

[Python]网络爬虫(三):异常的处理和HTTP状态码的分类

当urlopen不能够处理一个response时,产生urlError。
不过通常的Python APIs异常如ValueError,TypeError等也会同时产生。
HTTPError是urlError的子类,通常在特定HTTP URLs中产生。
1.URLError
通常,URLError在没有网络连接(没有路由到特定服务器),或者服务器不存在的情况下产生。
[python] view plaincopy
- import urllib2
- req = urllib2.Request('http://www.baibai.com')
- try: urllib2.urlopen(req)
- except urllib2.URLError, e:
- print e.reason
服务器上每一个HTTP 应答对象response包含一个数字"状态码"。
301:请求到的资源都会分配一个永久的URL,这样就可以在将来通过该URL来访问此资源 处理方式:重定向到分配的URL
302:请求到的资源在一个不同的URL处临时保存 处理方式:重定向到临时的URL
因为默认的处理器处理了重定向(300以外号码),并且100-299范围的号码指示成功,所以你只能看到400-599的错误号码。
BaseHTTPServer.BaseHTTPRequestHandler.response是一个很有用的应答号码字典,显示了HTTP协议使用的所有的应答号。
[python] view plaincopy
- import urllib2
- req = urllib2.Request('http://bbs.csdn.net/callmewhy')
- try:
- urllib2.urlopen(req)
- except urllib2.URLError, e:
- print e.code
- #print e.read()
3.Wrapping
[python] view
plaincopy
- from urllib2 import Request, urlopen, URLError, HTTPError
- req = Request('http://bbs.csdn.net/callmewhy')
- try:
- response = urlopen(req)
- except HTTPError, e:
- print 'The server couldn\'t fulfill the request.'
- print 'Error code: ', e.code
- except URLError, e:
- print 'We failed to reach a server.'
- print 'Reason: ', e.reason
- else:
- print 'No exception was raised.'
- # everything is fine
因为HTTPError是URLError的子类,如果URLError在前面它会捕捉到所有的URLError(包括HTTPError )。
[python] view plaincopy
- from urllib2 import Request, urlopen, URLError, HTTPError
- req = Request('http://bbs.csdn.net/callmewhy')
- try:
- response = urlopen(req)
- except URLError, e:
- if hasattr(e, 'code'):
- print 'The server couldn\'t fulfill the request.'
- print 'Error code: ', e.code
- elif hasattr(e, 'reason'):
- print 'We failed to reach a server.'
- print 'Reason: ', e.reason
- else:
- print 'No exception was raised.'
- # everything is fine
以上就介绍了[Python]网络爬虫(三):异常的处理和HTTP状态码的分类,包括了方面的内容,希望对PHP教程有兴趣的朋友有所帮助。

