
本文探讨了检索功能生成(RAG),这是一种尖端的AI技术,可通过合并检索和发电能力来提高响应精度。 RAG通过在产生响应之前先从知识库中首先检索相关的当前信息来增强AI提供可靠的,上下文相关的答案的能力。讨论涵盖了详细的抹布工作流程,包括使用矢量数据库进行有效的数据检索,距离指标对相似性匹配的重要性以及RAG如何减轻幻觉和造型等常见的AI陷阱。还提供了建立和实施抹布的实用步骤,这是旨在改善基于AI的知识检索的任何人的综合指南。
*本文是***数据科学博客马拉松的一部分。
RAG是一种AI方法,可以通过在产生响应之前检索相关信息来提高答案的准确性。与传统的AI完全依靠培训数据不同,RAG搜索数据库或知识源以获取最新信息或特定信息。然后,这些信息会告知生成更准确,更可靠的答案。 RAG方法结合了检索和生成模型,以提高生成内容的质量和准确性,尤其是在NLP任务中。
进一步阅读:用于知识密集型NLP任务的检索效果
破布工作流程由两个主要阶段组成:检索和发电。逐步过程在下面概述。
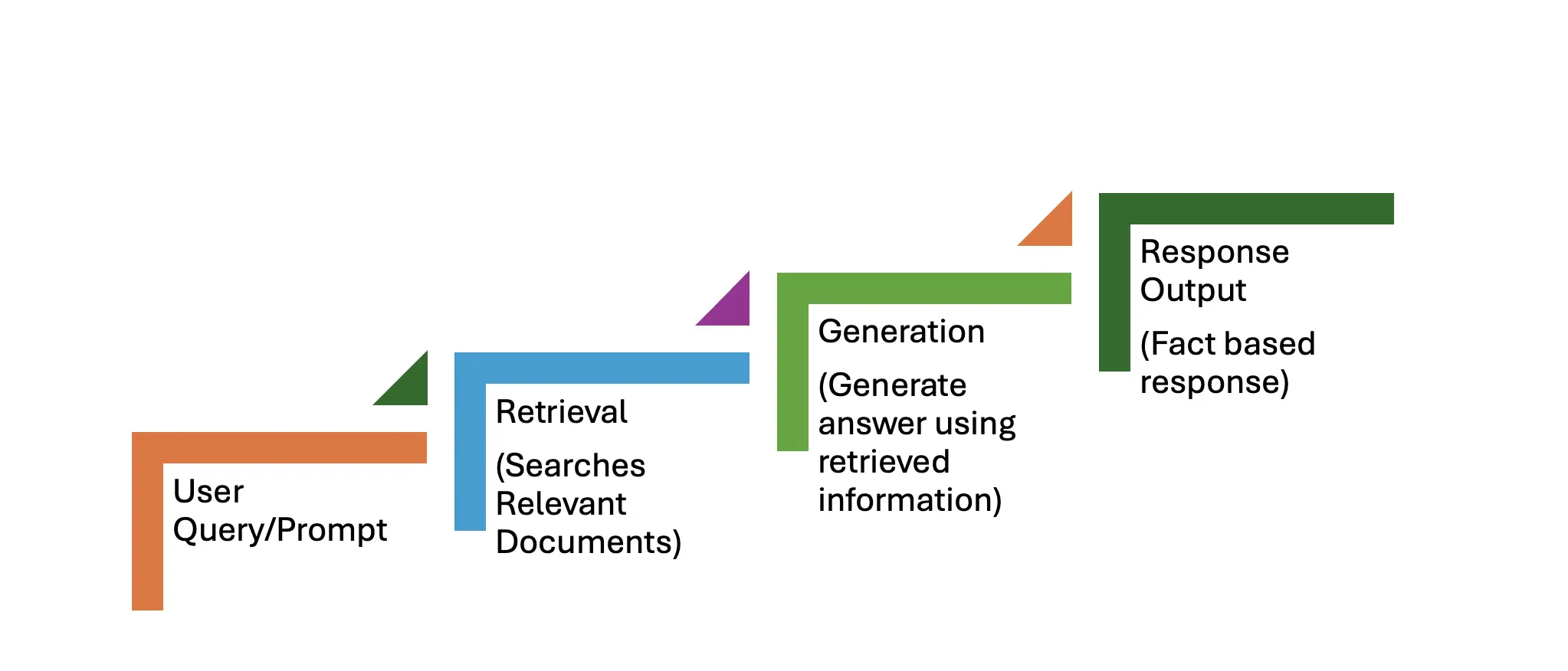
用户查询,例如:“量子计算的最新进步是什么?”作为提示。
此阶段涉及三个步骤:
此阶段还涉及三个步骤:
该系统返回实际上准确且最新的响应,优于纯粹的生成模型可以产生的响应。
