

深入理解python多进程编程

1、python多进程编程背景
python中的多进程最大的好处就是充分利用多核cpu的资源,不像python中的多线程,受制于GIL的限制,从而只能进行cpu分配,在python的多进程中,适合于所有的场合,基本上能用多线程的,那么基本上就能用多进程。
在进行多进程编程的时候,其实和多线程差不多,在多线程的包threading中,存在一个线程类Thread,在其中有三种方法来创建一个线程,启动线程,其实在多进程编程中,存在一个进程类Process,也可以使用那集中方法来使用;在多线程中,内存中的数据是可以直接共享的,例如list等,但是在多进程中,内存数据是不能共享的,从而需要用单独的数据结构来处理共享的数据;在多线程中,数据共享,要保证数据的正确性,从而必须要有所,但是在多进程中,锁的考虑应该很少,因为进程是不共享内存信息的,进程之间的交互数据必须要通过特殊的数据结构,在多进程中,主要的内容如下图:
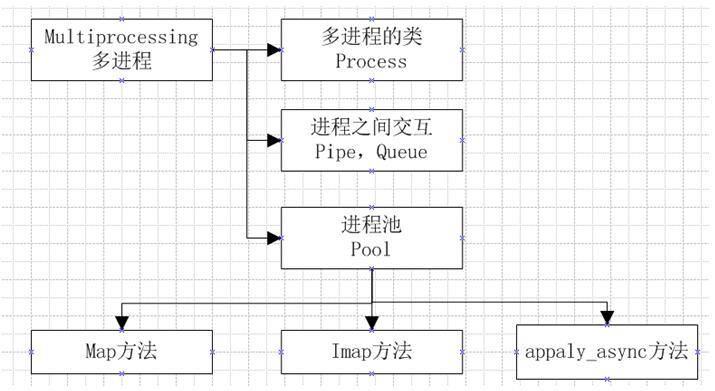
2、多进程的类Process
多进程的类Process和多线程的类Thread差不多的方法,两者的接口基本相同,具体看以下的代码:
#!/usr/bin/env python
from multiprocessing import Process
import os
import time
def func(name):
print 'start a process'
time.sleep(3)
print 'the process parent id :',os.getppid()
print 'the process id is :',os.getpid()
if __name__ =='__main__':
processes = []
for i in range(2):
p = Process(target=func,args=(i,))
processes.append(p)
for i in processes:
i.start()
print 'start all process'
for i in processes:
i.join()
#pass
print 'all sub process is done!'在上面例子中可以看到,多进程和多线程的API接口是一样一样的,显示创建进程,然后进行start开始运行,然后join等待进程结束。
在需要执行的函数中,打印出了进程的id和pid,从而可以看到父进程和子进程的id号,在linu中,进程主要是使用fork出来的,在创建进程的时候可以查询到父进程和子进程的id号,而在多线程中是无法找到线程的id,执行效果如下:
start all process start a process start a process the process parent id : 8036 the process parent id : 8036 the process id is : 8037 the process id is : 8038 all sub process is done!
在操作系统中查询的id的时候,最好用pstree,清晰:
├─sshd(1508)─┬─sshd(2259)───bash(2261)───python(7520)─┬─python(7521)
│ │ ├─python(7522)
│ │ ├─python(7523)
│ │ ├─python(7524)
│ │ ├─python(7525)
│ │ ├─python(7526)
│ │ ├─python(7527)
│ │ ├─python(7528)
│ │ ├─python(7529)
│ │ ├─python(7530)
│ │ ├─python(7531)
│ │ └─python(7532)在进行运行的时候,可以看到,如果没有join语句,那么主进程是不会等待子进程结束的,是一直会执行下去,然后再等待子进程的执行。
在多进程的时候,说,我怎么得到多进程的返回值呢?然后写了下面的代码:
#!/usr/bin/env python
import multiprocessing
class MyProcess(multiprocessing.Process):
def __init__(self,name,func,args):
super(MyProcess,self).__init__()
self.name = name
self.func = func
self.args = args
self.res = ''
def run(self):
self.res = self.func(*self.args)
print self.name
print self.res
return (self.res,'kel')
def func(name):
print 'start process...'
