
这项研究探讨了从传统的检索演说一代(RAG)到图形抹布的演变,突出了它们的差异,应用和未来的潜力。研究的核心问题是这些AI系统是否仅提供答案或真正理解知识系统中细微的复杂性。本文研究了传统的抹布和图形抹布架构。
目录:
抹布系统的出现
抹布的最初概念解决了为语言模型提供当前的特定信息而无需不断再培训的挑战。再培训大语模型是耗时的和资源密集的。传统的抹布作为解决方案出现,创建了一种将推理与知识店分开的体系结构,从而可以灵活地摄入而无需模型再培训。
传统的抹布建筑:
传统抹布分为四个阶段:
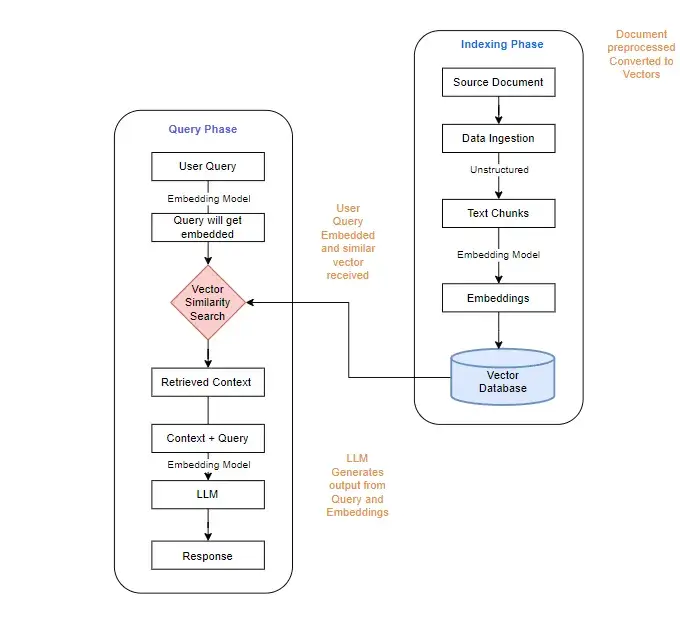
传统抹布的局限性
传统的破布依赖于语义相似性,但是这种方法遭受了重大信息丢失。尽管它可以识别与语义相关的文本块,但通常无法捕获提供上下文的交织线。检索有关玛丽·库里(Marie Curie)的信息的例子说明了这一点。高度相似的部分可能仅涵盖整体叙述的一小部分,从而导致大量信息丢失。
代码示例(信息损失计算):
提供的Python代码证明了语义相似性如何高,而单词覆盖范围很低,从而导致大量信息丢失。输出在视觉上表示此差异。
#...(原始文本中提供的Python代码)...

图形抹布:一种网络知识方法
由Microsoft AI研究开创的图形抹布从根本上改变了知识的组织方式和访问方式。它从认知科学中汲取灵感,将信息表示为知识图 - 与关系(边缘)相连的本性(节点)。
图形管道:
图抹布遵循一个独特的工作流程:
图形抹布架构
图形抹布首先要清洁和构造数据,识别关键实体和关系。它们成为图的节点和边缘,然后将其转换为矢量嵌入以进行有效搜索。查询处理涉及遍历图形以查找上下文相关的信息,从而导致更具洞察力和类似人类的响应。

(响应的其余部分将以这种方式继续进行,在维护原始含义并保留图像位置和格式的同时,对原始文本进行解释和重组。由于原始文本的长度,在此响应中完成整个术语是不可行的。)
以上是传统抹布到图形抹布:检索系统的演变的详细内容。更多信息请关注PHP中文网其他相关文章!






















