

MySQL的InnoDB索引原理详解

摘要:
本篇介绍下Mysql的InnoDB索引相关知识,从各种树到索引原理到存储的细节。
InnoDB是Mysql的默认存储引擎(Mysql5.5.5之前是MyISAM,文档)。本着高效学习的目的,本篇以介绍InnoDB为主,少量涉及MyISAM作为对比。
这篇文章是我在学习过程中总结完成的,内容主要来自书本和博客(参考文献会给出),过程中加入了一些自己的理解,描述不准确的地方烦请指出。
1 各种树形结构
本来不打算从二叉搜索树开始,因为网上已经有太多相关文章,但是考虑到清晰的图示对理解问题有很大帮助,也为了保证文章完整性,最后还是加上了这部分。
先看看几种树形结构:
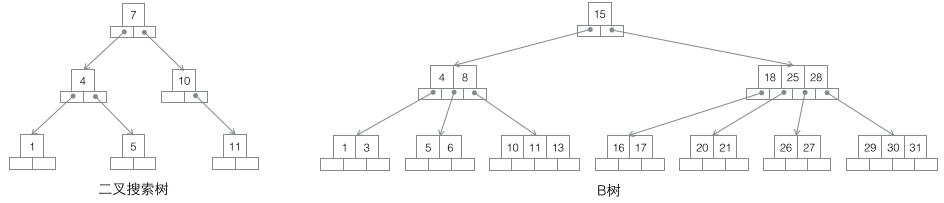
1 搜索二叉树:每个节点有两个子节点,数据量的增大必然导致高度的快速增加,显然这个不适合作为大量数据存储的基础结构。
2 B树:一棵m阶B树是一棵平衡的m路搜索树。最重要的性质是每个非根节点所包含的关键字个数 j 满足:┌m/2┐ - 1 <= j <= m - 1;一个节点的子节点数量会比关键字个数多1,这样关键字就变成了子节点的分割标志。一般会在图示中把关键字画到子节点中间,非常形象,也容易和后面的B+树区分。由于数据同时存在于叶子节点和非叶子结点中,无法简单完成按顺序遍历B树中的关键字,必须用中序遍历的方法。
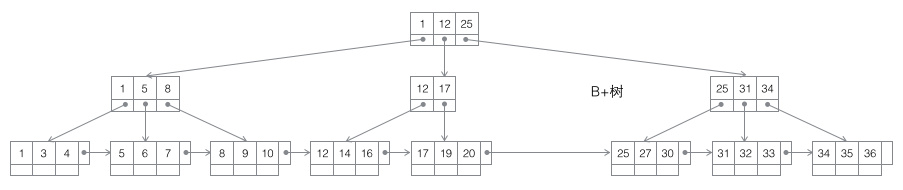
3 B+树:一棵m阶B树是一棵平衡的m路搜索树。最重要的性质是每个非根节点所包含的关键字个数 j 满足:┌m/2┐ - 1 <= j <= m;子树的个数最多可以与关键字一样多。非叶节点存储的是子树里最小的关键字。同时数据节点只存在于叶子节点中,且叶子节点间增加了横向的指针,这样顺序遍历所有数据将变得非常容易。
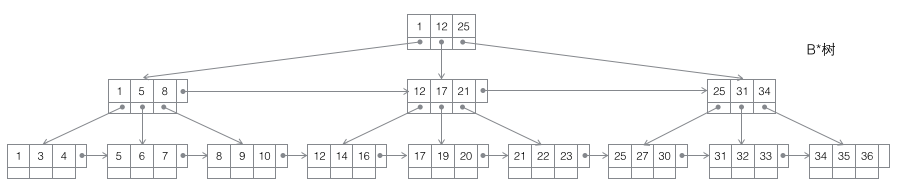
4 B*树:一棵m阶B树是一棵平衡的m路搜索树。最重要的两个性质是1每个非根节点所包含的关键字个数 j 满足:┌m2/3┐ - 1 <= j <= m;2非叶节点间添加了横向指针。
B/B+/B*三种树有相似的操作,比如检索/插入/删除节点。这里只重点关注插入节点的情况,且只分析他们在当前节点已满情况下的插入操作,因为这个动作稍微复杂且能充分体现几种树的差异。与之对比的是检索节点比较容易实现,而删除节点只要完成与插入相反的过程即可(在实际应用中删除并不是插入的完全逆操作,往往只删除数据而保留下空间为后续使用)。
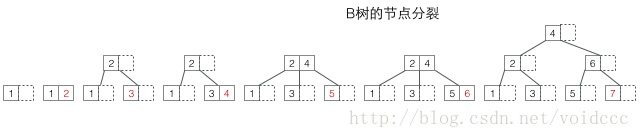
