
专家(MOE)模型的混合物正在通过提高效率和可扩展性来彻底改变大型语言模型(LLM)。这种创新的体系结构将模型分为专门的子网络或“专家”,每个人都接受了特定数据类型或任务的培训。通过仅根据输入激活专家的一个相关子集,MOE模型可显着提高容量,而不会按比例增加计算成本。这种选择性激活优化了资源使用情况,并可以在自然语言处理,计算机视觉和推荐系统等各个领域跨越复杂的任务。本文探讨了MOE模型,其功能,流行示例和Python实施。
本文是数据科学博客马拉松的一部分。
目录:
什么是专家(MOE)的混合物?
MOE模型通过使用多个较小的专业模型而不是单个大型模型来增强机器学习。每个较小的型号都以特定的问题类型出色。 “决策者”(门控机制)为每个任务选择适当的模型,从而提高整体绩效。包括变压器在内的现代深度学习模型使用分层互连的单元(“神经元”)来处理数据并将结果传递到后续层。 MOE通过将复杂的问题分为专业组件(“专家”)来反映这一点,每个组件都可以解决特定方面。
MOE模型的关键优势:
MOE模型包括两个主要部分:专家(专业的较小的神经网络)和一个路由器(基于输入的相关专家)。这种选择性激活提高了效率。
深度学习
在深度学习中,MoE通过分解复杂问题来改善神经网络性能。它使用多个专门研究不同输入数据方面的多个较小的“专家”模型,而不是单个大型模型。门控网络确定每个输入要使用的专家,从而提高效率和有效性。
MOE模型如何运作?
MOE模型如下:
基于MOE的突出模型
MOE模型在AI中越来越重要,因为它们在保持性能的同时有效地缩放了LLM。 Mixtral 8x7b是一个值得注意的例子,使用了稀疏的MOE架构,仅激活每个输入的一部分专家,从而导致效率显着提高。
混合8x7b是仅解码器的变压器。输入令牌嵌入向量中并通过解码器层进行处理。输出是每个位置被一个单词占据的概率,从而实现文本填充和预测。每个解码器层都有一个注意机制(用于上下文信息)和专家(SMOE)部分的稀疏混合物(单独处理每个单词向量)。 SMOE层使用多个层(“专家”),对于每个输入,都会使用最相关的专家输出的加权总和。
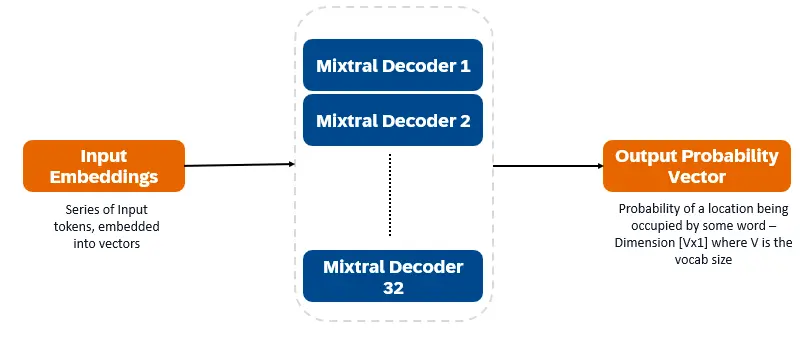
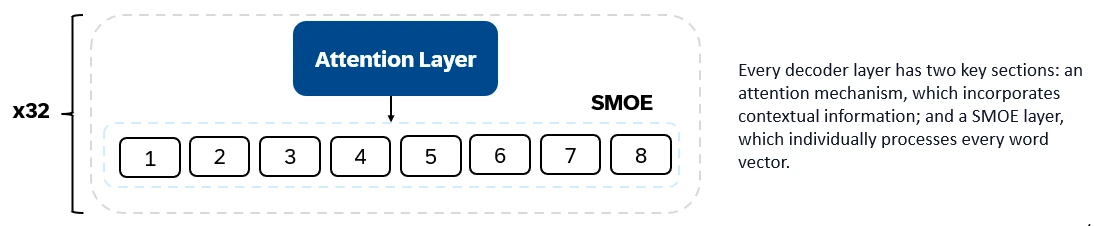
混音8x7b的主要特征:
混音8x7b在文本生成,理解,翻译,摘要等方面表现出色。
DBRX(Databricks)是一种基于变压器的仅解码器的LLM,该LLM使用下一步的预测训练。它使用细粒度的MOE架构(132B总参数,36B活动)。它已在文本和代码数据的12T代币上进行了预培训。 DBRX使用许多较小的专家(16位专家,每个输入选择4个)。
DBRX的主要体系结构特征:
DBRX的主要特征:
DBRX在代码生成,复杂的语言理解和数学推理方面表现出色。
DeepSeek-V2使用精细的专家和共享专家(始终活跃)来整合普遍知识。
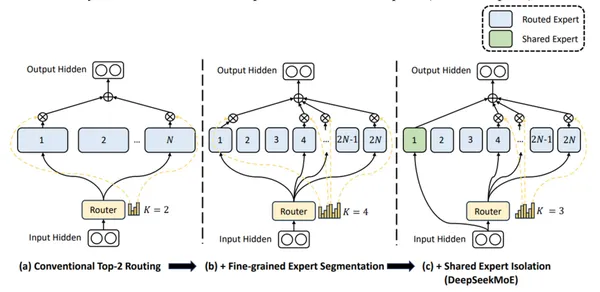
DeepSeek-V2的主要特征:
DeepSeek-V2擅长对话,内容创建和代码生成。
(Python实施和输出比较部分是为了简短的,因为它们是冗长的代码示例和详细的分析。)
常见问题
Q1。专家(MOE)模型的混合物是什么? A. Moe模型使用稀疏体系结构,仅激活每个任务最相关的专家,从而减少了计算资源的使用。
Q2。 MOE型号的权衡是什么? A. MOE模型需要重要的VRAM来存储所有专家,以平衡计算能力和内存要求。
Q3。混合8x7b的主动参数计数是什么? A.混合8x7b具有128亿个活动参数。
Q4。 DBRX与其他MOE模型有何不同? A. DBRX使用较小的专家使用细粒度的MOE方法。
Q5。 DeepSeek-V2有什么区别? A. DeepSeek-V2结合了细粒度和共享的专家,以及较大的参数集和长上下文长度。
结论
MOE模型为深度学习提供了高效的方法。在需要大量VRAM的同时,他们对专家的选择性激活使它们成为处理各个领域的复杂任务的强大工具。混合8x7b,dbrx和DeepSeek-V2代表了该领域的重大进步,每个方面都具有自己的优势和应用。
以上是什么是专家的混合物?的详细内容。更多信息请关注PHP中文网其他相关文章!





