return name.upper()
if __name__ == '__main__':
processes = []
result = []
for i in range(3):
p = MyProcess('process',func,('kel',))
processes.append(p)
for i in processes:
i.start()
for i in processes:
i.join()
for i in processes:
result.append(i.res)
for i in result:
print i尝试从结果中返回值,从而在主进程中得到子进程的返回值,然而,,,并没有结果,后来一想,在进程中,进程之间是不共享内存的 ,那么使用list来存放数据显然是不可行的,进程之间的交互必须依赖于特殊的数据结构,从而以上的代码仅仅是执行进程,不能得到进程的返回值,但是以上代码修改为线程,那么是可以得到返回值的。
3、进程间的交互Queue
进程间交互的时候,首先就可以使用在多线程里面一样的Queue结构,但是在多进程中,必须使用multiprocessing里的Queue,代码如下:
#!/usr/bin/env python
import multiprocessing
class MyProcess(multiprocessing.Process):
def __init__(self,name,func,args):
super(MyProcess,self).__init__()
self.name = name
self.func = func
self.args = args
self.res = ''
def run(self):
self.res = self.func(*self.args)
def func(name,q):
print 'start process...'
q.put(name.upper())
if __name__ == '__main__':
processes = []
q = multiprocessing.Queue()
for i in range(3):
p = MyProcess('process',func,('kel',q))
processes.append(p)
for i in processes:
i.start()
for i in processes:
i.join()
while q.qsize() > 0:
print q.get()其实这个是上面例子的改进,在其中,并没有使用什么其他的代码,主要就是使用Queue来保存数据,从而可以达到进程间交换数据的目的。
在进行使用Queue的时候,其实用的是socket,感觉,因为在其中使用的还是发送send,然后是接收recv。
在进行数据交互的时候,其实是父进程和所有的子进程进行数据交互,所有的子进程之间基本是没有交互的,除非,但是,也是可以的,例如,每个进程去Queue中取数据,但是这个时候应该是要考虑锁,不然可能会造成数据混乱。
4、 进程之间交互Pipe
在进程之间交互数据的时候还可以使用Pipe,代码如下:
#!/usr/bin/env python
import multiprocessing
class MyProcess(multiprocessing.Process):
def __init__(self,name,func,args):
super(MyProcess,self).__init__()
self.name = name
self.func = func
self.args = args
self.res = ''
def run(self):
self.res = self.func(*self.args)
def func(name,q):
print 'start process...'
child_conn.send(name.upper())
if __name__ == '__main__':
processes = []
parent_conn,child_conn = multiprocessing.Pipe()
for i in range(3):
p = MyProcess('process',func,('kel',child_conn))
processes.append(p)
for i in processes:
i.start()
for i in processes:
i.join()
for i in processes:
print parent_conn.recv()在以上代码中,主要是使用Pipe中返回的两个socket来进行传输和接收数据,在父进程中,使用的是parent_conn,在子进程中使用的是child_conn,从而子进程发送数据的方法send,而在父进程中进行接收方法recv
最好的地方在于,明确的知道收发的次数,但是如果某个出现异常,那么估计pipe不能使用了。
5、进程池pool
其实在使用多进程的时候,感觉使用pool是最方便的,在多线程中是不存在pool的。
在使用pool的时候,可以限制每次的进程数,也就是剩余的进程是在排队,而只有在设定的数量的进程在运行,在默认的情况下,进程是cpu的个数,也就是根据multiprocessing.cpu_count()得出的结果。
在poo中,有两个方法,一个是map一个是imap,其实这两方法超级方便,在执行结束之后,可以得到每个进程的返回结果,但是缺点就是每次的时候,只能有一个参数,也就是在执行的函数中,最多是只有一个参数的,否则,需要使用组合参数的方法,代码如下所示:
#!/usr/bin/env python
import multiprocessing
def func(name):
print 'start process'
return name.upper()
if __name__ == '__main__':
p = multiprocessing.Pool(5)
print p.map(func,['kel','smile'])
for i in p.imap(func,['kel','smile']):
print i
在使用map的时候,直接返回的一个是一个list,从而这个list也就是函数执行的结果,而在imap中,返回的是一个由结果组成的迭代器,如果需要使用多个参数的话,那么估计需要*args,从而使用参数args。
在使用apply.async的时候,可以直接使用多个参数,如下所示:
#!/usr/bin/env python
import multiprocessing
import time
def func(name):
print 'start process'
time.sleep(2)
return name.upper()
if __name__ == '__main__':
results = []
p = multiprocessing.Pool(5)
for i in range(7):
res = p.apply_async(func,args=('kel',))
results.append(res)
for i in results:
print i.get(2.1)在进行得到各个结果的时候,注意使用了一个list来进行append,要不然在得到结果get的时候会阻塞进程,从而将多进程编程了单进程,从而使用了一个list来存放相关的结果,在进行得到get数据的时候,可以设置超时时间,也就是get(timeout=5),这种设置。
总结:
在进行多进程编程的时候,注意进程之间的交互,在执行函数之后,如何得到执行函数的结果,可以使用特殊的数据结构,例如Queue或者Pipe或者其他,在使用pool的时候,可以直接得到结果,map和imap都是直接得到一个list和可迭代对象,而apply_async得到的结果需要用一个list装起来,然后得到每个结果。
以上这篇深入理解python多进程编程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 如何使用Python查找文本文件的ZIPF分布
Mar 05, 2025 am 09:58 AM
如何使用Python查找文本文件的ZIPF分布
Mar 05, 2025 am 09:58 AM
本教程演示如何使用Python处理Zipf定律这一统计概念,并展示Python在处理该定律时读取和排序大型文本文件的效率。 您可能想知道Zipf分布这个术语是什么意思。要理解这个术语,我们首先需要定义Zipf定律。别担心,我会尽量简化说明。 Zipf定律 Zipf定律简单来说就是:在一个大型自然语言语料库中,最频繁出现的词的出现频率大约是第二频繁词的两倍,是第三频繁词的三倍,是第四频繁词的四倍,以此类推。 让我们来看一个例子。如果您查看美国英语的Brown语料库,您会注意到最频繁出现的词是“th
 我如何使用美丽的汤来解析HTML?