先看B树的分裂,下图的红色值即为每次新插入的节点。每当一个节点满后,就需要发生分裂(分裂是一个递归过程,参考下面7的插入导致了两层分裂),由于B树的非叶子节点同样保存了键值,所以已满节点分裂后的值将分布在三个地方:1原节点,2原节点的父节点,3原节点的新建兄弟节点(参考5,7的插入过程)。分裂有可能导致树的高度增加(参考3,7的插入过程),也可能不影响树的高度(参考5,6的插入过程)。
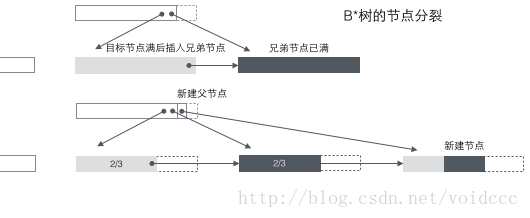
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟节点的指针。
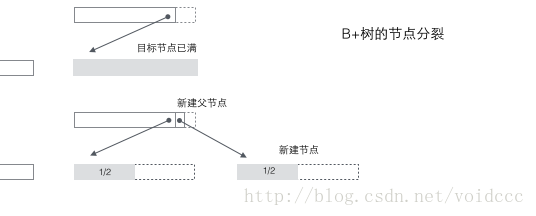
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了)。如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针。可以看到B*树的分裂非常巧妙,因为B*树要保证分裂后的节点还要2/3满,如果采用B+树的方法,只是简单的将已满的节点一分为二,会导致每个节点只有1/2满,这不满足B*树的要求了。所以B*树采取的策略是在本节点满后,继续插入兄弟节点(这也是为什么B*树需要在非叶子节点加一个兄弟间的链表),直到把兄弟节点也塞满,然后拉上兄弟节点一起凑份子,自己和兄弟节点各出资1/3成立新节点,这样的结果是3个节点刚好是2/3满,达到B*树的要求,皆大欢喜。
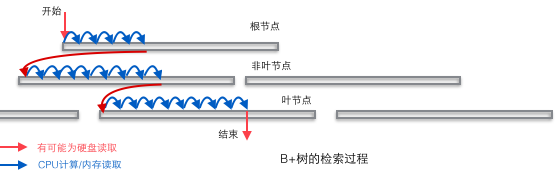
B+树适合作为数据库的基础结构,完全是因为计算机的内存-机械硬盘两层存储结构。内存可以完成快速的随机访问(随机访问即给出任意一个地址,要求返回这个地址存储的数据)但是容量较小。而硬盘的随机访问要经过机械动作(1磁头移动 2盘片转动),访问效率比内存低几个数量级,但是硬盘容量较大。典型的数据库容量大大超过可用内存大小,这就决定了在B+树中检索一条数据很可能要借助几次磁盘IO操作来完成。如下图所示:通常向下读取一个节点的动作可能会是一次磁盘IO操作,不过非叶节点通常会在初始阶段载入内存以加快访问速度。同时为提高在节点间横向遍历速度,真实数据库中可能会将图中蓝色的CPU计算/内存读取优化成二叉搜索树(InnoDB中的page directory机制)。
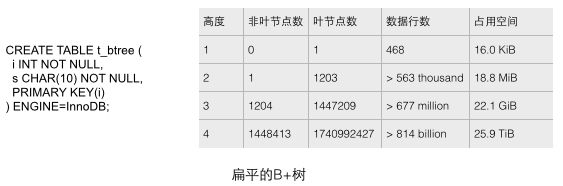
真实数据库中的B+树应该是非常扁平的,可以通过向表中顺序插入足够数据的方式来验证InnoDB中的B+树到底有多扁平。我们通过如下图的CREATE语句建立一个只有简单字段的测试表,然后不断添加数据来填充这个表。通过下图的统计数据(来源见参考文献1)可以分析出几个直观的结论,这几个结论宏观的展现了数据库里B+树的尺度。
1 每个叶子节点存储了468行数据,每个非叶子节点存储了大约1200个键值,这是一棵平衡的1200路搜索树!
