

匹配网页内容的网址的正则,该如何解决

匹配网页内容的网址的正则
我希望把这个网址http://www.425sf.com/的网址都匹配出来
- PHP code
<!--
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
$url = "http://www.425sf.com/";//采集地址
$content = file_get_contents($url);
$patten = "^((https|http|ftp|rtsp|mms)?://)?(([0-9a-z_!~*'().&=+$%-]+:)?[0-9a-z_!~*'().&=+$%-]+@)?(([0-9]{1,3}\.){3}[0-9]{1,3}|([0-9a-z_!~*'()-]+\.)*([0-9a-z][0-9a-z-]{0,61})?[0-9a-z]\.[a-z]{2,6})(:[0-9]{1,4})?((/?)|(/[0-9a-z_!~*'().;?:@&=+$,%#-]+)+/?)$";
preg_match_all($patten, $content, $matches);
上面的匹配正则我是参考这里的
http://topic.csdn.net/u/20070307/14/87e6b878-800e-4a88-830e-7d0eeeaba891.html
我用正则测试工具试过比较准确
但是这里php运行好像取不出来
------解决方案--------------------
- PHP code
$html = sdfjk
<a href="http://hi.baidu.com?info=aaa" id="abcdf">sdfjk</a>
html;
$r = '/<a preg_match_all echo>';print_r($a[1]);
/*
Array
(
[0] => http://www.baidu.com
[1] => http://hi.baidu.com?info=aaa
)
*/
<br><font color="#e78608">------解决方案--------------------</font><br>LS正解:<br><br><br>preg_match_all<br>(PHP 4, PHP 5)<br><br>preg_match_all ― 进行全局正则表达式匹配<br><br>说明<br>int preg_match_all ( string $pattern , string $subject , array $matches [, int $flags ] )<br>在 subject 中搜索所有与 pattern 给出的正则表达式匹配的内容并将结果以 flags 指定的顺序放到 matches 中。 <br><br>搜索到第一个匹配项之后,接下来的搜索从上一个匹配项末尾开始。 <br><br>flags 可以是下列标记的组合(注意把 PREG_PATTERN_ORDER 和 PREG_SET_ORDER 合起来用没有意义): <br><br>PREG_PATTERN_ORDER <br>对结果排序使 $matches[0] 为全部模式匹配的数组,$matches[1] 为第一个括号中的子模式所匹配的字符串组成的数组,以此类推。 <br><br><br><?php <br />preg_match_all ("|]+>(.*)[^>]+>|U",<br> "<b>example: </b><div align="left">this is a test</div>",<br> $out, PREG_PATTERN_ORDER);<br>print $out[0][0].", ".$out[0][1]."\n";<br>print $out[1][0].", ".$out[1][1]."\n";<br>?> <br>本例将输出: <br><br><b>example: </b>, <div align="left">this is a test</div>
