
检索增强的生成(RAG)通过合并外部知识来源可显着增强大型语言模型(LLM),从而产生更准确和上下文相关的响应。但是,抹布系统并非没有缺陷,经常产生不准确或无关的输出。这些限制阻碍了抹布在各个领域的应用,包括客户服务,研究和内容创建。了解这些缺点对于开发更可靠的基于检索的AI至关重要。本文深入研究了RAG失败背后的原因,并探讨了提高破布性能的策略,从而导致更有效,更可扩展的系统。改进的抹布模型有望更一致,高质量的AI输出。
目录
什么是抹布?
抹布或检索效果的一代是一种复杂的自然语言处理技术,将检索方法与生成的AI模型相结合,以提供更精确且上下文适当的答案。与仅依靠培训数据的模型不同,RAG动态访问外部信息以告知其响应。
关键的抹布组件:
了解更多:了解检索增强发电(RAG)
抹布的局限性
尽管RAG通过合并外部知识,提高准确性和上下文相关性来增强LLM,但它面临着限制其整体可靠性和有效性的重大挑战。认识到这些局限性对于开发更健壮的系统至关重要。
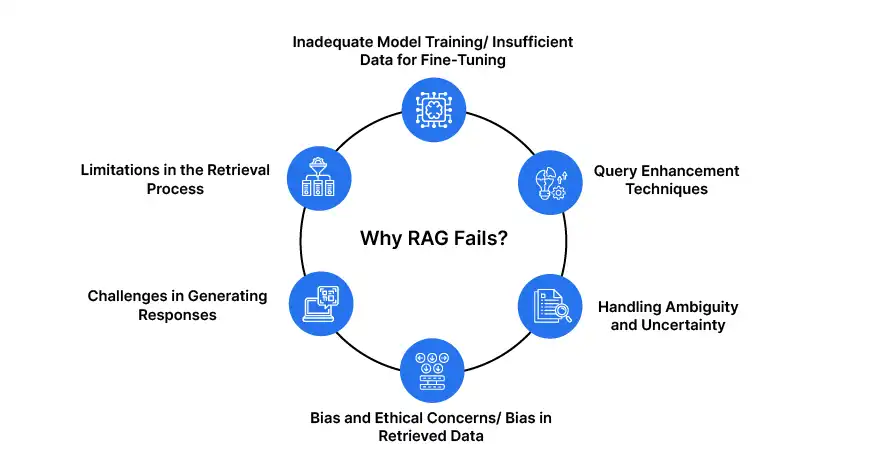
这些限制分为三个主要类别:
通过解决这些问题并实施有针对性的改进,我们可以建立更可靠和有效的抹布系统。
观看以了解更多信息:解决抹布系统中的现实世界挑战
(其余部分详细详细介绍了检索过程故障,生成过程失败,系统级失败,结论和常见问题解答将遵循类似的重新绘制和重组模式,并保持原始内容和图像放置。
以上是为什么破布失败以及如何修复?的详细内容。更多信息请关注PHP中文网其他相关文章!






















