

Python中memcached的操作详解(图文)

前言
许多Web应用都将数据保存到MySQL这样的关系型数据库管理系统中,应用服务器从中读取数据并在浏览器中显示。 但随着数据量的增大、访问的集中,就会出现数据库的负担加重、数据库响应恶化、 网站显示延迟等不良影响。分布式缓存是优化网站性能的重要手段,大量站点都通过可伸缩的服务器集群提供大规模热点数据缓存服务。通过缓存数据库查询结果,减少数据库访问次数,可以显著提高动态Web应用的速度和可扩展性。业界常用的有redis、memcached等,今天要讲的就是在python项目中如何使用memcached缓存服务。
memcached简介
memcached是一款开源、高性能、分布式内存对象缓存系统,可应用各种需要缓存的场景,其主要目的是通过降低对Database的访问来加速web应用程序。
memcached本身其实不提供分布式解决方案。在服务端,memcached集群环境实际就是一个个memcached服务器的堆积,环境搭建较为简单;cache的分布式主要是在客户端实现,通过客户端的路由处理来达到分布式解决方案的目的。客户端做路由的原理非常简单,应用服务器在每次存取某key的value时,通过路由算法把key映射到某台memcached服务器nodeA上,因此这个key所有操作都在nodeA上进行。只要服务器还缓存着该数据,就能保证缓存命中。 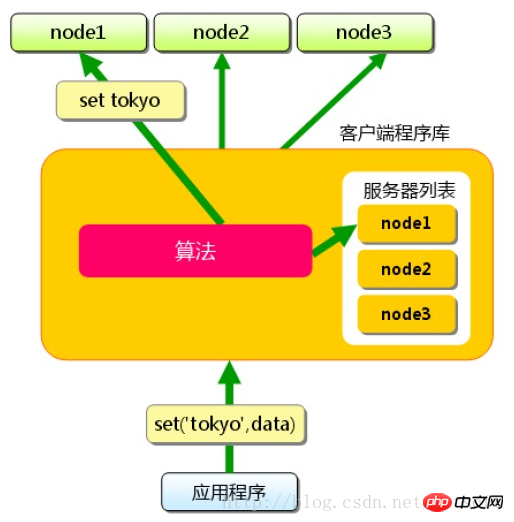
路由算法
简单路由算法
简单路由算法,使用余数Hash:用缓存数据key的hash值,除以服务器的数目,余数为服务器列表的下表编号。这个算法可以让缓存数据在整个memcached集群中均匀的分布,也能满足大多数的缓存路由需求。
但是,当memcached集群要扩容的时候,就会引发问题。例如:网站需要将3台缓存服务器扩容成4台。在更改服务器列表后,若仍使用余数hash,很容易就计算出,75%的请求不能命中缓存。随着服务器集群规模增大,不能命中的比率就越高。
1%3 = 1 1%4 = 1 2%3 = 2 2%4 = 2 3%3 = 0 3%4 = 3 4%4 = 1 4%4 = 0 #以此类推
这样扩容操作风险极大,可能给数据库带来很大的瞬时压力,甚至可能导致数据库崩溃。解决这个问题有2个方法:1、在访问低谷进行扩容,在扩容后预热数据;2、使用更优的路由算法。目前使用较多的是一致性Hash算法。
一致性哈希
memcached客户端可采用一致性hash算法作为路由策略,如图,相对于一般hash(如简单取模)的算法,一致性hash算法除了计算key的hash值外,还会计算每个server对应的hash值,然后将这些hash值映射到一个有限的值域上(比如0~2^32)。通过寻找hash值大于hash(key)的最小server作为存储该key数据的目标server。如果找不到,则直接把具有最小hash值的server作为目标server。同时,一定程度上,解决了扩容问题,增加或删除单个节点,对于整个集群来说,不会有大的影响。 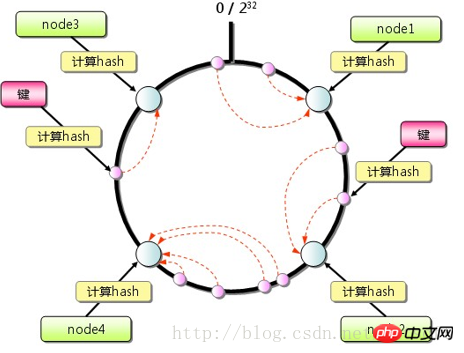
虚拟层
一致性hash也不是完美的,在扩容时可能导致负载不均衡的问题。最近版本,增加了虚拟节点的设计,进一步提升了可用性。在扩容时,较为均匀的影响集群中已经存在的服务器,均匀的分摊负载。此处不再详述。
内存管理
存储方式
为了提高性能,memcached中保存的数据都存储在memcached内置的内存存储空间中。由于数据仅存在于内存中,因此重启memcached、重启操作系统会导致全部数据消失。另外,缓存的内容容量达到指定值之后,就基于LRU(Least Recently Used)算法自动删除不使用的缓存。memcached本身是为缓存而设计的服务,因此并没有过多考虑数据的永久性问题。
内存结构
memcached仅支持基础的key-value键值对类型数据存储。在memcached内存结构中有两个非常重要的概念:slab和chunk。
slab是一个内存块,它是memcached一次申请内存的最小单位。在启动memcached的时候一般会使用参数-m指定其可用内存,但是并不是在启动的那一刻所有的内存就全部分配出去了,只有在需要的时候才会去申请,而且每次申请一定是一个slab。Slab的大小固定为1M(1048576 Byte),一个slab由若干个大小相等的chunk组成。每个chunk中都保存了一个item结构体、一对key和value。
