
一个 Buffer 对象是固定数量的数据的容器。通道是 I/O 传输发生时通过的入口,而缓冲区是这些数据传输的来源或目标。
所有的缓冲区都具有四个属性来 供关于其所包含的数据元素的信息。
capacity(容量):缓冲区能够容纳数据的最大值,创建缓冲区后不能改变。
limit(上界):缓冲区的第一个不能被读或写的元素。或者,缓冲区现存元素的计数。
mark(标记):一个备忘位置。调用 mark() 来设定 mark=postion。调用 reset() 设定position= mark。标记在设定前是未定义的(undefined)。
这四个属性之间总是 循以下关系:
0 <= mark <= position <= limit <= capacity
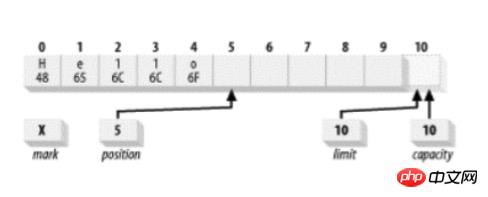
下图是一个新创建的 ByteBuffer :

位置被设为 0,而且容量和上界被设为 10, 好经过缓冲区能够容纳的最后一个字节。 标记最初未定义。容量是固定的,但另外的三个属性可以在使用缓冲区时改变。
如下是 Buffer 的方法签名:
public abstract class Buffer {
public final int capacity() {
}
public final int position() {
}
public final Buffer position(int newPosition) {
}
public final int limit() {
}
public final Buffer limit(int newLimit) {
}
public final Buffer mark() {
}
public final Buffer reset() {
}
public final Buffer clear() {
}
public final Buffer flip() {
}
public final Buffer rewind() {
}
public final int remaining() {
}
public final boolean hasRemaining() {
}
public abstract boolean isReadOnly();
public abstract boolean hasArray();
public abstract Object array();
public abstract int arrayOffset();
public abstract boolean isDirect();
}上文所列出的的 Buffer API 并没有包括 get() 或 put() 函数。每一个 Buffer 类都有这两个函数,但它们所采用的参数类型,以及它们返回的数据类型,对每个子类来说都是唯一的,所以它们不能在顶层 Buffer 类中被抽象地声明。
如下是 ByteBuffer 的声明:
public abstract class ByteBuffer extends Buffer implements Comparable
{
// This is a partial API listing
public abstract byte get( );
public abstract byte get (int index);
public abstract ByteBuffer put (byte b);
public abstract ByteBuffer put (int index, byte b);
}一个例子看 ByteBuffer 的存储:
buffer.put((byte)'H').put((byte)'e').put((byte)'l').put((byte)'l').put((byte)'o');
如果在进行如下操作:
buffer.put(0,(byte)'M').put((byte)'w');

当缓冲区写满了,要把内容读出来,我们需要翻转缓冲区,可以调用 flip 方法,如下是 ByteBuffer 当中的 flip 方法:
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
rewind()函数与 flip()相似,但不影响上界属性。它只是将位置值设回 0。您可以使用 rewind()后 ,重读已经被翻转的缓冲区中的数据。
hasRemaining() 方法会返回当前是否到达缓冲区的上界。
remaining() 方法会返回到达上界的距离。
缓冲区的标记在 mark() 函数被调用之前是未定义的,调用时标记被设为当前位置的值。
reset() 函数将位置设为当前的标记值。如果标记值未定义,调用 reset()将导致 InvalidMarkException 异常。
rewind( ),clear( ),以及 flip( )总是抛弃标记,即设置成 -1。
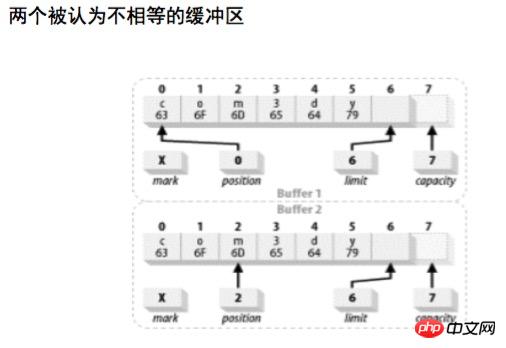
两个缓冲区被认为相等的充要条件是:
两个对象类型相同。包含不同数据类型的buffer 远不会相等,而且buffer 绝不会等于非 buffer 对象。
两个对象都剩余同样数量的元素。Buffer 的容量不需要相同,而且缓冲区中剩余数据的索引也不必相同。但每个缓冲区中剩余元素的数目(从位置到上界)必须相同。
在每个缓冲区中应被Get()函数返回的剩余数据元素序列必须一致。

//分配一个容量为 100 个 char 变量的 Charbuffer CharBuffer charBuffer = CharBuffer.allocate (100); char [] myArray = new char [100]; CharBuffer charbuffer = CharBuffer.wrap (myArray); //这段代码构造了一个新的缓冲区对象,但数据元素会存在于数组中。 这意味着通过调用 put()函数造成的对缓冲区的改动会直接影响这个数组,而且对这个数组的任何改动也会对这 个缓冲区对象可见。 CharBuffer.wrap(array, offset, length);可以指定 position 和 length
