
在当今数据驱动的世界中,有效的数据分析对于知情决策至关重要。 Python凭借其用户友好的语法和广泛的库,已成为数据科学家和分析师的首选语言。本文重点介绍了十个基本的Python库,用于数据分析,可满足新手和经验丰富的用户的需求。
Numpy形成了Python的数值计算功能的基岩。它在处理大型多维阵列和矩阵方面表现出色,为有效的阵列操作提供了全面的数学功能套件。
优势:
限制:
导入numpy作为NP data = np.Array([1,2,3,4,5]) 打印(“数组:”,数据) 打印(“平均:”,np.mean(data)) 打印(“标准偏差:”,NP.STD(数据))
输出

Pandas使用其数据框结构简化了数据操作,非常适合使用表格数据。熊猫的清洁,转换和分析结构化数据集变得非常容易。
优势:
限制:
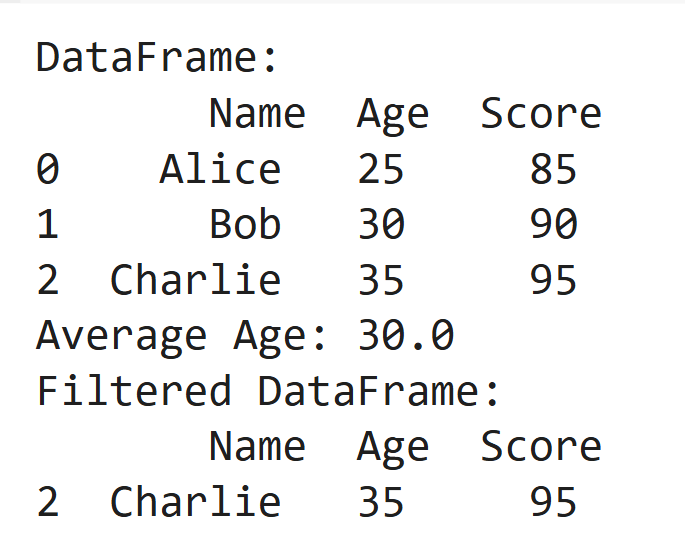
导入大熊猫作为pd
data = pd.dataframe({'name':['alice','bob','charlie'],'age':[25,30,35],'score':[85,90,95]})
打印(“ dataframe:\ n”,数据)
打印(“平均年龄:”,数据['age']。平均())
打印(“过滤的数据框:\ n”,数据[data ['scorce']> 90])输出
Matplotlib是一个多功能的绘图库,可以创建各种静态,互动甚至动画的可视化。
优势:
限制:
导入matplotlib.pyplot作为PLT x = [1,2,3,4,5] y = [2,4,6,8,10] plt.plot(x,y,label =“线图”) plt.xlabel('x-axis') plt.ylabel('y轴') plt.title('matplotlib示例') plt.legend() plt.show()
输出

Seaborn建立在Matplotlib的基础上,简化了统计信息和视觉吸引力的图。
优势:
限制:
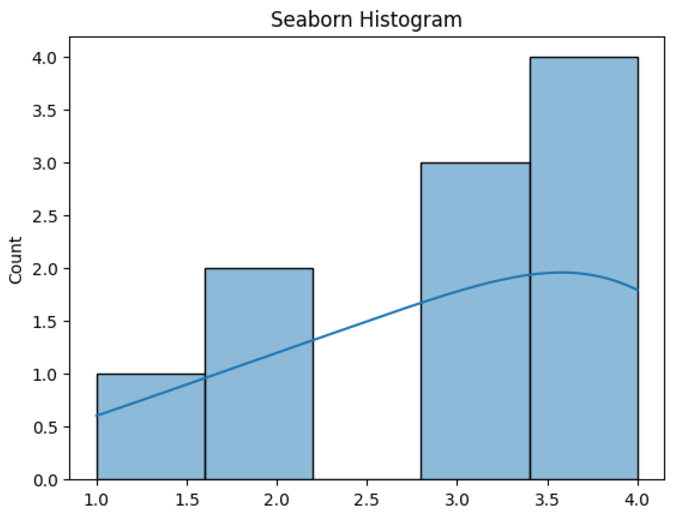
进口海洋作为SNS 导入matplotlib.pyplot作为PLT 数据= [1,2,2,3,3,3,4,4,4,4,4] sns.histplot(数据,kde = true) plt.title(“海洋直方图”) plt.show()
输出
Scipy扩展了Numpy,提供了用于科学计算的高级工具,包括优化,集成和信号处理。
优势:
限制:
从scipy.stats导入ttest_ind group1 = [1,2,3,4,5] group2 = [2,3,4,5,6] t_stat,p_value = ttest_ind(group1,group2) 打印(“ t-statistic:”,T_STAT) 打印(“ p-value:”,p_value)
输出

