
该工作流旨在比较使用分类任务的多个深度学习框架(Tensorflow,Pytorch,Onnx,Jax和OpenVino)的推理性能。该任务涉及使用随机生成的输入数据并根据每个框架进行基准测试以测量预测所花费的平均时间。
为了开始基准测试深度学习模型,我们首先需要导入实现无缝集成和性能评估的基本Python软件包。
进口时间 导入操作系统 导入numpy作为NP 导入火炬 导入TensorFlow作为TF 来自TensorFlow.keras导入输入 导入OnnxRuntime AS Ort 导入matplotlib.pyplot作为PLT 从PIL导入图像 导入psutil 导入JAX 导入jax.numpy作为jnp 来自OpenVino.runtime Import Core 导入CSV
os.environ [“ cuda_visible_devices”] =“ -1”#disable gpu os.environ [“ tf_cpp_min_log_level”] =“ 3” #suppress tensorflow log
在此步骤中,我们随机生成用于垃圾邮件分类的输入数据:
我们使用Numpy生成Randome数据,以作为模型的输入功能。
#Generate虚拟数据 input_data = np.random.rand(1000,200).stype(np.float32)
在此步骤中,我们从每个深度学习框架(Tensorflow,Pytorch,Onnx,Jax和OpenVino)定义NetWrok体系结构或设置模型。每个框架都需要一种特定的方法来加载模型并将其设置为推断。
Pytorchmodel类(Torch.nn.Module):
def __init __(自我):
超级(pytorchmodel,self).__ init __()
self.fc1 = torch.nn.linear(200,128)
self.fc2 = torch.nn.linear(128,64)
self.fc3 = torch.nn.linear(64,32)
self.fc4 = torch.nn.linear(32,16)
self.fc5 = torch.nn.linear(16,8)
self.fc6 = torch.nn.linear(8,1)
self.sigmoid = torch.nn.sigmoid()
def向前(self,x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = torch.relu(self.fc3(x))
x = torch.relu(self.fc4(x))
x = torch.relu(self.fc5(x))
x = self.sigmoid(self.fc6(x))
返回x
#创建Pytorch模型
pytorch_model = pytorchmodel()tensorflow_model = tf.keras.Sequeential([[
输入(Shape =(200,)),
tf.keras.layers.dense(128,激活='relu'),
tf.keras.layers.dense(64,activation ='relu'),
tf.keras.layers.dense(32,activation ='relu'),
tf.keras.layers.dense(16,activation ='relu'),
tf.keras.layers.dense(8,activation ='relu'),
tf.keras.layers.dense(1,激活='Sigmoid')
)))
tensorflow_model.compile() def jax_model(x):
x = jax.nn.relu(jnp.dot(x,jnp.ones((200,128)))))))
x = jax.nn.relu(jnp.dot(x,jnp.ones(((128,64))))))))
x = jax.nn.relu(jnp.dot(x,jnp.ones((64,32))))))))
x = jax.nn.relu(jnp.dot(x,jnp.ones((32,16))))))))
x = jax.nn.relu(jnp.dot(x,jnp.ones((16,8))))))
x = jax.nn.sigmoid(jnp.dot(x,jnp.ones((8,1)))))))
返回x #将Pytorch型号转换为ONNX
dummy_input = torch.randn(1,200)
onnx_model_path =“ model.onnx”
TORCH.ONNX.EXPORT(
pytorch_model,
dummy_input,
onnx_model_path,
export_params = true,
opset_version = 11,
input_names = ['input'],
output_names = ['输出'],
dynamic_axes = {'input':{0:'batch_size'},'output':{0:'batch_size'}}}
)
onnx_session = ort.inferencesession(onnx_model_path)#OpenVino模型定义 core = core() OpenVino_model = core.Read_model(model =“ model.onnx”) compiled_model = core.compile_model(openvino_model,device_name =“ cpu”)
该功能通过采用三个参数来执行跨不同框架的基准测试:prection_function,input_data和num_runs。默认情况下,它执行1000次,但可以根据要求增加。
def benchmark_model(prection_function,input_data,num_runs = 1000):
start_time = time.time()
process = psutil.process(os.getPid())
cpu_usage = []
memory_usage = []
对于_范围(num_runs):
preditive_function(input_data)
cpu_usage.append(process.cpu_percent())
memory_usage.append(process.memory_info()。rss)
end_time = time.time()
avg_latency =(end_time -start_time) / num_runs