Mar 10, 2025 pm 06:54 PM
我如何使用美丽的汤来解析HTML?
Mar 10, 2025 pm 06:54 PM
本文解释了如何使用美丽的汤库来解析html。 它详细介绍了常见方法,例如find(),find_all(),select()和get_text(),以用于数据提取,处理不同的HTML结构和错误以及替代方案(SEL)
 如何使用TensorFlow或Pytorch进行深度学习?
Mar 10, 2025 pm 06:52 PM
如何使用TensorFlow或Pytorch进行深度学习?
Mar 10, 2025 pm 06:52 PM
本文比较了Tensorflow和Pytorch的深度学习。 它详细介绍了所涉及的步骤:数据准备,模型构建,培训,评估和部署。 框架之间的关键差异,特别是关于计算刻度的
 python对象的序列化和避难所化:第1部分
Mar 08, 2025 am 09:39 AM
python对象的序列化和避难所化:第1部分
Mar 08, 2025 am 09:39 AM
Python 对象的序列化和反序列化是任何非平凡程序的关键方面。如果您将某些内容保存到 Python 文件中,如果您读取配置文件,或者如果您响应 HTTP 请求,您都会进行对象序列化和反序列化。 从某种意义上说,序列化和反序列化是世界上最无聊的事情。谁会在乎所有这些格式和协议?您想持久化或流式传输一些 Python 对象,并在以后完整地取回它们。 这是一种在概念层面上看待世界的好方法。但是,在实际层面上,您选择的序列化方案、格式或协议可能会决定程序运行的速度、安全性、维护状态的自由度以及与其他系
 Python中的数学模块:统计
Mar 09, 2025 am 11:40 AM
Python中的数学模块:统计
Mar 09, 2025 am 11:40 AM
Python的statistics模块提供强大的数据统计分析功能,帮助我们快速理解数据整体特征,例如生物统计学和商业分析等领域。无需逐个查看数据点,只需查看均值或方差等统计量,即可发现原始数据中可能被忽略的趋势和特征,并更轻松、有效地比较大型数据集。 本教程将介绍如何计算平均值和衡量数据集的离散程度。除非另有说明,本模块中的所有函数都支持使用mean()函数计算平均值,而非简单的求和平均。 也可使用浮点数。 import random import statistics from fracti
 使用Python处理专业错误
Mar 04, 2025 am 10:58 AM
使用Python处理专业错误
Mar 04, 2025 am 10:58 AM
在本教程中,您将从整个系统的角度学习如何处理Python中的错误条件。错误处理是设计的关键方面,它从最低级别(有时是硬件)一直到最终用户。如果y
 哪些流行的Python库及其用途?
Mar 21, 2025 pm 06:46 PM
哪些流行的Python库及其用途?
Mar 21, 2025 pm 06:46 PM
本文讨论了诸如Numpy,Pandas,Matplotlib,Scikit-Learn,Tensorflow,Tensorflow,Django,Blask和请求等流行的Python库,并详细介绍了它们在科学计算,数据分析,可视化,机器学习,网络开发和H中的用途
 用美丽的汤在Python中刮擦网页:搜索和DOM修改
Mar 08, 2025 am 10:36 AM
用美丽的汤在Python中刮擦网页:搜索和DOM修改
Mar 08, 2025 am 10:36 AM
该教程建立在先前对美丽汤的介绍基础上,重点是简单的树导航之外的DOM操纵。 我们将探索有效的搜索方法和技术,以修改HTML结构。 一种常见的DOM搜索方法是EX