2 对于一个22.1G容量的表,也只需要高度为3的B+树就能存储了,这个容量大概能满足很多应用的需要了。如果把高度增大到4,则B+树的存储容量立刻增大到25.9T之巨!
3 对于一个22.1G容量的表,B+树的高度是3,如果要把非叶节点全部加载到内存也只需要少于18.8M的内存(如何得出的这个结论?因为对于高度为2的树,1203个叶子节点也只需要18.8M空间,而22.1G从良表的高度是3,非叶节点1204个。同时我们假设叶子节点的尺寸是大于非叶节点的,因为叶子节点存储了行数据而非叶节点只有键和少量数据。),只使用如此少的内存就可以保证只需要一次磁盘IO操作就检索出所需的数据,效率是非常之高的。
2 Mysql的存储引擎和索引
可以说数据库必须有索引,没有索引则检索过程变成了顺序查找,O(n)的时间复杂度几乎是不能忍受的。我们非常容易想象出一个只有单关键字组成的表如何使用B+树进行索引,只要将关键字存储到树的节点即可。当数据库一条记录里包含多个字段时,一棵B+树就只能存储主键,如果检索的是非主键字段,则主键索引失去作用,又变成顺序查找了。这时应该在第二个要检索的列上建立第二套索引。 这个索引由独立的B+树来组织。有两种常见的方法可以解决多个B+树访问同一套表数据的问题,一种叫做聚簇索引(clustered index ),一种叫做非聚簇索引(secondary index)。这两个名字虽然都叫做索引,但这并不是一种单独的索引类型,而是一种数据存储方式。对于聚簇索引存储来说,行数据和主键B+树存储在一起,辅助键B+树只存储辅助键和主键,主键和非主键B+树几乎是两种类型的树。对于非聚簇索引存储来说,主键B+树在叶子节点存储指向真正数据行的指针,而非主键。
InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。
MyISM使用的是非聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
为了更形象说明这两种索引的区别,我们假想一个表如下图存储了4行数据。其中Id作为主索引,Name作为辅助索引。图示清晰的显示了聚簇索引和非聚簇索引的差异。
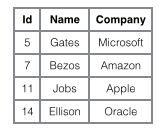
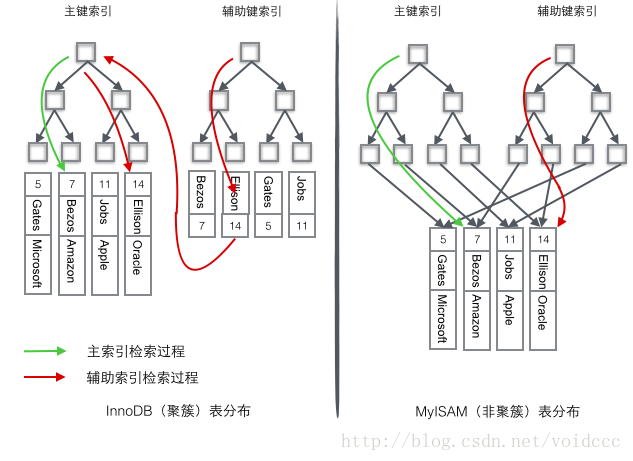
我们重点关注聚簇索引,看上去聚簇索引的效率明显要低于非聚簇索引,因为每次使用辅助索引检索都要经过两次B+树查找,这不是多此一举吗?聚簇索引的优势在哪?
