

图文详解MySql中的事务

最近一直在做订单类的项目,使用了事务。我们的数据库选用的是MySql,存储引擎选用innoDB,innoDB对事务有着良好的支持。这篇文章我们一起来扒一扒事务相关的知识。
为什么要有事务?
事务广泛的运用于订单系统、银行系统等多种场景。如果有以下一个场景:A用户和B用户是银行的储户。现在A要给B转账500元。那么需要做以下几件事:
1. 检查A的账户余额>500元;
2. A账户扣除500元;
3. B账户增加500元;
正常的流程走下来,A账户扣了500,B账户加了500,皆大欢喜。那如果A账户扣了钱之后,系统出故障了呢?A白白损失了500,而B也没有收到本该属于他的500。以上的案例中,隐藏着一个前提条件:A扣钱和B加钱,要么同时成功,要么同时失败。事务的需求就在于此。
事务是什么?
与其给事务定义,不如说一说事务的特性。众所周知,事务需要满足ACID四个特性。
1. A(atomicity) 原子性。一个事务的执行被视为一个不可分割的最小单元。事务里面的操作,要么全部成功执行,要么全部失败回滚,不可以只执行其中的一部分。
2. C(consistency) 一致性。一个事务的执行不应该破坏数据库的完整性约束。如果上述例子中第2个操作执行后系统崩溃,保证A和B的金钱总计是不会变的。
3. I(isolation) 隔离性。通常来说,事务之间的行为不应该互相影响。然而实际情况中,事务相互影响的程度受到隔离级别的影响。文章后面会详述。
4. D(durability) 持久性。事务提交之后,需要将提交的事务持久化到磁盘。即使系统崩溃,提交的数据也不应该丢失。
事务的四种隔离级别
前文中提到,事务的隔离性受到隔离级别的影响。那么事务的隔离级别是什么呢?事务的隔离级别可以认为是事务的"自私"程度,它定义了事务之间的可见性。隔离级别分为以下几种:
1.READ UNCOMMITTED(未提交读)。在RU的隔离级别下,事务A对数据做的修改,即使没有提交,对于事务B来说也是可见的,这种问题叫脏读。这是隔离程度较低的一种隔离级别,在实际运用中会引起很多问题,因此一般不常用。
2.READ COMMITTED(提交读)。在RC的隔离级别下,不会出现脏读的问题。事务A对数据做的修改,提交之后会对事务B可见,举例,事务B开启时读到数据1,接下来事务A开启,把这个数据改成2,提交,B再次读取这个数据,会读到最新的数据2。在RC的隔离级别下,会出现不可重复读的问题。这个隔离级别是许多数据库的默认隔离级别。