avg_cpu = np.mean(cpu_usage)
avg_memory = np.Mean(Memory_usage) /(1024 * 1024)#转换为MB
返回avg_latency,avg_cpu,avg_memory现在我们已经加载了模型了,现在该基于每个框架的性能进行基准测试了。基准测试过程对生成的输入数据执行推断。
#基准Pytorch模型
def pytorch_predict(input_data):
pytorch_model(torch.tensor(input_data)))
pytorch_latency,pytorch_cpu,pytorch_memory = benchmark_model(lambda x:pytorch_predict(x),input_data)#基准TensorFlow模型
def tensorflow_predict(input_data):
tensorflow_model(input_data)
tensorflow_latency,tensorflow_cpu,tensorflow_memory = benchmark_model(lambda x:tensorflow_predict(x),input_data) #基准JAX模型
def jax_predict(input_data):
jax_model(jnp.array(input_data))
jax_latency,jax_cpu,jax_memory = benchmark_model(lambda x:jax_predict(x),input_data) #基准ONNX模型
def onnx_predict(input_data):
#批量的过程输入
对于i在范围内(input_data.shape [0]):
single_input = input_data [i:i 1]#提取单输入
onnx_session.run(none,{onnx_session.get_inputs()[0] .name:single_input})
onnx_latency,onnx_cpu,onnx_memory = benchmark_model(lambda x:onnx_predict(x),input_data) #基准OpenVino模型
DEF OPENVINO_PREDICT(INPUT_DATA):
#批量的过程输入
对于i在范围内(input_data.shape [0]):
single_input = input_data [i:i 1]#提取单输入
compiled_model.infer_new_request({0:single_input})
OpenVINO_LATENCY,OPENVINO_CPU,OPENVINO_MEMORY = BENCHMARK_MODEL(LAMBDA X:OPENVINO_PREDICT(X),INPUT_DATA)
在这里,我们讨论了前面提到的深度学习框架的性能基准测试结果。我们将它们进行比较 - 延迟,CPU使用和内存使用情况。我们包含了表格数据和图,以进行快速比较。
| 框架 | 潜伏期(MS) | 相对延迟(与Pytorch) |
| Pytorch | 1.26 | 1.0(基线) |
| 张量 | 6.61 | 〜5.25× |
| JAX | 3.15 | 〜2.50× |
| onnx | 14.75 | 〜11.72× |
| Openvino | 144.84 | 〜115× |
见解:
| 框架 | CPU使用(%) | 相对CPU用法 1 |
| Pytorch | 99.79 | 〜1.00 |
| 张量 | 112.26 | 〜1.13 |
| JAX | 130.03 | 〜1.31 |
| onnx | 99.58 | 〜1.00 |
| Openvino | 99.32 | 1.00(基线) |
见解:
| 框架 | 内存(MB) | 相对内存使用(与Pytorch) |
| Pytorch | 〜959.69 | 1.0(基线) |
| 张量 | 〜969.72 | 〜1.01× |
| JAX | 〜1033.63 | 〜1.08× |
| onnx | 〜1033.82 | 〜1.08× |
| Openvino | 〜1040.80 | 〜1.08–1.09× |
见解:
这是比较深度学习框架表现的情节:

在本文中,我们提出了一个全面的基准工作流程,以评估突出的深度学习框架的推理性能 - Tensorflow,Pytorch,pytorch,Onnx,Jax和OpenVino-使用垃圾邮件分类任务作为参考。通过分析关键指标,例如延迟,CPU使用和记忆消耗,结果突出了框架与其对不同部署方案的适用性之间的权衡。
Pytorch表现出最平衡的性能,在低潜伏期和有效的内存使用方面表现出色,使其非常适合对潜伏期敏感的应用,例如实时预测和建议系统。 TensorFlow提供了一种中间地面解决方案,具有中等程度的资源消耗。 JAX展示了高计算吞吐量,但以增加CPU利用率为代价,这可能是资源受限环境的限制因素。同时,ONNX和OpenVino的潜伏期滞后,OpenVino的性能尤其受到硬件加速度的阻碍。
这些发现强调了将框架选择与部署需求保持一致的重要性。无论是针对速度,资源效率还是特定的硬件进行优化,理解权衡取舍对于在现实世界中的有效模型部署至关重要。
A. Pytorch的动态计算图和有效的执行管道允许低延节推断(1.26 ms),使其适合于推荐系统和实时预测等应用。
Q2。是什么影响了OpenVino在这项研究中的表现?答:OpenVino的优化是为Intel硬件设计的。没有这种加速度,与其他框架相比,它的延迟(144.84 ms)和内存使用情况(1040.8 MB)的竞争力较低。
Q3。如何为资源受限环境选择一个框架?答:对于仅CPU的设置,Pytorch是最有效的。 TensorFlow是适度工作负载的强大替代方法。除非可以接受较高的CPU利用率,否则避免使用JAX之类的框架。
Q4。硬件在框架性能中起什么作用?答:框架性能在很大程度上取决于硬件兼容性。例如,OpenVino在Intel CPU上具有特定于硬件的优化,而Pytorch和Tensorflow则在各种设置中持续执行。
Q5。基准测试结果是否会因复杂模型或任务而有所不同吗?答:是的,这些结果反映了一个简单的二进制分类任务。性能可能会随复杂的架构(例如Resnet或NLP或其他人)等任务而变化,这些框架可能会利用专业的优化。
本文所示的媒体不由Analytics Vidhya拥有,并由作者酌情使用。
以上是深度学习CPU基准的详细内容。更多信息请关注PHP中文网其他相关文章!





















