
该博客文章探讨了用于加载大型Pytorch模型的有效内存管理技术,在处理有限的GPU或CPU资源时尤其有益。作者专注于使用torch.save(model.state_dict(), "model.pth")保存模型的方案。尽管示例使用大型语言模型(LLM),但这些技术适用于任何Pytorch模型。
高效模型加载的关键策略:
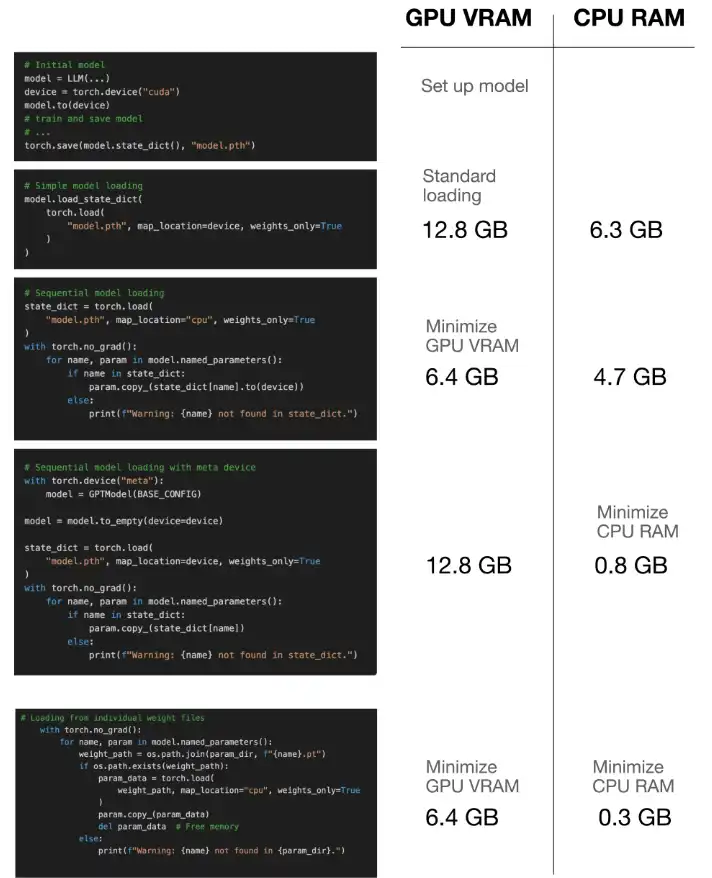
本文详细介绍了在模型加载过程中优化内存使用量的几种方法:
顺序的重量加载:此技术将模型体系结构加载到GPU上,然后迭代地将单个权重从CPU存储器复制到GPU。这样可以防止GPU内存中同时存在完整模型和权重,从而大大降低了峰值存储器的消耗。
元设备: Pytorch的“ Meta”设备可实现张量创建,而无需立即内存分配。该模型在元设备上初始化,然后转移到GPU上,然后将权重直接加载到GPU上,从而最大程度地减少CPU存储器使用情况。这对于CPU RAM有限的系统特别有用。
mmap=True in torch.load() :此选项使用内存映射的文件I/O,允许Pytorch直接按需磁盘读取模型数据,而不是将所有内容加载到RAM中。这对于具有有限的CPU内存和快速磁盘I/O的系统是理想的选择。
个人节省和加载:作为极限资源的最后手段,本文建议将每个模型参数(张量)保存为单独的文件。然后,加载一次是一个参数,在任何给定时刻最小化内存足迹。这是以增加I/O开销为代价的。
实际实施和基准测试:
该帖子提供了python代码段,展示了每种技术,包括用于跟踪GPU和CPU内存使用情况的实用程序功能。这些基准说明了每种方法获得的内存节省。作者比较每种方法的内存使用量,突出了记忆效率和潜在性能影响之间的权衡。
结论:
本文结束时强调了记忆有效的模型加载的重要性,尤其是对于大型模型。它建议根据特定的硬件限制(CPU RAM,GPU VRAM)和I/O速度选择最合适的技术。对于有限的CPU RAM, mmap=True方法通常是首选的,而单个重量负载是极度约束环境的最后手段。顺序加载方法在许多情况下提供了良好的平衡。
以上是pytorch中的记忆效率重量加载的详细内容。更多信息请关注PHP中文网其他相关文章!






