3.REPEATABLE READ(可重复读)。在RR的隔离级别下,不会出现不可重复读的问题。事务A对数据做的修改,提交之后,对于先于事务A开启的事务是不可见的。举例,事务B开启时读到数据1,接下来事务A开启,把这个数据改成2,提交,B再次读取这个数据,仍然只能读到1。在RR的隔离级别下,会出现幻读的问题。幻读的意思是,当某个事务在读取某个范围内的值的时候,另外一个事务在这个范围内插入了新记录,那么之前的事务再次读取这个范围的值,会读取到新插入的数据。Mysql默认的隔离级别是RR,然而mysql的innoDB引擎间隙锁成功解决了幻读的问题。
4.SERIALIZABLE(可串行化)。可串行化是最高的隔离级别。这种隔离级别强制要求所有事物串行执行,在这种隔离级别下,读取的每行数据都加锁,会导致大量的锁征用问题,性能最差。
为了帮助理解四种隔离级别,这里举个例子。如图1,事务A和事务B先后开启,并对数据1进行多次更新。四个小人在不同的时刻开启事务,可能看到数据1的哪些值呢?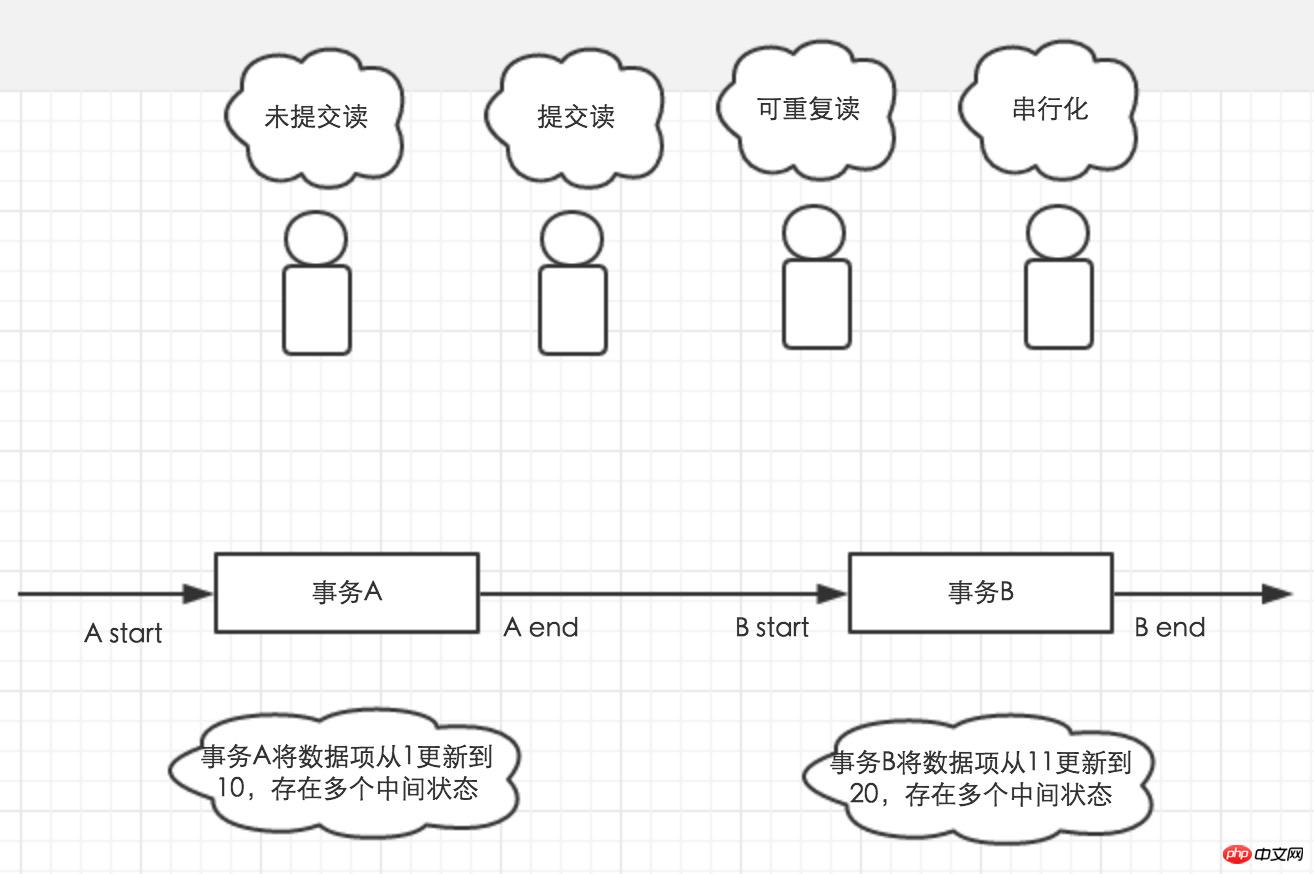
图1
第一个小人,可能读到1-20之间的任何一个。因为未提交读的隔离级别下,其他事务对数据的修改也是对当前事务可见的。第二个小人可能读到1,10和20,他只能读到其他事务已经提交了的数据。第三个小人读到的数据去决于自身事务开启的时间点。在事务开启时,读到的是多少,那么在事务提交之前读到的值就是多少。第四个小人,只有在A end 到B start之间开启,才有可能读到数据,而在事务A和事务B执行的期间是读不到数据的。因为第四小人读数据是需要加锁的,事务A和B执行期间,会占用数据的写锁,导致第四个小人等待锁。
图2罗列了不同隔离级别所面对的问题。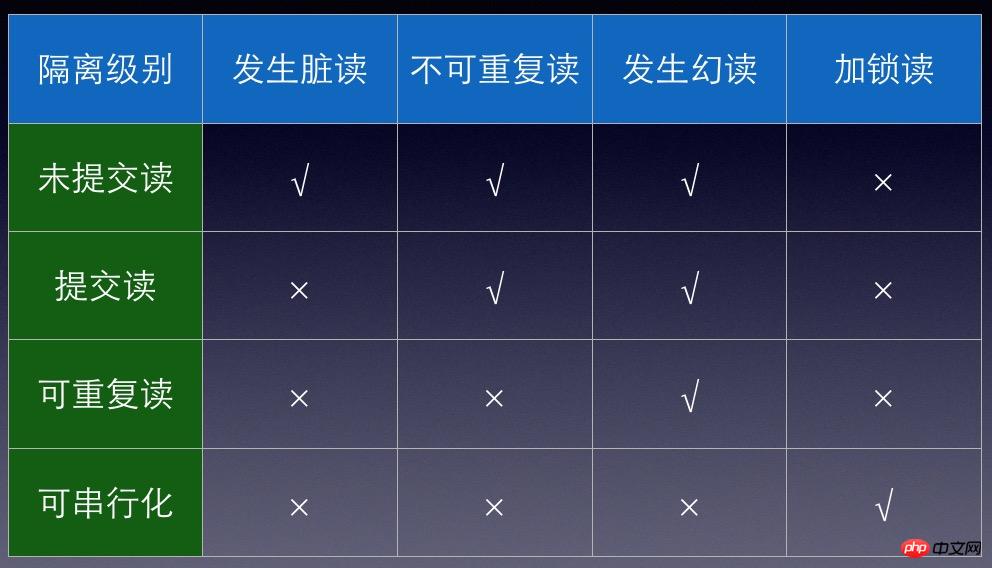
图2
很显然,隔离级别越高,它所带来的资源消耗也就越大(锁),因此它的并发性能越低。准确的说,在可串行化的隔离级别下,是没有并发的。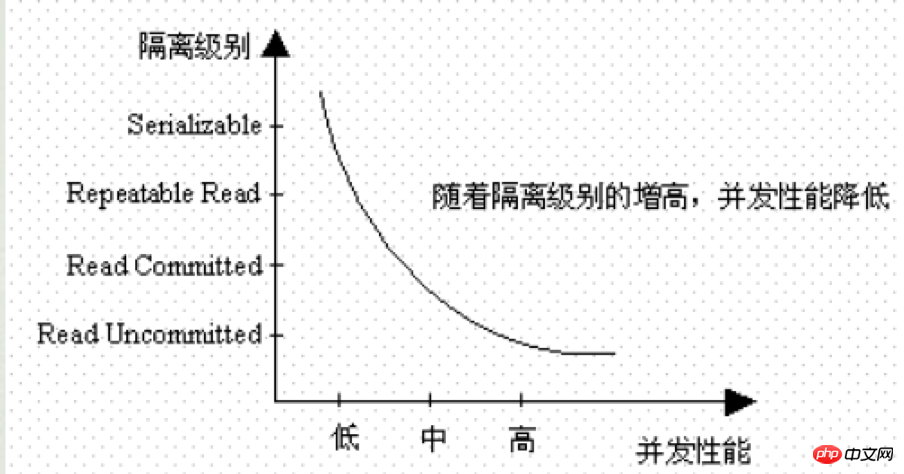
图3
MySql中的事务
事务的实现是基于数据库的存储引擎。不同的存储引擎对事务的支持程度不一样。mysql中支持事务的存储引擎有innoDB和NDB。innoDB是mysql默认的存储引擎,默认的隔离级别是RR,并且在RR的隔离级别下更进一步,通过多版本并发控制(MVCC,Multiversion Concurrency Control )解决不可重复读问题,加上间隙锁(也就是并发控制)解决幻读问题。因此innoDB的RR隔离级别其实实现了串行化级别的效果,而且保留了比较好的并发性能。
事务的隔离性是通过锁实现,而事务的原子性、一致性和持久性则是通过事务日志实现。说到事务日志,不得不说的就是redo和undo。
1.redo log