虽然在同一个slab中chunk的大小相等的,但是在不同的slab中chunk的大小并不一定相等,在memcached中按照chunk的大小不同,可以把slab分为很多种类(class),默认情况下memcached把slab分为40类(class1~class40),在class 1中,chunk的大小为80字节,由于一个slab的大小是固定的1048576字节(1M),因此在class1中最多可以有13107个chunk(也就是这个slab能存最多13107个小于80字节的key-value数据)。 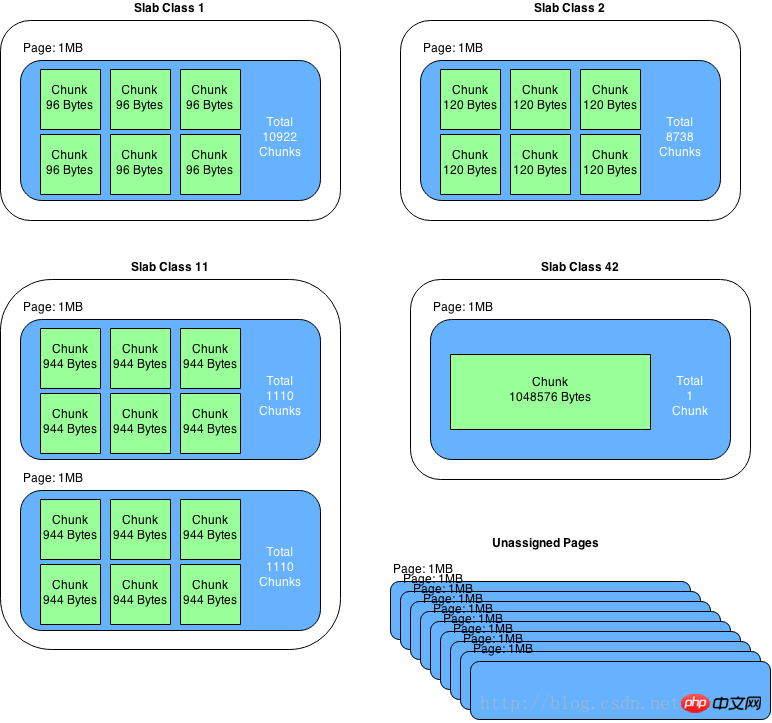
memcached内存管理采取预分配、分组管理的方式,分组管理就是我们上面提到的slab class,按照chunk的大小slab被分为很多种类。内存预分配过程是怎样的呢?向memcached添加一个item时候,memcached首先会根据item的大小,来选择最合适的slab class:例如item的大小为190字节,默认情况下class 4的chunk大小为160字节显然不合适,class 5的chunk大小为200字节,大于190字节,因此该item将放在class 5中(显然这里会有10字节的浪费是不可避免的),计算好所要放入的chunk之后,memcached会去检查该类大小的chunk还有没有空闲的,如果没有,将会申请1M(1个slab)的空间并划分为该种类chunk。例如我们第一次向memcached中放入一个190字节的item时,memcached会产生一个slab class 2(也叫一个page),并会用去一个chunk,剩余5241个chunk供下次有适合大小item时使用,当我们用完这所有的5242个chunk之后,下次再有一个在160~200字节之间的item添加进来时,memcached会再次产生一个class 5的slab(这样就存在了2个pages)。
注意事项
chunk是在page里面划分的,而page固定为1m,所以chunk最大不能超过1m。
chunk实际占用内存要加48B,因为chunk数据结构本身需要占用48B。
如果用户数据大于1m,则memcached会将其切割,放到多个chunk内。
已分配出去的page不能回收。
-对于key-value信息,最好不要超过1m的大小;同时信息长度最好相对是比较均衡稳定的,这样能够保障最大限度的使用内存;同时,memcached采用的LRU清理策略,合理甚至过期时间,提高命中率。
使用场景
key-value能满足需求的前提下,使用memcached分布式集群是较好的选择,搭建与操作使用都比较简单;分布式集群在单点故障时,只影响小部分数据异常,目前还可以通过Magent缓存代理模式,做单点备份,提升高可用;整个缓存都是基于内存的,因此响应时间是很快,不需要额外的序列化、反序列化的程序,但同时由于基于内存,数据没有持久化,集群故障重启数据无法恢复。高版本的memcached已经支持CAS模式的原子操作,可以低成本的解决并发控制问题。
安装启动
$ sudo apt-get install memcached $ memcached -m 32 -p 11211 -d # memcached将会以守护程序的形式启动 memcached(-d),为其分配32M内存(-m 32),并指定监听 localhost的11211端口。
python操作memcached
在python中可通过memcache库来操作memcached,这个库使用很简单,声明一个client就可以读写memcached缓存了。
python访问memcached
#!/usr/bin/env pythonimport memcache
mc = memcache.Client(['127.0.0.1:12000'],debug=0)
mc.set("some_key", "Some value")
value = mc.get("some_key")
mc.set("another_key", 3)
mc.delete("another_key")
mc.set("key", "1") # note that the key used for incr/decr must be a string.