Scikit-Learn是一个强大的机器学习库,为分类,回归,聚类和降低维度提供了工具。
优势:
限制:
来自sklearn.linear_model导入linearrecress x = [[1],[2],[3],[4] y = [2,4,6,8] 型号=线性拉力() 型号(x,y) print(“ x = 5:”的预测,model.predict([[5]])[0])
输出
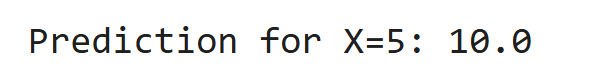
StatsModels着重于统计建模和假设检验,对计量经济学和统计研究特别有用。
优势:
限制:
导入statsmodels.api作为sm x = [1,2,3,4] y = [2,4,6,8] x = sm.add_constant(x) model = sm.ols(y,x).fit() 打印(model.summary())
输出

情节创建了交互式和适合Web的可视化,非常适合仪表板和Web应用程序。
优势:
限制:
导入plotly.extress为px data = px.data.iris() 图= px. -scatter(数据,x =“ sepal_width”,y =“ sepal_length”,color =“ stelt”,title =“ iris dataSet dataset散点图”) 图show()
输出

Pyspark为Apache Spark提供了Python接口,从而为大规模数据处理提供了分布式计算。
优势:
限制:
!PIP安装Pyspark 来自pyspark.sql进口火花 spark = sparksession.builder.appname(“ pyspark示例”)。getorCreate() data = spark.createdataframe([((1,“爱丽丝”),(2,“ bob”)]],[“ id”,“ name”]) data.show()
输出

Altair是基于Vega和Vega-Lite的声明性可视化库,提供了一种简明的语法,用于创建复杂的图。
优势:
限制:
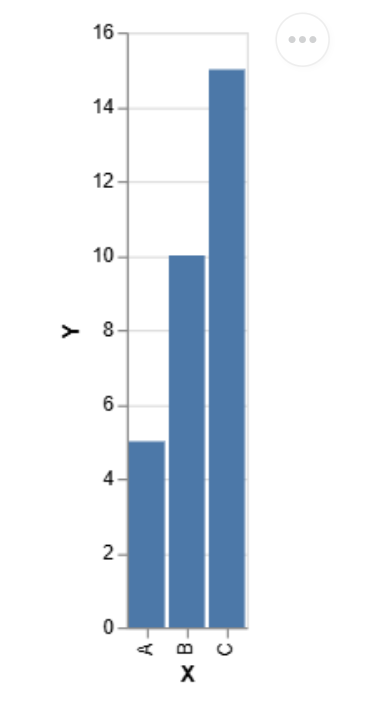
导入Altair作为Alt
导入大熊猫作为pd
data = pd.dataframe({'x':['a','b','c'],'y':[5,10,15]})
图表= alt.chart(data).mark_bar()。encode(x ='x',y ='y')
Chart.display()输出
选择适当的库取决于几个因素:任务的性质(数据清洁,可视化,建模),数据集大小,分析目标以及您的经验水平。在进行选择之前,请考虑每个库的优势和局限性。
Python在数据分析中的受欢迎程度源于其易用性,广泛的库,强大的社区支持以及与大数据工具的无缝集成。
Python丰富的图书馆生态系统使数据分析师能够应对各种挑战,从简单的数据探索到复杂的机器学习任务。为工作选择正确的工具至关重要,此概述为选择最佳的Python库提供了可满足您数据分析需求的最佳基础。
以上是2025年数据分析的前20个Python库的详细内容。更多信息请关注PHP中文网其他相关文章!





