在innoDB的存储引擎中,事务日志通过重做(redo)日志和innoDB存储引擎的日志缓冲(InnoDB Log Buffer)实现。事务开启时,事务中的操作,都会先写入存储引擎的日志缓冲中,在事务提交之前,这些缓冲的日志都需要提前刷新到磁盘上持久化,这就是DBA们口中常说的“日志先行”(Write-Ahead Logging)。当事务提交之后,在Buffer Pool中映射的数据文件才会慢慢刷新到磁盘。此时如果数据库崩溃或者宕机,那么当系统重启进行恢复时,就可以根据redo log中记录的日志,把数据库恢复到崩溃前的一个状态。未完成的事务,可以继续提交,也可以选择回滚,这基于恢复的策略而定。
在系统启动的时候,就已经为redo log分配了一块连续的存储空间,以顺序追加的方式记录Redo Log,通过顺序IO来改善性能。所有的事务共享redo log的存储空间,它们的Redo Log按语句的执行顺序,依次交替的记录在一起。如下一个简单示例:
记录1:
记录2:
记录3:
记录4:
记录5:
2.undo log
undo log主要为事务的回滚服务。在事务执行的过程中,除了记录redo log,还会记录一定量的undo log。undo log记录了数据在每个操作前的状态,如果事务执行过程中需要回滚,就可以根据undo log进行回滚操作。单个事务的回滚,只会回滚当前事务做的操作,并不会影响到其他的事务做的操作。
以下是undo+redo事务的简化过程
假设有2个数值,分别为A和B,值为1,2
1. start transaction;
2. 记录 A=1 到undo log;
3. update A = 3;
4. 记录 A=3 到redo log;
5. 记录 B=2 到undo log;
6. update B = 4;
7. 记录B = 4 到redo log;
8. 将redo log刷新到磁盘
9. commit
在1-8的任意一步系统宕机,事务未提交,该事务就不会对磁盘上的数据做任何影响。如果在8-9之间宕机,恢复之后可以选择回滚,也可以选择继续完成事务提交,因为此时redo log已经持久化。若在9之后系统宕机,内存映射中变更的数据还来不及刷回磁盘,那么系统恢复之后,可以根据redo log把数据刷回磁盘。
所以,redo log其实保障的是事务的持久性和一致性,而undo log则保障了事务的原子性。
分布式事务
分布式事务的实现方式有很多,既可以采用innoDB提供的原生的事务支持,也可以采用消息队列来实现分布式事务的最终一致性。这里我们主要聊一下innoDB对分布式事务的支持。
如图,mysql的分布式事务模型。模型中分三块:应用程序(AP)、资源管理器(RM)、事务管理器(TM)。
应用程序定义了事务的边界,指定需要做哪些事务;
资源管理器提供了访问事务的方法,通常一个数据库就是一个资源管理器;
事务管理器协调参与了全局事务中的各个事务。