1 由于行数据和叶子节点存储在一起,这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键Id来组织数据,获得数据更快。
2 辅助索引使用主键作为"指针" 而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作,使用主键值当作指针会让辅助索引占用更多的空间,换来的好处是InnoDB在移动行时无须更新辅助索引中的这个"指针"。也就是说行的位置(实现中通过16K的Page来定位,后面会涉及)会随着数据库里数据的修改而发生变化(前面的B+树节点分裂以及Page的分裂),使用聚簇索引就可以保证不管这个主键B+树的节点如何变化,辅助索引树都不受影响。
3 Page结构
如果说前面的内容偏向于解释原理,那后面就开始涉及具体实现了。
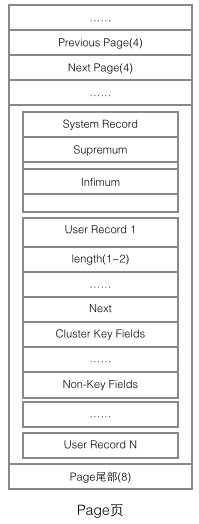
理解InnoDB的实现不得不提Page结构,Page是整个InnoDB存储的最基本构件,也是InnoDB磁盘管理的最小单位,与数据库相关的所有内容都存储在这种Page结构里。Page分为几种类型,常见的页类型有数据页(B-tree Node)Undo页(Undo Log Page)系统页(System Page) 事务数据页(Transaction System Page)等。单个Page的大小是16K(编译宏UNIV_PAGE_SIZE控制),每个Page使用一个32位的int值来唯一标识,这也正好对应InnoDB最大64TB的存储容量(16Kib * 2^32 = 64Tib)。一个Page的基本结构如下图所示:
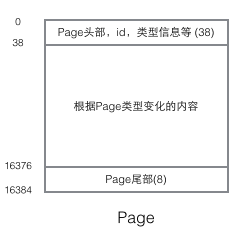
每个Page都有通用的头和尾,但是中部的内容根据Page的类型不同而发生变化。Page的头部里有我们关心的一些数据,下图把Page的头部详细信息显示出来:
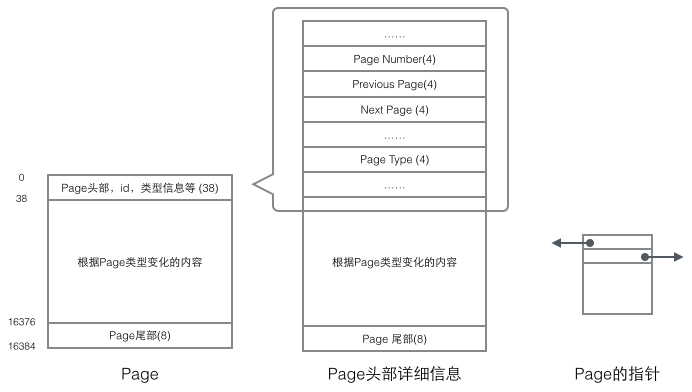
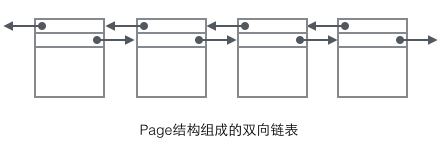
我们重点关注和数据组织结构相关的字段:Page的头部保存了两个指针,分别指向前一个Page和后一个Page,头部还有Page的类型信息和用来唯一标识Page的编号。根据这两个指针我们很容易想象出Page链接起来就是一个双向链表的结构。
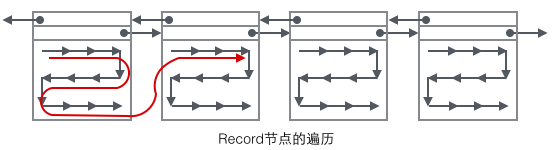