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 解决方法:您的组织要求您更改 PIN 码
Oct 04, 2023 pm 05:45 PM
解决方法:您的组织要求您更改 PIN 码
Oct 04, 2023 pm 05:45 PM
“你的组织要求你更改PIN消息”将显示在登录屏幕上。当在使用基于组织的帐户设置的电脑上达到PIN过期限制时,就会发生这种情况,在该电脑上,他们可以控制个人设备。但是,如果您使用个人帐户设置了Windows,则理想情况下不应显示错误消息。虽然情况并非总是如此。大多数遇到错误的用户使用个人帐户报告。为什么我的组织要求我在Windows11上更改我的PIN?可能是您的帐户与组织相关联,您的主要方法应该是验证这一点。联系域管理员会有所帮助!此外,配置错误的本地策略设置或不正确的注册表项也可能导致错误。即
 Windows 11 上调整窗口边框设置的方法:更改颜色和大小
Sep 22, 2023 am 11:37 AM
Windows 11 上调整窗口边框设置的方法:更改颜色和大小
Sep 22, 2023 am 11:37 AM
Windows11将清新优雅的设计带到了最前沿;现代界面允许您个性化和更改最精细的细节,例如窗口边框。在本指南中,我们将讨论分步说明,以帮助您在Windows操作系统中创建反映您的风格的环境。如何更改窗口边框设置?按+打开“设置”应用。WindowsI转到个性化,然后单击颜色设置。颜色更改窗口边框设置窗口11“宽度=”643“高度=”500“>找到在标题栏和窗口边框上显示强调色选项,然后切换它旁边的开关。若要在“开始”菜单和任务栏上显示主题色,请打开“在开始”菜单和任务栏上显示主题
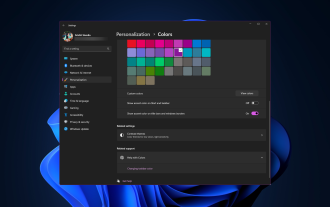 如何在 Windows 11 上更改标题栏颜色?
Sep 14, 2023 pm 03:33 PM
如何在 Windows 11 上更改标题栏颜色?
Sep 14, 2023 pm 03:33 PM
默认情况下,Windows11上的标题栏颜色取决于您选择的深色/浅色主题。但是,您可以将其更改为所需的任何颜色。在本指南中,我们将讨论三种方法的分步说明,以更改它并个性化您的桌面体验,使其具有视觉吸引力。是否可以更改活动和非活动窗口的标题栏颜色?是的,您可以使用“设置”应用更改活动窗口的标题栏颜色,也可以使用注册表编辑器更改非活动窗口的标题栏颜色。若要了解这些步骤,请转到下一部分。如何在Windows11中更改标题栏的颜色?1.使用“设置”应用按+打开设置窗口。WindowsI前往“个性化”,然
 OOBELANGUAGE错误Windows 11 / 10修复中出现问题的问题
Jul 16, 2023 pm 03:29 PM
OOBELANGUAGE错误Windows 11 / 10修复中出现问题的问题
Jul 16, 2023 pm 03:29 PM
您是否在Windows安装程序页面上看到“出现问题”以及“OOBELANGUAGE”语句?Windows的安装有时会因此类错误而停止。OOBE表示开箱即用的体验。正如错误提示所表示的那样,这是与OOBE语言选择相关的问题。没有什么可担心的,你可以通过OOBE屏幕本身的漂亮注册表编辑来解决这个问题。快速修复–1.单击OOBE应用底部的“重试”按钮。这将继续进行该过程,而不会再打嗝。2.使用电源按钮强制关闭系统。系统重新启动后,OOBE应继续。3.断开系统与互联网的连接。在脱机模式下完成OOBE的所
 Windows 11 上启用或禁用任务栏缩略图预览的方法
Sep 15, 2023 pm 03:57 PM
Windows 11 上启用或禁用任务栏缩略图预览的方法
Sep 15, 2023 pm 03:57 PM
任务栏缩略图可能很有趣,但它们也可能分散注意力或烦人。考虑到您将鼠标悬停在该区域的频率,您可能无意中关闭了重要窗口几次。另一个缺点是它使用更多的系统资源,因此,如果您一直在寻找一种提高资源效率的方法,我们将向您展示如何禁用它。不过,如果您的硬件规格可以处理它并且您喜欢预览版,则可以启用它。如何在Windows11中启用任务栏缩略图预览?1.使用“设置”应用点击键并单击设置。Windows单击系统,然后选择关于。点击高级系统设置。导航到“高级”选项卡,然后选择“性能”下的“设置”。在“视觉效果”选
 Windows 11 上的显示缩放比例调整指南
Sep 19, 2023 pm 06:45 PM
Windows 11 上的显示缩放比例调整指南
Sep 19, 2023 pm 06:45 PM
在Windows11上的显示缩放方面,我们都有不同的偏好。有些人喜欢大图标,有些人喜欢小图标。但是,我们都同意拥有正确的缩放比例很重要。字体缩放不良或图像过度缩放可能是工作时真正的生产力杀手,因此您需要知道如何对其进行自定义以充分利用系统功能。自定义缩放的优点:对于难以阅读屏幕上的文本的人来说,这是一个有用的功能。它可以帮助您一次在屏幕上查看更多内容。您可以创建仅适用于某些监视器和应用程序的自定义扩展配置文件。可以帮助提高低端硬件的性能。它使您可以更好地控制屏幕上的内容。如何在Windows11
 10种在 Windows 11 上调整亮度的方法
Dec 18, 2023 pm 02:21 PM
10种在 Windows 11 上调整亮度的方法
Dec 18, 2023 pm 02:21 PM
屏幕亮度是使用现代计算设备不可或缺的一部分,尤其是当您长时间注视屏幕时。它可以帮助您减轻眼睛疲劳,提高易读性,并轻松有效地查看内容。但是,根据您的设置,有时很难管理亮度,尤其是在具有新UI更改的Windows11上。如果您在调整亮度时遇到问题,以下是在Windows11上管理亮度的所有方法。如何在Windows11上更改亮度[10种方式解释]单显示器用户可以使用以下方法在Windows11上调整亮度。这包括使用单个显示器的台式机系统以及笔记本电脑。让我们开始吧。方法1:使用操作中心操作中心是访问
 如何修复Windows服务器中的激活错误代码0xc004f069
Jul 22, 2023 am 09:49 AM
如何修复Windows服务器中的激活错误代码0xc004f069
Jul 22, 2023 am 09:49 AM
Windows上的激活过程有时会突然转向显示包含此错误代码0xc004f069的错误消息。虽然激活过程已经联机,但一些运行WindowsServer的旧系统可能会遇到此问题。通过这些初步检查,如果这些检查不能帮助您激活系统,请跳转到主要解决方案以解决问题。解决方法–关闭错误消息和激活窗口。然后,重新启动计算机。再次从头开始重试Windows激活过程。修复1–从终端激活从cmd终端激活WindowsServerEdition系统。阶段–1检查Windows服务器版本您必须检查您使用的是哪种类型的W