<br>example: , this is a test<br>因此,$out[0] 包含匹配整个模式的字符串,$out[1] 包含一对 HTML 标记之间的字符串。 <br><br><br>PREG_SET_ORDER <br>对结果排序使 $matches[0] 为第一组匹配项的数组,$matches[1] 为第二组匹配项的数组,以此类推。 <br><br><?php <br />preg_match_all ("|]+>(.*)[^>]+>|U",<br> "<b>example: </b><div align="left">this is a test</div>",<br> $out, PREG_SET_ORDER);<br>print $out[0][0].", ".$out[0][1]."\n";<br>print $out[1][0].", ".$out[1][1]."\n";<br>?> <br>本例将输出: <br><br><b>example: </b>, example:<br><div align="left">this is a test</div>, this is a test<br><br>本例中,$matches[0] 是第一组匹配结果,$matches[0][0] 包含匹配整个模式的文本,$matches[0][1] 包含匹配第一个子模式的文本,以此类推。同样,$matches[1] 是第二组匹配结果,等等。 <br><br>PREG_OFFSET_CAPTURE <br>如果设定本标记,对每个出现的匹配结果也同时返回其附属的字符串偏移量。注意这改变了返回的数组的值,使其中的每个单元也是一个数组,其中第一项为匹配字符串,第二项为其在 subject 中的偏移量。本标记自 PHP 4.3.0 起可用。 <br><br><br>如果没有给出标记,则假定为 PREG_PATTERN_ORDER。 <br><br>返回整个模式匹配的次数(可能为零),如果出错返回 FALSE。 <br><br><br>Example #1 从某文本中取得所有的电话号码<br><br><?php <br />preg_match_all ("/\(? (\d{3})? \)? (?(1) [\-\s] ) \d{3}-\d{4}/x",<br> "Call 555-1212 or 1-800-555-1212", $phones);<br>?> <br><br><br>Example #2 搜索匹配的 HTML 标记(greedy)<br><br><?php <br />// \\2 是一个逆向引用的例子,其在 PCRE 中的含义是<br>// 必须匹配正则表达式本身中第二组括号内的内容,本例中<br>// 就是 ([\w]+)。因为字符串在双引号中,所以需要<br>// 多加一个反斜线。<br>$html = "<b>bold text</b></a><a href="howdy.html">click me</a>"; <div class="clear">
</div>
热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 解决方法:您的组织要求您更改 PIN 码
Oct 04, 2023 pm 05:45 PM
解决方法:您的组织要求您更改 PIN 码
Oct 04, 2023 pm 05:45 PM
“你的组织要求你更改PIN消息”将显示在登录屏幕上。当在使用基于组织的帐户设置的电脑上达到PIN过期限制时,就会发生这种情况,在该电脑上,他们可以控制个人设备。但是,如果您使用个人帐户设置了Windows,则理想情况下不应显示错误消息。虽然情况并非总是如此。大多数遇到错误的用户使用个人帐户报告。为什么我的组织要求我在Windows11上更改我的PIN?可能是您的帐户与组织相关联,您的主要方法应该是验证这一点。联系域管理员会有所帮助!此外,配置错误的本地策略设置或不正确的注册表项也可能导致错误。即
 Windows 11 上调整窗口边框设置的方法:更改颜色和大小
Sep 22, 2023 am 11:37 AM
Windows 11 上调整窗口边框设置的方法:更改颜色和大小
Sep 22, 2023 am 11:37 AM
Windows11将清新优雅的设计带到了最前沿;现代界面允许您个性化和更改最精细的细节,例如窗口边框。在本指南中,我们将讨论分步说明,以帮助您在Windows操作系统中创建反映您的风格的环境。如何更改窗口边框设置?按+打开“设置”应用。WindowsI转到个性化,然后单击颜色设置。颜色更改窗口边框设置窗口11“宽度=”643“高度=”500“>找到在标题栏和窗口边框上显示强调色选项,然后切换它旁边的开关。若要在“开始”菜单和任务栏上显示主题色,请打开“在开始”菜单和任务栏上显示主题
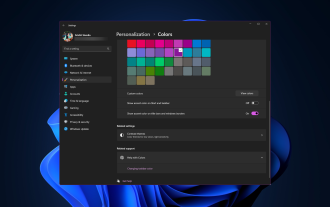 如何在 Windows 11 上更改标题栏颜色?
Sep 14, 2023 pm 03:33 PM
如何在 Windows 11 上更改标题栏颜色?