分布式事务采用两段式提交(two-phase commit)的方式。第一阶段所有的事务节点开始准备,告诉事务管理器ready。第二阶段事务管理器告诉每个节点是commit还是rollback。如果有一个节点失败,就需要全局的节点全部rollback,以此保障事务的原子性。
总结
什么时候需要使用事务呢?我想,只要业务中需要满足ACID的场景,都需要事务的支持。尤其在订单系统、银行系统中,事务是不可或缺的。这篇文章主要介绍了事务的特性,以及mysql innoDB对事务的支持。事务相关的知识远不止文中所说,本文仅作抛砖引玉,不足之处还望读者多多见谅。
以上是图文详解MySql中的事务的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 MySQL:世界上最受欢迎的数据库的简介
Apr 12, 2025 am 12:18 AM
MySQL:世界上最受欢迎的数据库的简介
Apr 12, 2025 am 12:18 AM
MySQL是一种开源的关系型数据库管理系统,主要用于快速、可靠地存储和检索数据。其工作原理包括客户端请求、查询解析、执行查询和返回结果。使用示例包括创建表、插入和查询数据,以及高级功能如JOIN操作。常见错误涉及SQL语法、数据类型和权限问题,优化建议包括使用索引、优化查询和分表分区。
 MySQL的位置:数据库和编程
Apr 13, 2025 am 12:18 AM
MySQL的位置:数据库和编程
Apr 13, 2025 am 12:18 AM
MySQL在数据库和编程中的地位非常重要,它是一个开源的关系型数据库管理系统,广泛应用于各种应用场景。1)MySQL提供高效的数据存储、组织和检索功能,支持Web、移动和企业级系统。2)它使用客户端-服务器架构,支持多种存储引擎和索引优化。3)基本用法包括创建表和插入数据,高级用法涉及多表JOIN和复杂查询。4)常见问题如SQL语法错误和性能问题可以通过EXPLAIN命令和慢查询日志调试。5)性能优化方法包括合理使用索引、优化查询和使用缓存,最佳实践包括使用事务和PreparedStatemen
 为什么要使用mysql?利益和优势
Apr 12, 2025 am 12:17 AM
为什么要使用mysql?利益和优势
Apr 12, 2025 am 12:17 AM
选择MySQL的原因是其性能、可靠性、易用性和社区支持。1.MySQL提供高效的数据存储和检索功能,支持多种数据类型和高级查询操作。2.采用客户端-服务器架构和多种存储引擎,支持事务和查询优化。3.易于使用,支持多种操作系统和编程语言。4.拥有强大的社区支持,提供丰富的资源和解决方案。
 apache怎么连接数据库
Apr 13, 2025 pm 01:03 PM
apache怎么连接数据库