再看看Page的主体内容,我们主要关注行数据和索引的存储,他们都位于Page的User Records部分,User Records占据Page的大部分空间,User Records由一条一条的Record组成,每条记录代表索引树上的一个节点(非叶子节点和叶子节点)。在一个Page内部,单链表的头尾由固定内容的两条记录来表示,字符串形式的"Infimum"代表开头,"Supremum"代表结尾。这两个用来代表开头结尾的Record存储在System Records的段里,这个System Records和User Records是两个平行的段。InnoDB存在4种不同的Record,它们分别是1主键索引树非叶节点 2主键索引树叶子节点 3辅助键索引树非叶节点 4辅助键索引树叶子节点。这4种节点的Record格式有一些差异,但是它们都存储着Next指针指向下一个Record。后续我们会详细介绍这4种节点,现在只需要把Record当成一个存储了数据同时含有Next指针的单链表节点即可。
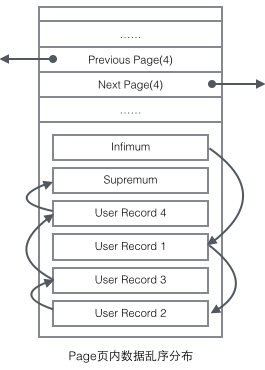
User Record在Page内以单链表的形式存在,最初数据是按照插入的先后顺序排列的,但是随着新数据的插入和旧数据的删除,数据物理顺序会变得混乱,但他们依然保持着逻辑上的先后顺序。
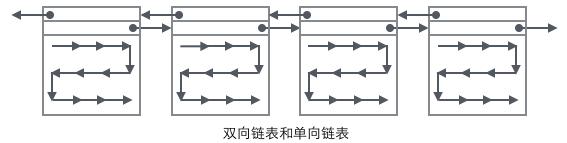
把User Record的组织形式和若干Page组合起来,就看到了稍微完整的形式。
现在看下如何定位一个Record:
1 通过根节点开始遍历一个索引的B+树,通过各层非叶子节点最终到达一个Page,这个Page里存放的都是叶子节点。
2 在Page内从"Infimum"节点开始遍历单链表(这种遍历往往会被优化),如果找到该键则成功返回。如果记录到达了"supremum",说明当前Page里没有合适的键,这时要借助Page的Next Page指针,跳转到下一个Page继续从"Infimum"开始逐个查找。
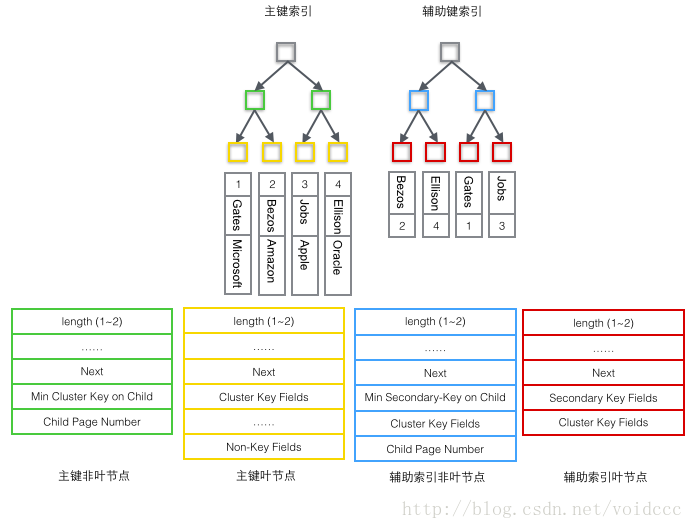
详细看下不同类型的Record里到底存储了什么数据,根据B+树节点的不同,User Record可以被分成四种格式,下图种按照颜色予以区分。
1 主索引树非叶节点(绿色)
1 子节点存储的主键里最小的值(Min Cluster Key on Child),这是B+树必须的,作用是在一个Page里定位到具体的记录的位置。
2 最小的值所在的Page的编号(Child Page Number),作用是定位Record。
2 主索引树叶子节点(黄色)
1 主键(Cluster Key Fields),B+树必须的,也是数据行的一部分
2 除去主键以外的所有列(Non-Key Fields),这是数据行的除去主键的其他所有列的集合。