通过 allocate() 或者 wrap() 函数创建的缓冲区通常都是间接的,间接的缓冲区使用备份数组。 hasArray() 返回这个缓冲区是否有一个可存取的备份数组。
一些复制缓冲区的 api :
public abstract class CharBuffer extends Buffer implements CharSequence, Comparable {
// This is a partial API listing
public abstract CharBuffer duplicate( );
public abstract CharBuffer asReadOnlyBuffer( );
public abstract CharBuffer slice( );
}duplicate() 函数创建了一个与原始缓冲区相似的新缓冲区。两个缓冲区共享数据元素,拥有同样的容量,但每个缓冲区拥有各自的位置,上界和标记属性。对一个缓冲区内的数据元素所做的改变会反映在另外一个缓冲区上。如果原始的缓冲区为只读,或者为直接缓冲区,新的缓冲区将继承这些属性。
如下示例:
public static void main(String[] args) {
CharBuffer buffer = CharBuffer.allocate(8);
buffer.position(3).limit(6).mark().position(5);
CharBuffer dupeBuffer = buffer.duplicate();
System.out.println(dupeBuffer.position());
System.out.println(dupeBuffer.limit());
dupeBuffer.clear();
System.out.println(dupeBuffer.position());
System.out.println(dupeBuffer.limit());
}
//out
5
6
0
8asReadOnlyBuffer() 函数来生成一个只读的缓冲区图。
代码说明如下:
public static void main(String[] args) {
CharBuffer buffer = CharBuffer.allocate(8);
CharBuffer dupeBuffer = buffer.asReadOnlyBuffer();
System.out.println(dupeBuffer.isReadOnly());
dupeBuffer.put('S');//只读buffer调用抛出异常
}
//out
true
Exception in thread "main" java.nio.ReadOnlyBufferException
at java.nio.HeapCharBufferR.put(HeapCharBufferR.java:172)
at nio.test.TestMain.main(TestMain.java:10)slice() 创建一个从原始缓冲区的当前位置开始的新缓冲 区,并且其容量是原始缓冲区的剩余元素数量(limit-position)。这个新缓冲区与原始 缓冲区共享一段数据元素子序列。分出来的缓冲区也会继承只读和直接属性。
public static void main(String[] args) {
CharBuffer buffer = CharBuffer.allocate(8);
buffer.position(3).limit(5);
CharBuffer sliceBuffer = buffer.slice();
}
在 java.nio 中,字节顺序由 ByteOrder 类封装。
ByteOrder.nativeOrder() 方法返回 JVM 运行的硬件平台字节顺序。
只有字节缓冲区有资格参与 I/O 操作。
I/O 操作的目标内存区域必须是连续的字节序列。
直接缓冲区被用于与通道和固有 I/O 例程交互。
直接字节缓冲区通常是 I/O 操作最好的选择。直接字节缓冲区支持 JVM 可用的最高效 I/O 机制。非直接字节缓冲区可以被传递给通道,但是这样可能导致性能耗。通常非直接缓冲不可能成为一个本地 I/O 操作的目标。如果向一个通道中传递一个非直接 ByteBuffer 对象用于写入会每次隐含调用下面的操作:
创建一个临时的直接 ByteBuffer 对象。
将非直接缓冲区的内容复制到直接临时缓冲中。
使用直接临时缓冲区执行低层次 I/O 操作。
直接临时缓冲区对象离开作用域,并最终成为被回的无用数据。
直接缓冲区时 I/O 的最佳选择,但可能比创建非直接缓冲区要花费更高的成本。直接缓冲区使用的内存是通过调用本地操作系统方面的代码分配的, 过了标准 JVM 。
ByteBuffer.allocateDirect() 创建直接缓冲区。isDirect() 返回是否直接缓冲区。
视图缓冲区通过已存在的缓冲区对象实例的工方法来创建。这种图对象维护它自己的属性,容量,位置,上界和标记,但是和原来的缓冲区共享数据元素。
ByteBuffer 类允许创建图来将 byte 型缓冲区字节数据映射为其它的原始数据类型。
public abstract CharBuffer asCharBuffer( ); public abstract ShortBuffer asShortBuffer( ); public abstract IntBuffer asIntBuffer( ); public abstract LongBuffer asLongBuffer( ); public abstract FloatBuffer asFloatBuffer( ); public abstract DoubleBuffer asDoubleBuffer( );
看如下一个例子的示意图:
ByteBuffer byteBuffer = ByteBuffer.allocate (7).order (ByteOrder.BIG_ENDIAN); CharBuffer charBuffer = byteBuffer.asCharBuffer( );

public class BufferCharView {
public static void main (String [] argv) throws Exception {
ByteBuffer byteBuffer = ByteBuffer.allocate (7).order (ByteOrder.BIG_ENDIAN);
CharBuffer charBuffer = byteBuffer.asCharBuffer( );
// Load the ByteBuffer with some bytes
byteBuffer.put (0, (byte)0);
byteBuffer.put (1, (byte)'H');
byteBuffer.put (2, (byte)0);
byteBuffer.put (3, (byte)'i');
byteBuffer.put (4, (byte)0);
byteBuffer.put (5, (byte)'!');
byteBuffer.put (6, (byte)0);
println (byteBuffer);
println (charBuffer);
}
// Print info about a buffer
private static void println (Buffer buffer) {
System.out.println ("pos=" + buffer.position() + ", limit=" +
buffer.limit() + ", capacity=" + buffer.capacity() + ": '" + buffer.toString( ) + "'");
}
}
//运行 BufferCharView 程序的输出是:
//pos=0, limit=7, capacity=7: 'java.nio.HeapByteBuffer[pos=0 lim=7 cap=7]'
//pos=0, limit=3, capacity=3: 'Hi!ByteBuffer 类为每一种原始数据类型 供了存取的和转化的方法:
public abstract class ByteBuffer extends Buffer implements Comparable {
public abstract char getChar();
public abstract char getChar(int index);
public abstract short getShort();
public abstract short getShort(int index);
public abstract int getInt();
public abstract int getInt(int index);
public abstract long getLong();
public abstract long getLong(int index);
public abstract float getFloat();
public abstract float getFloat(int index);
public abstract double getDouble();
public abstract double getDouble(int index);
public abstract ByteBuffer putChar(char value);
public abstract ByteBuffer putChar(int index, char value);
public abstract ByteBuffer putShort(short value);
public abstract ByteBuffer putShort(int index, short value);
public abstract ByteBuffer putInt(int value);
public abstract ByteBuffer putInt(int index, int value);
public abstract ByteBuffer putLong(long value);
public abstract ByteBuffer putLong(int index, long value);
public abstract ByteBuffer putFloat(float value);
public abstract ByteBuffer putFloat(int index, float value);
public abstract ByteBuffer putDouble(double value);
public abstract ByteBuffer putDouble(int index, double value);
}假如一个 bytebuffer 处于如下状态:
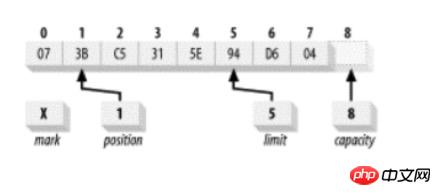
那么 int value = buffer.getInt();
实际的返回值取决于缓冲区的当前的比特排序(byte-order)设置。更具体的写法是:
int value = buffer.order (ByteOrder.BIG_ENDIAN).getInt( );
这将会返回值 0x3BC5315E,同时:
int value = buffer.order (ByteOrder.LITTLE_ENDIAN).getInt( );
返回值 0x5E31C53B
如果您试图获取的原始类型需要比缓冲区中存在的字节数更多的字节,会抛出 BufferUnderflowException。
以上是Java NIO之缓冲区的代码图文详解的详细内容。更多信息请关注PHP中文网其他相关文章!





