在没有抹布的情况下进行AI进行比较突出了抹布的变革力。传统模型仅依赖于预训练的数据,而RAG通过实时信息检索增强了响应,从而弥合了静态和动态,上下文意识到的输出之间的差距。
| 与抹布 | 没有抹布 |
|---|---|
| 从外部来源检索当前信息。 | 仅依靠预先训练的(可能过时的)知识。 |
| 提供特定的解决方案(例如,补丁版本,配置更改)。 | 产生模糊的,广义的响应,缺乏可操作的细节。 |
| 通过将响应扎根的真实文件中的响应来最大程度地减少幻觉风险。 | 幻觉或不准确的风险更高,尤其是对于最近的信息。 |
| 包括最新的供应商咨询或安全补丁。 | 可能不知道最近的咨询或更新。 |
| 结合内部(特定组织)和外部(公共数据库)信息。 | 无法检索新的或特定于组织的信息。 |
基于语义相似性,向量数据库对于在抹布中有效,准确的文档或数据检索至关重要。与基于关键字的搜索依赖于确切的术语匹配不同,向量数据库表示文本是高维空间中的向量,将相似的含义聚集在一起。这使它们非常适合抹布系统。向量数据库存储了矢量化文档,从而为AI模型提供了更精确的信息检索。
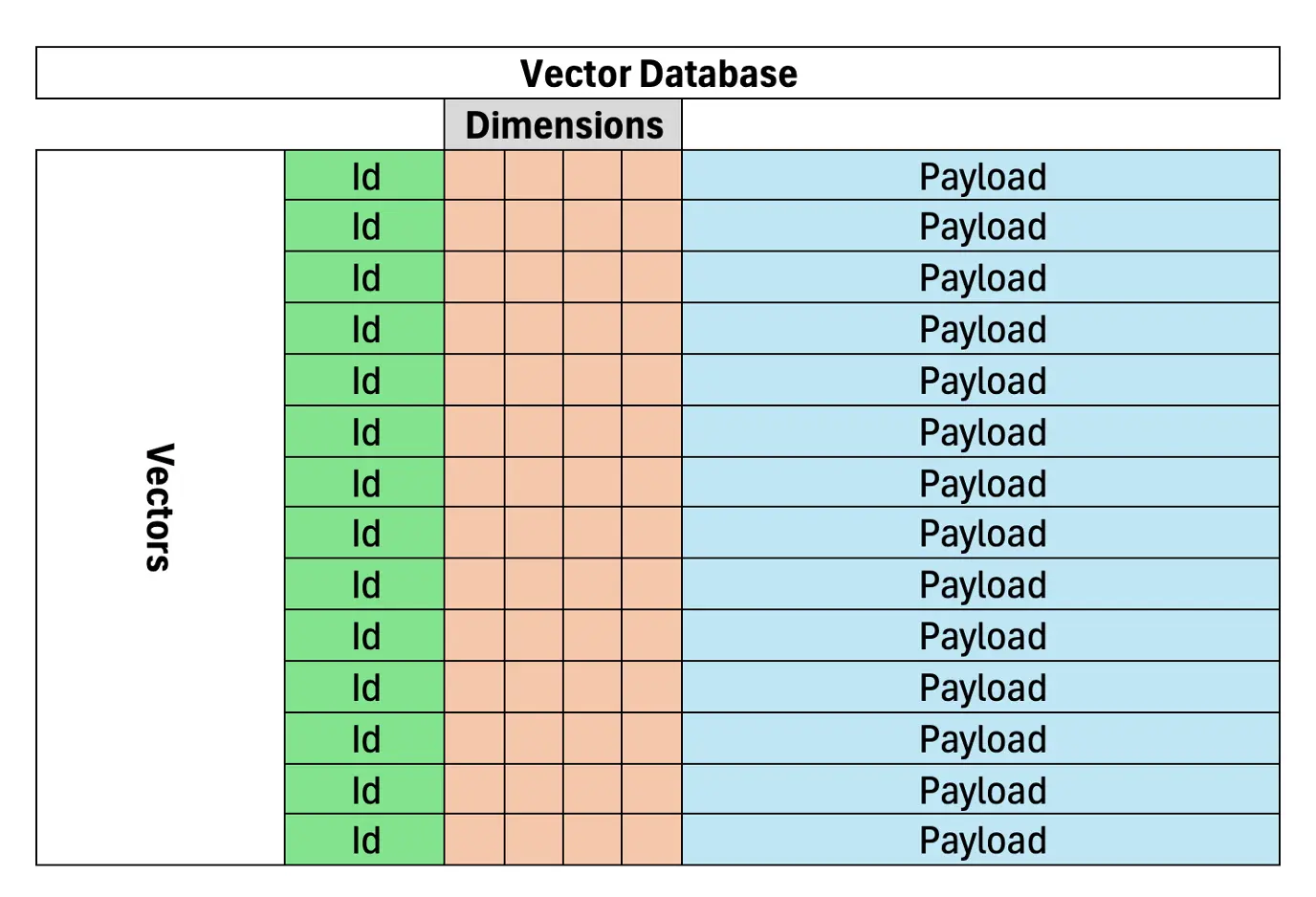
(其余部分将遵循相似的重新构图和重组模式,以维护原始信息和图像放置。)
以上是改善AI幻觉的详细内容。更多信息请关注PHP中文网其他相关文章!






