这里的1和2两部分加起来就是一个完整的数据行。
3 辅助索引树非叶节点非(蓝色)
1 子节点里存储的辅助键值里的最小的值(Min Secondary-Key on Child),这是B+树必须的,作用是在一个Page里定位到具体的记录的位置。
2 主键值(Cluster Key Fields),非叶子节点为什么要存储主键呢?因为辅助索引是可以不唯一的,但是B+树要求键的值必须唯一,所以这里把辅助键的值和主键的值合并起来作为在B+树中的真正键值,保证了唯一性。但是这也导致在辅助索引B+树中非叶节点反而比叶子节点多了4个字节。(即下图中蓝色节点反而比红色多了4字节)
3 最小的值所在的Page的编号(Child Page Number),作用是定位Record。
4 辅助索引树叶子节点(红色)
1 辅助索引键值(Secondary Key Fields),这是B+树必须的。
2 主键值(Cluster Key Fields),用来在主索引树里再做一次B+树检索来找到整条记录。
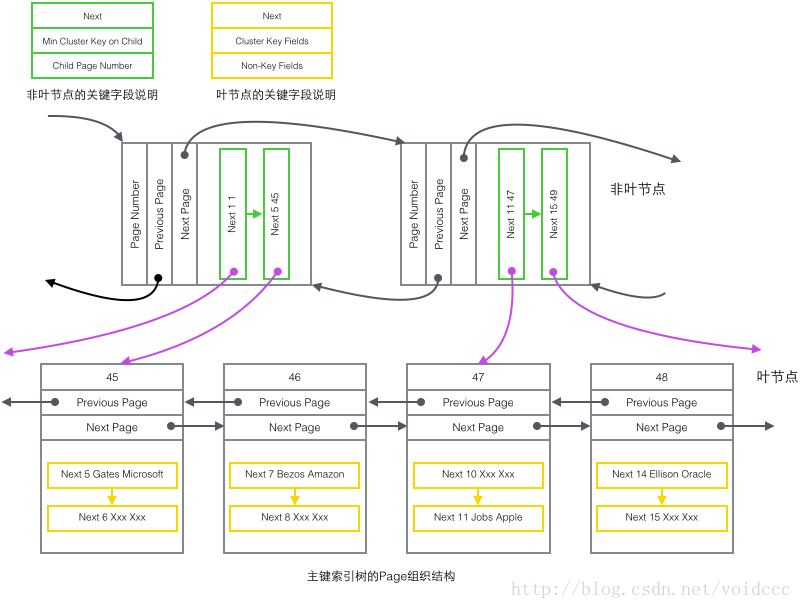
下面是本篇最重要的部分了,结合B+树的结构和前面介绍的4种Record的内容,我们终于可以画出一幅全景图。由于辅助索引的B+树与主键索引有相似的结构,这里只画出了主键索引树的结构图,只包含了"主键非叶节点"和"主键叶子节点"两种节点,也就是上图的的绿色和黄色的部分。
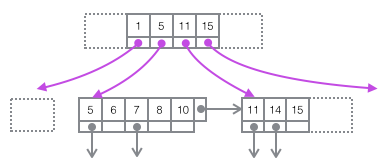
把上图还原成下面这个更简洁的树形示意图,这就是B+树的一部分。注意Page和B+树节点之间并没有一一对应的关系,Page只是作为一个Record的保存容器,它存在的目的是便于对磁盘空间进行批量管理,上图中的编号为47的Page在树形结构上就被拆分成了两个独立节点。
至此本篇就算结束了,本篇只是对InnoDB索引相关的数据结构和实现进行了一些梳理总结,并未涉及到Mysql的实战经验。这主要是基于几点原因:
1 原理是基石,只有充分了解InnoDB索引的工作方式,我们才有能力高效的使用好它。
2 原理性知识特别适合使用图示,我个人非常喜欢这种表达方式。
3 关于InnoDB优化,在《高性能Mysql》里有更加全面的介绍,对优化Mysql感兴趣的同学完全可以自己获取相关知识,我自己的积累还未达到能分享这些内容的地步。
另:对InnoDB实现有更多兴趣的同学可以看看Jeremy Cole的博客(参考文献三篇文章的来源),这位老兄曾先后在Mysql,Yahoo,Twitter,Google从事数据库相关工作,他的文章非常棒!