Sep 14, 2023 pm 03:33 PM
默认情况下,Windows11上的标题栏颜色取决于您选择的深色/浅色主题。但是,您可以将其更改为所需的任何颜色。在本指南中,我们将讨论三种方法的分步说明,以更改它并个性化您的桌面体验,使其具有视觉吸引力。是否可以更改活动和非活动窗口的标题栏颜色?是的,您可以使用“设置”应用更改活动窗口的标题栏颜色,也可以使用注册表编辑器更改非活动窗口的标题栏颜色。若要了解这些步骤,请转到下一部分。如何在Windows11中更改标题栏的颜色?1.使用“设置”应用按+打开设置窗口。WindowsI前往“个性化”,然
 Windows 11 上启用或禁用任务栏缩略图预览的方法
Sep 15, 2023 pm 03:57 PM
Windows 11 上启用或禁用任务栏缩略图预览的方法
Sep 15, 2023 pm 03:57 PM
任务栏缩略图可能很有趣,但它们也可能分散注意力或烦人。考虑到您将鼠标悬停在该区域的频率,您可能无意中关闭了重要窗口几次。另一个缺点是它使用更多的系统资源,因此,如果您一直在寻找一种提高资源效率的方法,我们将向您展示如何禁用它。不过,如果您的硬件规格可以处理它并且您喜欢预览版,则可以启用它。如何在Windows11中启用任务栏缩略图预览?1.使用“设置”应用点击键并单击设置。Windows单击系统,然后选择关于。点击高级系统设置。导航到“高级”选项卡,然后选择“性能”下的“设置”。在“视觉效果”选
 OOBELANGUAGE错误Windows 11 / 10修复中出现问题的问题
Jul 16, 2023 pm 03:29 PM
OOBELANGUAGE错误Windows 11 / 10修复中出现问题的问题
Jul 16, 2023 pm 03:29 PM
您是否在Windows安装程序页面上看到“出现问题”以及“OOBELANGUAGE”语句?Windows的安装有时会因此类错误而停止。OOBE表示开箱即用的体验。正如错误提示所表示的那样,这是与OOBE语言选择相关的问题。没有什么可担心的,你可以通过OOBE屏幕本身的漂亮注册表编辑来解决这个问题。快速修复–1.单击OOBE应用底部的“重试”按钮。这将继续进行该过程,而不会再打嗝。2.使用电源按钮强制关闭系统。系统重新启动后,OOBE应继续。3.断开系统与互联网的连接。在脱机模式下完成OOBE的所
 Windows 11 上的显示缩放比例调整指南
Sep 19, 2023 pm 06:45 PM
Windows 11 上的显示缩放比例调整指南
Sep 19, 2023 pm 06:45 PM
在Windows11上的显示缩放方面,我们都有不同的偏好。有些人喜欢大图标,有些人喜欢小图标。但是,我们都同意拥有正确的缩放比例很重要。字体缩放不良或图像过度缩放可能是工作时真正的生产力杀手,因此您需要知道如何对其进行自定义以充分利用系统功能。自定义缩放的优点:对于难以阅读屏幕上的文本的人来说,这是一个有用的功能。它可以帮助您一次在屏幕上查看更多内容。您可以创建仅适用于某些监视器和应用程序的自定义扩展配置文件。可以帮助提高低端硬件的性能。它使您可以更好地控制屏幕上的内容。如何在Windows11
 10种在 Windows 11 上调整亮度的方法
Dec 18, 2023 pm 02:21 PM
10种在 Windows 11 上调整亮度的方法
Dec 18, 2023 pm 02:21 PM
屏幕亮度是使用现代计算设备不可或缺的一部分,尤其是当您长时间注视屏幕时。它可以帮助您减轻眼睛疲劳,提高易读性,并轻松有效地查看内容。但是,根据您的设置,有时很难管理亮度,尤其是在具有新UI更改的Windows11上。如果您在调整亮度时遇到问题,以下是在Windows11上管理亮度的所有方法。如何在Windows11上更改亮度[10种方式解释]单显示器用户可以使用以下方法在Windows11上调整亮度。这包括使用单个显示器的台式机系统以及笔记本电脑。让我们开始吧。方法1:使用操作中心操作中心是访问
 华为GT3 Pro和GT4的差异是什么?
Dec 29, 2023 pm 02:27 PM
华为GT3 Pro和GT4的差异是什么?
Dec 29, 2023 pm 02:27 PM
许多用户在选择智能手表的时候都会选择的华为的品牌,其中华为GT3pro和GT4都是非常热门的选择,不少用户都很好奇华为GT3pro和GT4有什么区别,下面就就给大家介绍一下二者。华为GT3pro和GT4有什么区别一、外观GT4:46mm和41mm,材质是玻璃表镜+不锈钢机身+高分纤维后壳。GT3pro:46.6mm和42.9mm,材质是蓝宝石玻璃表镜+钛金属机身/陶瓷机身+陶瓷后壳二、健康GT4:采用最新的华为Truseen5.5+算法,结果会更加的精准。GT3pro:多了ECG心电图和血管及安
