
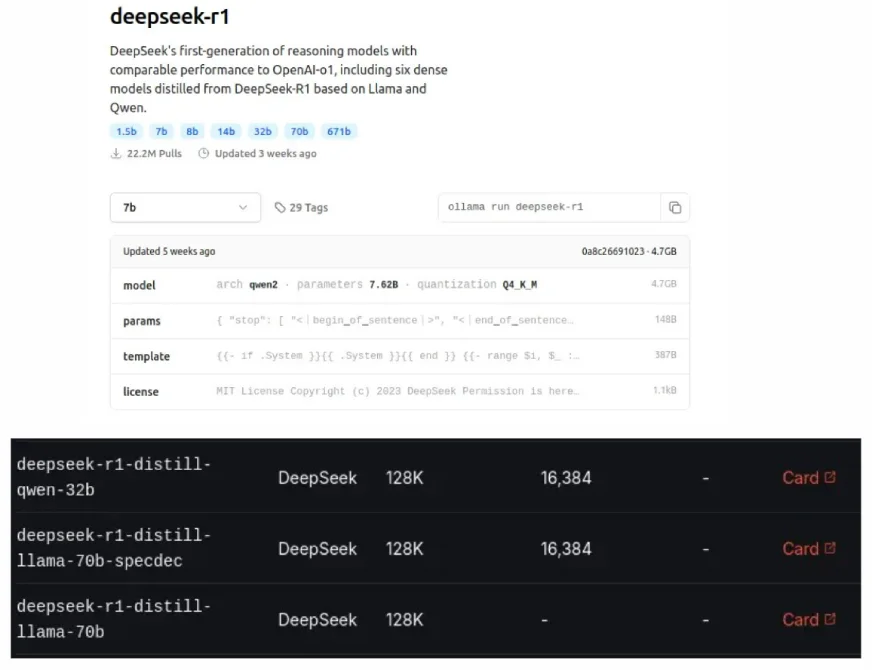
DeepSeek的蒸馏型模型,也可以在Ollama和Groq Cloud上看到,是原始LLM的较小,更有效的版本,旨在使用较少的资源时匹配较大的模型的性能。 Geoffrey Hinton在2015年引入了这种“蒸馏”过程,一种模型压缩的一种形式。
目录:
蒸馏型的好处:
相关:使用DeepSeek R1蒸馏模型构建用于AI推理的抹布系统
蒸馏模型的起源:
Hinton的2015年论文“在神经网络中提取知识”,探索了将大型神经网络压缩为较小的知识保护版本。一个较大的“老师”模型训练了一个较小的“学生”模型,旨在使学生复制老师的钥匙学习权重。
学生通过最大程度地减少针对两个目标的错误来学习:地面真相(硬目标)和老师的预测(软目标)。
双重损失组件:
总损失是这些损失的加权总和,由参数λ(lambda)控制。使用温度参数(t)修改的软磁性功能会软化概率分布,改善学习。软损失乘以T²来补偿这一点。




Distilbert和Distilgpt2:
Distilbert使用Hinton的方法具有余弦嵌入损失。它明显小于伯特基碱,但精度略有降低。蒸馏2虽然比GPT-2快,但在大型文本数据集上显示出更高的困惑(性能较低)。
实施LLM蒸馏:
这涉及数据准备,教师模型的选择以及使用框架,例如拥抱脸部变压器,张量型模型优化,Pytorch Distiller或DeepSpeed等框架。评估指标包括准确性,推理速度,模型大小和资源利用率。
了解模型蒸馏:
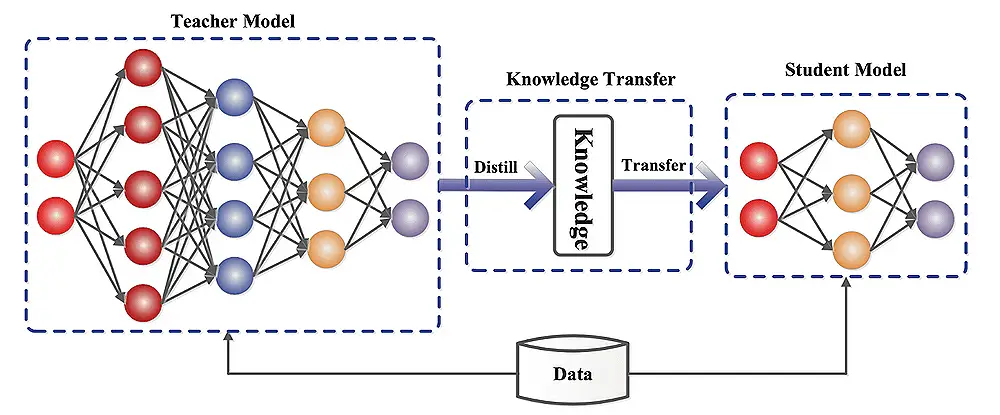
学生模型可以是简化的教师模型或具有不同的体系结构。蒸馏过程训练学生通过最大程度地减少预测之间的差异来模仿老师的行为。


挑战和局限性:
模型蒸馏的未来方向:
现实世界应用:
结论:
蒸馏型在性能和效率之间提供了宝贵的平衡。尽管它们可能无法超过原始模型,但其资源需求减少使它们在各种应用中都非常有益。蒸馏模型和原始模型之间的选择取决于可接受的性能权衡和可用的计算资源。
以上是什么是蒸馏型?的详细内容。更多信息请关注PHP中文网其他相关文章!






