mc.incr("key")
mc.decr("key")然而,python-memcached默认的路由策略没有使用一致性哈希。
def _get_server(self, key):
if isinstance(key, tuple):
serverhash, key = key
else:
serverhash = serverHashFunction(key)
if not self.buckets:
return None, None
for i in range(Client._SERVER_RETRIES):
server = self.buckets[serverhash % len(self.buckets)]
if server.connect():
# print("(using server %s)" % server,)
return server, key
serverhash = serverHashFunction(str(serverhash) + str(i))
return None, None从源码中可以看到:server = self.buckets[serverhash % len(self.buckets)],只是根据key进行了简单的取模。我们可以通过重写_get_server方法,让python-memcached支持一致性哈希。
import memcacheimport typesfrom hash_ring import HashRingclass MemcacheRing(memcache.Client):
"""Extends python-memcache so it uses consistent hashing to
distribute the keys.
"""
def init(self, servers, *k, **kw):
self.hash_ring = HashRing(servers)
memcache.Client.init(self, servers, *k, **kw)
self.server_mapping = {}
for server_uri, server_obj in zip(servers, self.servers):
self.server_mapping[server_uri] = server_obj
def _get_server(self, key):
if type(key) == types.TupleType:
return memcache.Client._get_server(key)
for i in range(self._SERVER_RETRIES):
iterator = self.hash_ring.iterate_nodes(key)
for server_uri in iterator:
server_obj = self.server_mapping[server_uri]
if server_obj.connect():
return server_obj, key
return None, Nonetorando项目中使用memcached
这里采用的策略是:1. 应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。2. 应用程序从cache中取数据,取到后返回。缓存更新是一个很复杂的问题,一般是先把数据存到数据库中,成功后,再让缓存失效。后面会再写文单独讨论memcached缓存更新的问题。
代码
# coding: utf-8import sysimport tornado.ioloopimport tornado.webimport loggingimport memcacheimport jsonimport urllib# 初始化memcache clientmc = memcache.Client(['127.0.0.1:11211'], debug=0)
mc_prefix = 'demo'class BaseHandler(tornado.web.RequestHandler):
""" 把缓存处理抽象到BaseHandler基类 """
USE_CACHE = False # 控制是否使用缓存
def format_args(self):
arg_list = []
for a in self.request.arguments:
for value in self.request.arguments[a]:
arg_list.append('%s=%s' % (a, urllib.quote(value.replace(' ', ''))))
# 根据请求的URL产生key
arg_list.sort()
key = '%s?%s' % (self.request.path, '&'.join(arg_list)) if arg_list else self.request.path
key = '%s_%s' % (mc_prefix, key)
# key太长,不进行缓存处理
if len(key) > 250:
logging.error('key out of length: %s', key)
return None
return key def get(self, *args, **kwargs):
if self.USE_CACHE:
try:
# 根据请求获取key
self.key = self.format_args()
if self.key:
data = mc.get(self.key)
# 若缓存命中,则直接返回数据
if data:
logging.info('get data from memecahce')
self.finish(data)
return
except Exception, e:
logging.exception(e)
# 若未命中缓存,调用do_get处理请求,获取数据
data = self.do_get()
data_str = json.dumps(data)
# 把成功获取到的数据,放入memcache缓存
if self.USE_CACHE and data and data.get('result', -1) == 0 and self.key:
try:
mc.set(self.key, data_str, 60)
except Exception, e:
logging.exception(e)
self.finish(data_str) def do_get(self):