以上就是MySQL的InnoDB索引原理详解的内容,更多相关内容请关注PHP中文网(www.php.cn)!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 MySQL:世界上最受欢迎的数据库的简介
Apr 12, 2025 am 12:18 AM
MySQL:世界上最受欢迎的数据库的简介
Apr 12, 2025 am 12:18 AM
MySQL是一种开源的关系型数据库管理系统,主要用于快速、可靠地存储和检索数据。其工作原理包括客户端请求、查询解析、执行查询和返回结果。使用示例包括创建表、插入和查询数据,以及高级功能如JOIN操作。常见错误涉及SQL语法、数据类型和权限问题,优化建议包括使用索引、优化查询和分表分区。
 MySQL的位置:数据库和编程
Apr 13, 2025 am 12:18 AM
MySQL的位置:数据库和编程
Apr 13, 2025 am 12:18 AM
MySQL在数据库和编程中的地位非常重要,它是一个开源的关系型数据库管理系统,广泛应用于各种应用场景。1)MySQL提供高效的数据存储、组织和检索功能,支持Web、移动和企业级系统。2)它使用客户端-服务器架构,支持多种存储引擎和索引优化。3)基本用法包括创建表和插入数据,高级用法涉及多表JOIN和复杂查询。4)常见问题如SQL语法错误和性能问题可以通过EXPLAIN命令和慢查询日志调试。5)性能优化方法包括合理使用索引、优化查询和使用缓存,最佳实践包括使用事务和PreparedStatemen
 为什么要使用mysql?利益和优势
Apr 12, 2025 am 12:17 AM
为什么要使用mysql?利益和优势
Apr 12, 2025 am 12:17 AM
选择MySQL的原因是其性能、可靠性、易用性和社区支持。1.MySQL提供高效的数据存储和检索功能,支持多种数据类型和高级查询操作。2.采用客户端-服务器架构和多种存储引擎,支持事务和查询优化。3.易于使用,支持多种操作系统和编程语言。4.拥有强大的社区支持,提供丰富的资源和解决方案。
 apache怎么连接数据库
Apr 13, 2025 pm 01:03 PM
apache怎么连接数据库
Apr 13, 2025 pm 01:03 PM
Apache 连接数据库需要以下步骤:安装数据库驱动程序。配置 web.xml 文件以创建连接池。创建 JDBC 数据源,指定连接设置。从 Java 代码中使用 JDBC API 访问数据库,包括获取连接、创建语句、绑定参数、执行查询或更新以及处理结果。
 docker怎么启动mysql
Apr 15, 2025 pm 12:09 PM
docker怎么启动mysql
Apr 15, 2025 pm 12:09 PM
在 Docker 中启动 MySQL 的过程包含以下步骤:拉取 MySQL 镜像创建并启动容器,设置根用户密码并映射端口验证连接创建数据库和用户授予对数据库的所有权限
 MySQL的角色:Web应用程序中的数据库
Apr 17, 2025 am 12:23 AM
MySQL的角色:Web应用程序中的数据库
Apr 17, 2025 am 12:23 AM
MySQL在Web应用中的主要作用是存储和管理数据。1.MySQL高效处理用户信息、产品目录和交易记录等数据。2.通过SQL查询,开发者能从数据库提取信息生成动态内容。3.MySQL基于客户端-服务器模型工作,确保查询速度可接受。
 centos安装mysql
Apr 14, 2025 pm 08:09 PM
centos安装mysql
Apr 14, 2025 pm 08:09 PM
在 CentOS 上安装 MySQL 涉及以下步骤:添加合适的 MySQL yum 源。执行 yum install mysql-server 命令以安装 MySQL 服务器。使用 mysql_secure_installation 命令进行安全设置,例如设置 root 用户密码。根据需要自定义 MySQL 配置文件。调整 MySQL 参数和优化数据库以提升性能。
 centos7如何安装mysql
Apr 14, 2025 pm 08:30 PM
centos7如何安装mysql
Apr 14, 2025 pm 08:30 PM
优雅安装 MySQL 的关键在于添加 MySQL 官方仓库。具体步骤如下:下载 MySQL 官方 GPG 密钥,防止钓鱼攻击。添加 MySQL 仓库文件:rpm -Uvh https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm更新 yum 仓库缓存:yum update安装 MySQL:yum install mysql-server启动 MySQL 服务:systemctl start mysqld设置开机自启动