Apr 13, 2025 pm 01:03 PM
Apache 连接数据库需要以下步骤:安装数据库驱动程序。配置 web.xml 文件以创建连接池。创建 JDBC 数据源,指定连接设置。从 Java 代码中使用 JDBC API 访问数据库,包括获取连接、创建语句、绑定参数、执行查询或更新以及处理结果。
 docker怎么启动mysql
Apr 15, 2025 pm 12:09 PM
docker怎么启动mysql
Apr 15, 2025 pm 12:09 PM
在 Docker 中启动 MySQL 的过程包含以下步骤:拉取 MySQL 镜像创建并启动容器,设置根用户密码并映射端口验证连接创建数据库和用户授予对数据库的所有权限
 MySQL的角色:Web应用程序中的数据库
Apr 17, 2025 am 12:23 AM
MySQL的角色:Web应用程序中的数据库
Apr 17, 2025 am 12:23 AM
MySQL在Web应用中的主要作用是存储和管理数据。1.MySQL高效处理用户信息、产品目录和交易记录等数据。2.通过SQL查询,开发者能从数据库提取信息生成动态内容。3.MySQL基于客户端-服务器模型工作,确保查询速度可接受。
 laravel入门实例
Apr 18, 2025 pm 12:45 PM
laravel入门实例
Apr 18, 2025 pm 12:45 PM
Laravel 是一款 PHP 框架,用于轻松构建 Web 应用程序。它提供一系列强大的功能,包括:安装: 使用 Composer 全局安装 Laravel CLI,并在项目目录中创建应用程序。路由: 在 routes/web.php 中定义 URL 和处理函数之间的关系。视图: 在 resources/views 中创建视图以呈现应用程序的界面。数据库集成: 提供与 MySQL 等数据库的开箱即用集成,并使用迁移来创建和修改表。模型和控制器: 模型表示数据库实体,控制器处理 HTTP 请求。
 centos7如何安装mysql
Apr 14, 2025 pm 08:30 PM
centos7如何安装mysql
Apr 14, 2025 pm 08:30 PM
优雅安装 MySQL 的关键在于添加 MySQL 官方仓库。具体步骤如下:下载 MySQL 官方 GPG 密钥,防止钓鱼攻击。添加 MySQL 仓库文件:rpm -Uvh https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm更新 yum 仓库缓存:yum update安装 MySQL:yum install mysql-server启动 MySQL 服务:systemctl start mysqld设置开机自启动