return Noneclass DemoHandler(BaseHandler):
USE_CACHE = True
def do_get(self):
a = self.get_argument('a', 'test')
b = self.get_argument('b', 'test')
# 访问数据库获取数据,此处略去
data = {'result': 0, 'a': a, 'b': b} return datadef make_app():
return tornado.web.Application([
(r"/", DemoHandler),
])if name == "main":
logging.basicConfig(stream=sys.stdout, level=logging.INFO,
format='%(asctime)s %(levelno)s %(message)s',
)
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()测试结果
在浏览器访问http://127.0.0.1:8888/?a=1&b=3,终端打印的log如下:
2017-02-21 22:45:05,987 20 304 GET /?a=1&b=2 (127.0.0.1) 3.11ms 2017-02-21 22:45:07,427 20 get data from memecahce 2017-02-21 22:45:07,427 20 304 GET /?a=1&b=2 (127.0.0.1) 0.71ms 2017-02-21 22:45:10,350 20 200 GET /?a=1&b=3 (127.0.0.1) 0.82ms 2017-02-21 22:45:13,586 20 get data from memecahce
从日志可以看到,缓存命中的情况。
小结
本文介绍了memcached的路由算法、内存管理、使用场景等基本概念,然后举例说明了在python项目中如何使用memcached缓存。缓存更新的问题还需要进一步分析讨论。
以上是Python中memcached的操作详解(图文)的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 PHP和Python:解释了不同的范例
Apr 18, 2025 am 12:26 AM
PHP和Python:解释了不同的范例
Apr 18, 2025 am 12:26 AM
PHP主要是过程式编程,但也支持面向对象编程(OOP);Python支持多种范式,包括OOP、函数式和过程式编程。PHP适合web开发,Python适用于多种应用,如数据分析和机器学习。
 在PHP和Python之间进行选择:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之间进行选择:指南
Apr 18, 2025 am 12:24 AM
PHP适合网页开发和快速原型开发,Python适用于数据科学和机器学习。1.PHP用于动态网页开发,语法简单,适合快速开发。2.Python语法简洁,适用于多领域,库生态系统强大。
 Python vs. JavaScript:学习曲线和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:学习曲线和易用性
Apr 16, 2025 am 12:12 AM
Python更适合初学者,学习曲线平缓,语法简洁;JavaScript适合前端开发,学习曲线较陡,语法灵活。1.Python语法直观,适用于数据科学和后端开发。2.JavaScript灵活,广泛用于前端和服务器端编程。
 vscode 扩展是否是恶意的
Apr 15, 2025 pm 07:57 PM
vscode 扩展是否是恶意的
Apr 15, 2025 pm 07:57 PM
VS Code 扩展存在恶意风险,例如隐藏恶意代码、利用漏洞、伪装成合法扩展。识别恶意扩展的方法包括:检查发布者、阅读评论、检查代码、谨慎安装。安全措施还包括:安全意识、良好习惯、定期更新和杀毒软件。
 visual studio code 可以用于 python 吗
Apr 15, 2025 pm 08:18 PM
visual studio code 可以用于 python 吗
Apr 15, 2025 pm 08:18 PM
VS Code 可用于编写 Python,并提供许多功能,使其成为开发 Python 应用程序的理想工具。它允许用户:安装 Python 扩展,以获得代码补全、语法高亮和调试等功能。使用调试器逐步跟踪代码,查找和修复错误。集成 Git,进行版本控制。使用代码格式化工具,保持代码一致性。使用 Linting 工具,提前发现潜在问题。
 vs code 可以在 Windows 8 中运行吗
Apr 15, 2025 pm 07:24 PM
vs code 可以在 Windows 8 中运行吗
Apr 15, 2025 pm 07:24 PM
VS Code可以在Windows 8上运行,但体验可能不佳。首先确保系统已更新到最新补丁,然后下载与系统架构匹配的VS Code安装包,按照提示安装。安装后,注意某些扩展程序可能与Windows 8不兼容,需要寻找替代扩展或在虚拟机中使用更新的Windows系统。安装必要的扩展,检查是否正常工作。尽管VS Code在Windows 8上可行,但建议升级到更新的Windows系统以获得更好的开发体验和安全保障。
 vscode怎么在终端运行程序
Apr 15, 2025 pm 06:42 PM
vscode怎么在终端运行程序
Apr 15, 2025 pm 06:42 PM
在 VS Code 中,可以通过以下步骤在终端运行程序:准备代码和打开集成终端确保代码目录与终端工作目录一致根据编程语言选择运行命令(如 Python 的 python your_file_name.py)检查是否成功运行并解决错误利用调试器提升调试效率
 PHP和Python:深入了解他们的历史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他们的历史
Apr 18, 2025 am 12:25 AM
PHP起源于1994年,由RasmusLerdorf开发,最初用于跟踪网站访问者,逐渐演变为服务器端脚本语言,广泛应用于网页开发。Python由GuidovanRossum于1980年代末开发,1991年首次发布,强调代码可读性和简洁性,适用于科学计算、数据分析等领域。
